 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuadrotor Navigation using Reinforcement Learning with Privileged Information
Sep 09, 2025This paper presents a reinforcement learning-based quadrotor navigation method that leverages efficient differentiable simulation, novel loss functions, and privileged information to navigate around large obstacles. Prior learning-based methods perform well in scenes that exhibit narrow obstacles, but struggle when the goal location is blocked by large walls or terrain. In contrast, the proposed method utilizes time-of-arrival (ToA) maps as privileged information and a yaw alignment loss to guide the robot around large obstacles. The policy is evaluated in photo-realistic simulation environments containing large obstacles, sharp corners, and dead-ends. Our approach achieves an 86% success rate and outperforms baseline strategies by 34%. We deploy the policy onboard a custom quadrotor in outdoor cluttered environments both during the day and night. The policy is validated across 20 flights, covering 589 meters without collisions at speeds up to 4 m/s.
uLayout: Unified Room Layout Estimation for Perspective and Panoramic Images
Mar 27, 2025We present uLayout, a unified model for estimating room layout geometries from both perspective and panoramic images, whereas traditional solutions require different model designs for each image type. The key idea of our solution is to unify both domains into the equirectangular projection, particularly, allocating perspective images into the most suitable latitude coordinate to effectively exploit both domains seamlessly. To address the Field-of-View (FoV) difference between the input domains, we design uLayout with a shared feature extractor with an extra 1D-Convolution layer to condition each domain input differently. This conditioning allows us to efficiently formulate a column-wise feature regression problem regardless of the FoV input. This simple yet effective approach achieves competitive performance with current state-of-the-art solutions and shows for the first time a single end-to-end model for both domains. Extensive experiments in the real-world datasets, LSUN, Matterport3D, PanoContext, and Stanford 2D-3D evidence the contribution of our approach. Code is available at https://github.com/JonathanLee112/uLayout.
Dexterous Manipulation of Deformable Objects via Pneumatic Gripping: Lifting by One End
Jan 09, 2025Manipulating deformable objects in robotic cells is often costly and not widely accessible. However, the use of localized pneumatic gripping systems can enhance accessibility. Current methods that use pneumatic grippers to handle deformable objects struggle with effective lifting. This paper introduces a method for the dexterous lifting of textile deformable objects from one edge, utilizing a previously developed gripper designed for flexible and porous materials. By precisely adjusting the orientation and position of the gripper during the lifting process, we were able to significantly reduce necessary gripping force and minimize object vibration caused by airflow. This method was tested and validated on four materials with varying mass, friction, and flexibility. The proposed approach facilitates the lifting of deformable objects from a conveyor or automated line, even when only one edge is accessible for grasping. Future work will involve integrating a vision system to optimize the manipulation of deformable objects with more complex shapes.
Rapid Quadrotor Navigation in Diverse Environments using an Onboard Depth Camera
Nov 07, 2024



Search and rescue environments exhibit challenging 3D geometry (e.g., confined spaces, rubble, and breakdown), which necessitates agile and maneuverable aerial robotic systems. Because these systems are size, weight, and power (SWaP) constrained, rapid navigation is essential for maximizing environment coverage. Onboard autonomy must be robust to prevent collisions, which may endanger rescuers and victims. Prior works have developed high-speed navigation solutions for autonomous aerial systems, but few have considered safety for search and rescue applications. These works have also not demonstrated their approaches in diverse environments. We bridge this gap in the state of the art by developing a reactive planner using forward-arc motion primitives, which leverages a history of RGB-D observations to safely maneuver in close proximity to obstacles. At every planning round, a safe stopping action is scheduled, which is executed if no feasible motion plan is found at the next planning round. The approach is evaluated in thousands of simulations and deployed in diverse environments, including caves and forests. The results demonstrate a 24% increase in success rate compared to state-of-the-art approaches.
Self-training Room Layout Estimation via Geometry-aware Ray-casting
Jul 21, 2024



In this paper, we introduce a novel geometry-aware self-training framework for room layout estimation models on unseen scenes with unlabeled data. Our approach utilizes a ray-casting formulation to aggregate multiple estimates from different viewing positions, enabling the computation of reliable pseudo-labels for self-training. In particular, our ray-casting approach enforces multi-view consistency along all ray directions and prioritizes spatial proximity to the camera view for geometry reasoning. As a result, our geometry-aware pseudo-labels effectively handle complex room geometries and occluded walls without relying on assumptions such as Manhattan World or planar room walls. Evaluation on publicly available datasets, including synthetic and real-world scenarios, demonstrates significant improvements in current state-of-the-art layout models without using any human annotation.
