 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMesoscale Traffic Forecasting for Real-Time Bottleneck and Shockwave Prediction
Feb 08, 2024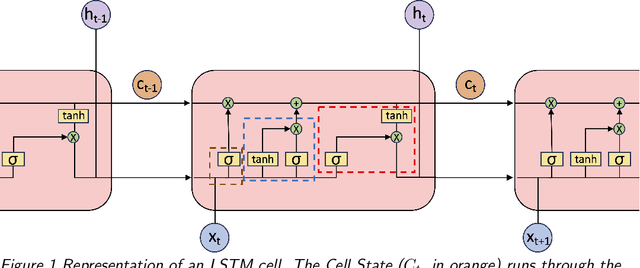
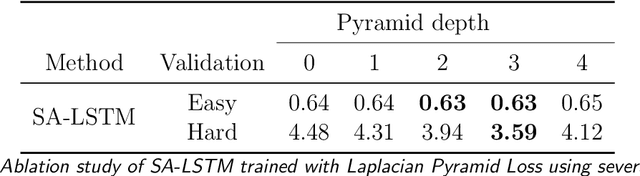
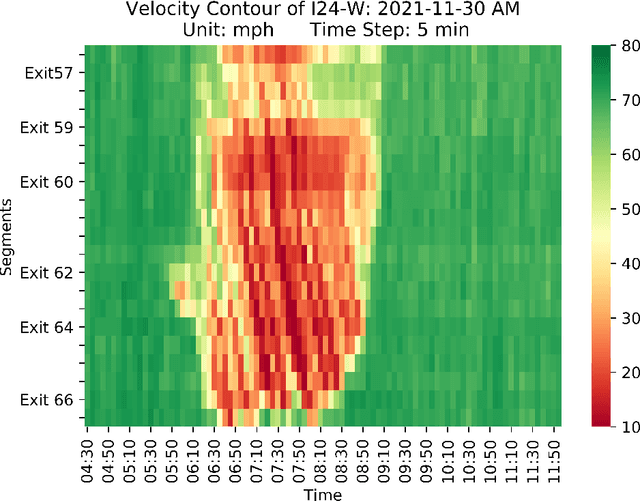
Accurate real-time traffic state forecasting plays a pivotal role in traffic control research. In particular, the CIRCLES consortium project necessitates predictive techniques to mitigate the impact of data source delays. After the success of the MegaVanderTest experiment, this paper aims at overcoming the current system limitations and develop a more suited approach to improve the real-time traffic state estimation for the next iterations of the experiment. In this paper, we introduce the SA-LSTM, a deep forecasting method integrating Self-Attention (SA) on the spatial dimension with Long Short-Term Memory (LSTM) yielding state-of-the-art results in real-time mesoscale traffic forecasting. We extend this approach to multi-step forecasting with the n-step SA-LSTM, which outperforms traditional multi-step forecasting methods in the trade-off between short-term and long-term predictions, all while operating in real-time.
MBAPPE: MCTS-Built-Around Prediction for Planning Explicitly
Sep 15, 2023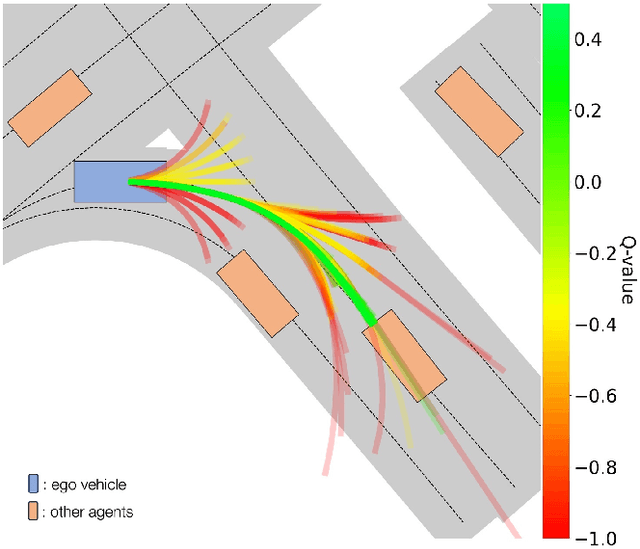
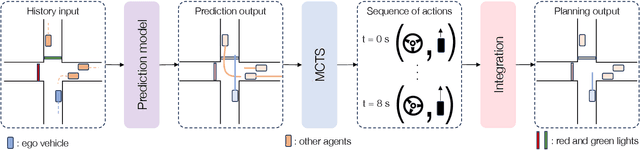
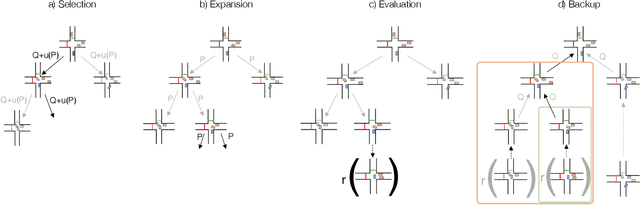
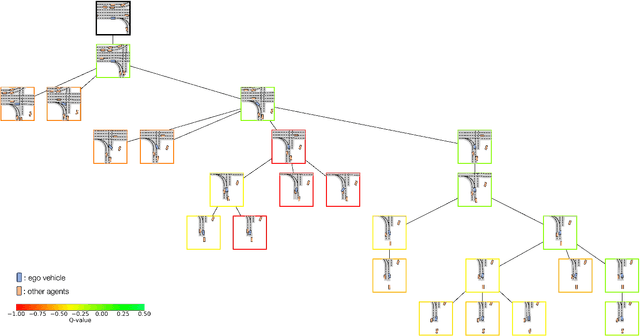
We present MBAPPE, a novel approach to motion planning for autonomous driving combining tree search with a partially-learned model of the environment. Leveraging the inherent explainable exploration and optimization capabilities of the Monte-Carlo Search Tree (MCTS), our method addresses complex decision-making in a dynamic environment. We propose a framework that combines MCTS with supervised learning, enabling the autonomous vehicle to effectively navigate through diverse scenarios. Experimental results demonstrate the effectiveness and adaptability of our approach, showcasing improved real-time decision-making and collision avoidance. This paper contributes to the field by providing a robust solution for motion planning in autonomous driving systems, enhancing their explainability and reliability.