Mesoscale Traffic Forecasting for Real-Time Bottleneck and Shockwave Prediction
Feb 08, 2024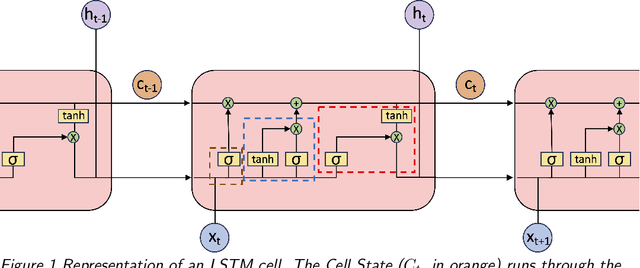
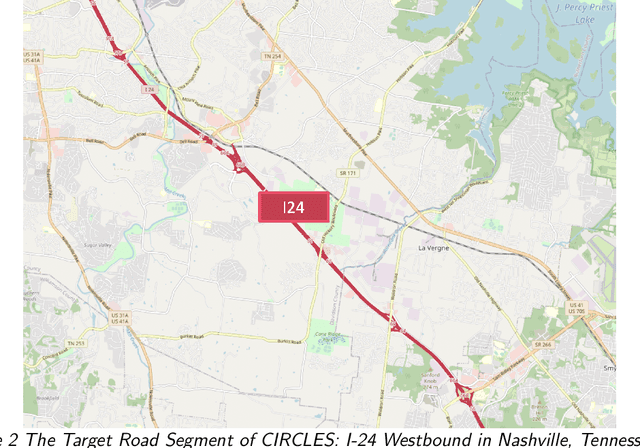
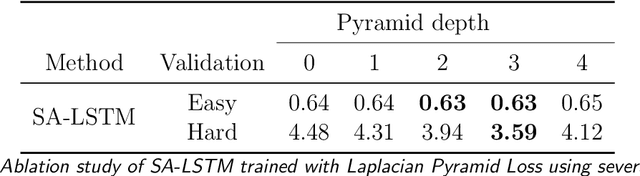
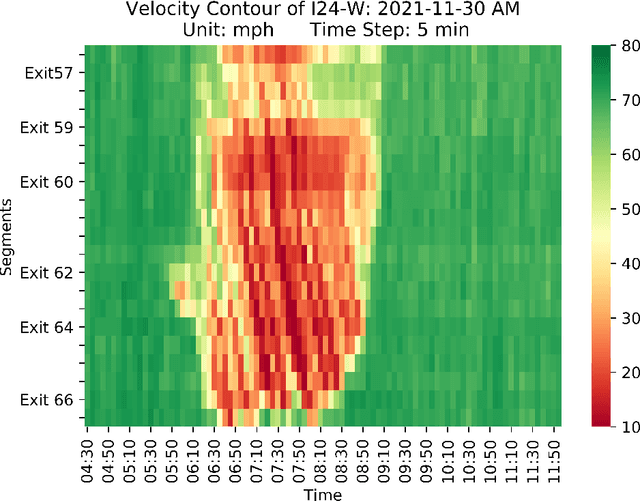
Accurate real-time traffic state forecasting plays a pivotal role in traffic control research. In particular, the CIRCLES consortium project necessitates predictive techniques to mitigate the impact of data source delays. After the success of the MegaVanderTest experiment, this paper aims at overcoming the current system limitations and develop a more suited approach to improve the real-time traffic state estimation for the next iterations of the experiment. In this paper, we introduce the SA-LSTM, a deep forecasting method integrating Self-Attention (SA) on the spatial dimension with Long Short-Term Memory (LSTM) yielding state-of-the-art results in real-time mesoscale traffic forecasting. We extend this approach to multi-step forecasting with the n-step SA-LSTM, which outperforms traditional multi-step forecasting methods in the trade-off between short-term and long-term predictions, all while operating in real-time.
Jais and Jais-chat: Arabic-Centric Foundation and Instruction-Tuned Open Generative Large Language Models
Aug 30, 2023
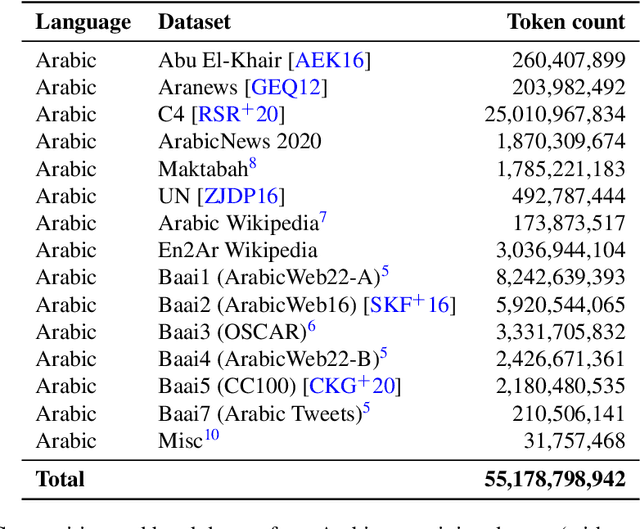
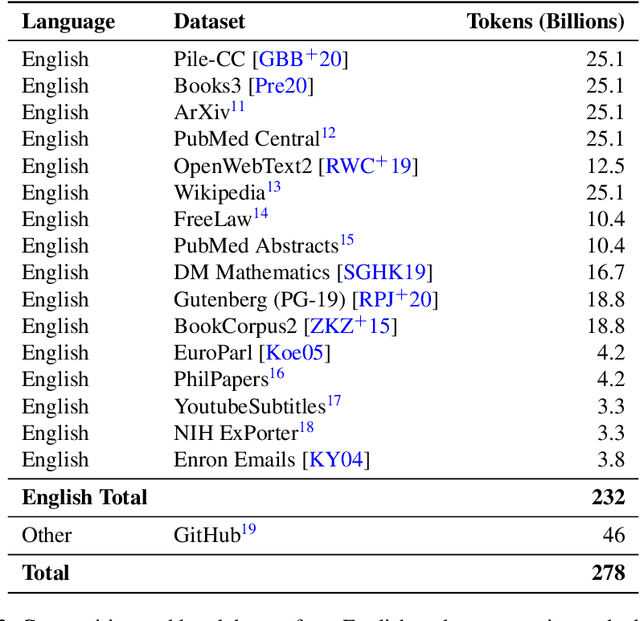
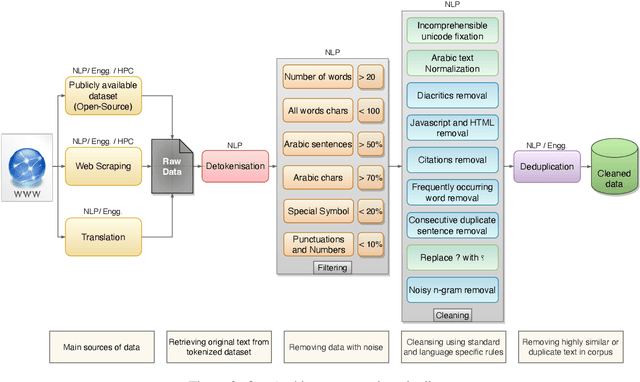
We introduce Jais and Jais-chat, new state-of-the-art Arabic-centric foundation and instruction-tuned open generative large language models (LLMs). The models are based on the GPT-3 decoder-only architecture and are pretrained on a mixture of Arabic and English texts, including source code in various programming languages. With 13 billion parameters, they demonstrate better knowledge and reasoning capabilities in Arabic than any existing open Arabic and multilingual models by a sizable margin, based on extensive evaluation. Moreover, the models are competitive in English compared to English-centric open models of similar size, despite being trained on much less English data. We provide a detailed description of the training, the tuning, the safety alignment, and the evaluation of the models. We release two open versions of the model -- the foundation Jais model, and an instruction-tuned Jais-chat variant -- with the aim of promoting research on Arabic LLMs. Available at https://huggingface.co/inception-mbzuai/jais-13b-chat
Dueling RL: Reinforcement Learning with Trajectory Preferences
Nov 08, 2021We consider the problem of preference based reinforcement learning (PbRL), where, unlike traditional reinforcement learning, an agent receives feedback only in terms of a 1 bit (0/1) preference over a trajectory pair instead of absolute rewards for them. The success of the traditional RL framework crucially relies on the underlying agent-reward model, which, however, depends on how accurately a system designer can express an appropriate reward function and often a non-trivial task. The main novelty of our framework is the ability to learn from preference-based trajectory feedback that eliminates the need to hand-craft numeric reward models. This paper sets up a formal framework for the PbRL problem with non-markovian rewards, where the trajectory preferences are encoded by a generalized linear model of dimension $d$. Assuming the transition model is known, we then propose an algorithm with almost optimal regret guarantee of $\tilde {\mathcal{O}}\left( SH d \log (T / \delta) \sqrt{T} \right)$. We further, extend the above algorithm to the case of unknown transition dynamics, and provide an algorithm with near optimal regret guarantee $\widetilde{\mathcal{O}}((\sqrt{d} + H^2 + |\mathcal{S}|)\sqrt{dT} +\sqrt{|\mathcal{S}||\mathcal{A}|TH} )$. To the best of our knowledge, our work is one of the first to give tight regret guarantees for preference based RL problems with trajectory preferences.