GRI: General Reinforced Imitation and its Application to Vision-Based Autonomous Driving
Nov 16, 2021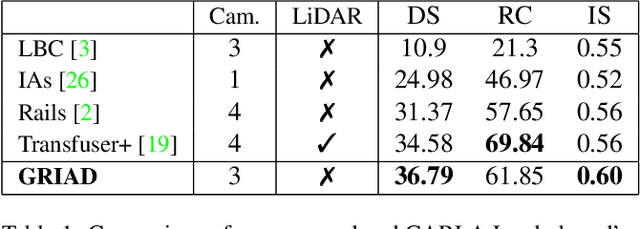
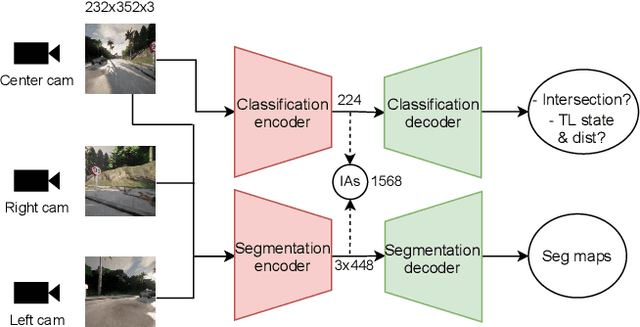
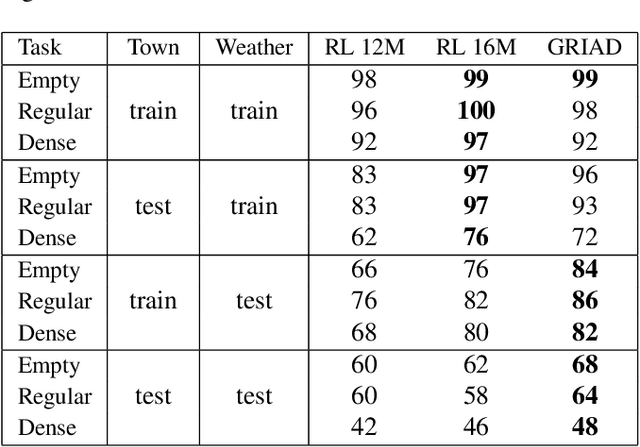
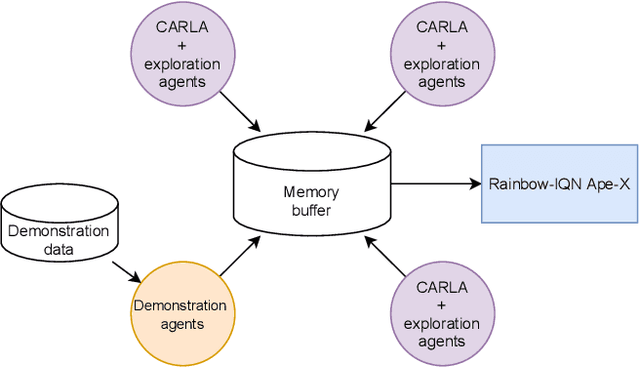
Deep reinforcement learning (DRL) has been demonstrated to be effective for several complex decision-making applications such as autonomous driving and robotics. However, DRL is notoriously limited by its high sample complexity and its lack of stability. Prior knowledge, e.g. as expert demonstrations, is often available but challenging to leverage to mitigate these issues. In this paper, we propose General Reinforced Imitation (GRI), a novel method which combines benefits from exploration and expert data and is straightforward to implement over any off-policy RL algorithm. We make one simplifying hypothesis: expert demonstrations can be seen as perfect data whose underlying policy gets a constant high reward. Based on this assumption, GRI introduces the notion of offline demonstration agents. This agent sends expert data which are processed both concurrently and indistinguishably with the experiences coming from the online RL exploration agent. We show that our approach enables major improvements on vision-based autonomous driving in urban environments. We further validate the GRI method on Mujoco continuous control tasks with different off-policy RL algorithms. Our method ranked first on the CARLA Leaderboard and outperforms World on Rails, the previous state-of-the-art, by 17%.
End-to-End Model-Free Reinforcement Learning for Urban Driving using Implicit Affordances
Nov 25, 2019

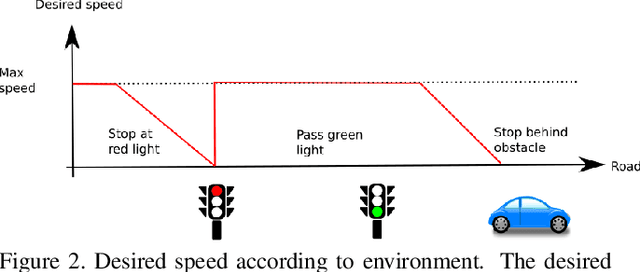