Design of Experiments for Stochastic Contextual Linear Bandits
Jul 22, 2021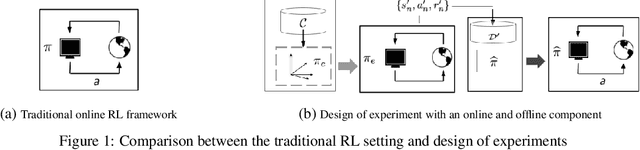
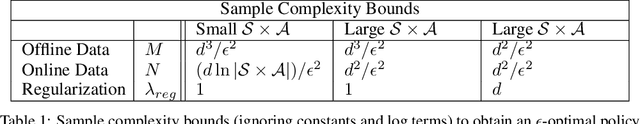
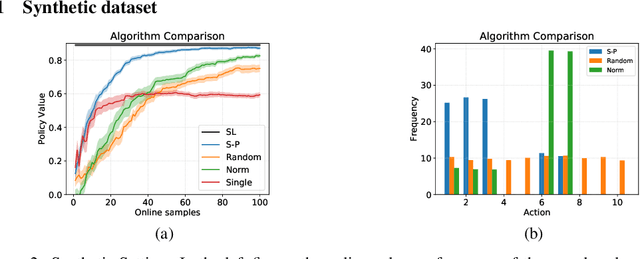
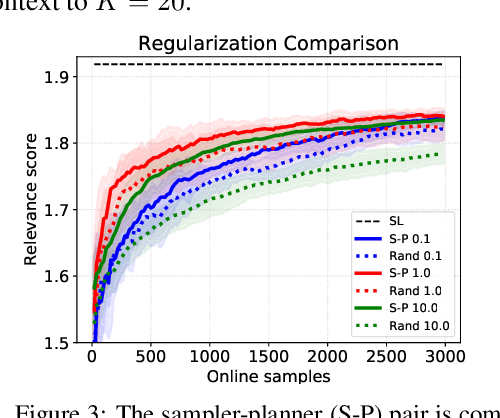
In the stochastic linear contextual bandit setting there exist several minimax procedures for exploration with policies that are reactive to the data being acquired. In practice, there can be a significant engineering overhead to deploy these algorithms, especially when the dataset is collected in a distributed fashion or when a human in the loop is needed to implement a different policy. Exploring with a single non-reactive policy is beneficial in such cases. Assuming some batch contexts are available, we design a single stochastic policy to collect a good dataset from which a near-optimal policy can be extracted. We present a theoretical analysis as well as numerical experiments on both synthetic and real-world datasets.
Near Optimal Policy Optimization via REPS
Mar 17, 2021Since its introduction a decade ago, \emph{relative entropy policy search} (REPS) has demonstrated successful policy learning on a number of simulated and real-world robotic domains, not to mention providing algorithmic components used by many recently proposed reinforcement learning (RL) algorithms. While REPS is commonly known in the community, there exist no guarantees on its performance when using stochastic and gradient-based solvers. In this paper we aim to fill this gap by providing guarantees and convergence rates for the sub-optimality of a policy learned using first-order optimization methods applied to the REPS objective. We first consider the setting in which we are given access to exact gradients and demonstrate how near-optimality of the objective translates to near-optimality of the policy. We then consider the practical setting of stochastic gradients, and introduce a technique that uses \emph{generative} access to the underlying Markov decision process to compute parameter updates that maintain favorable convergence to the optimal regularized policy.