Reinforcement Learning (RL) aims at learning an optimal behavior policy from its own experiments and not rule-based control methods. However, there is no RL algorithm yet capable of handling a task as difficult as urban driving. We present a novel technique, coined implicit affordances, to effectively leverage RL for urban driving thus including lane keeping, pedestrians and vehicles avoidance, and traffic light detection. To our knowledge we are the first to present a successful RL agent handling such a complex task especially regarding the traffic light detection. We demonstrate the effectiveness of our method by being one of the top teams of the camera only track of the CARLA challenge.
Is Deep Reinforcement Learning Really Superhuman on Atari?
Aug 22, 2019
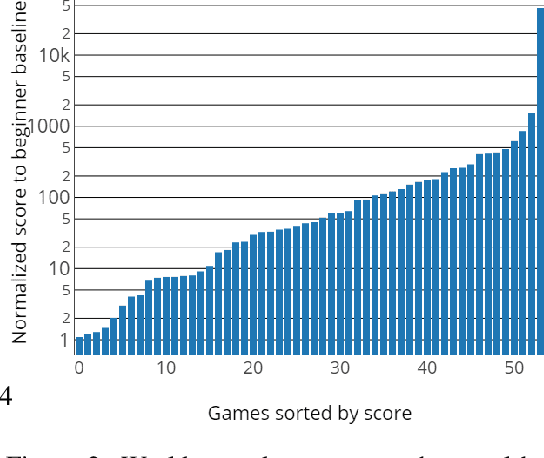


Consistent and reproducible evaluation of Deep Reinforcement Learning (DRL) is not straightforward. In the Arcade Learning Environment (ALE), small changes in environment parameters such as stochasticity or the maximum allowed play time can lead to very different performance. In this work, we discuss the difficulties of comparing different agents trained on ALE. In order to take a step further towards reproducible and comparable DRL, we introduce SABER, a Standardized Atari BEnchmark for general Reinforcement learning algorithms. Our methodology extends previous recommendations and contains a complete set of environment parameters as well as train and test procedures. We then use SABER to evaluate the current state of the art, Rainbow. Furthermore, we introduce a human world records baseline, and argue that previous claims of expert or superhuman performance of DRL might not be accurate. Finally, we propose Rainbow-IQN by extending Rainbow with Implicit Quantile Networks (IQN) leading to new state-of-the-art performance. Source code is available for reproducibility.
End-to-End Race Driving with Deep Reinforcement Learning
Aug 31, 2018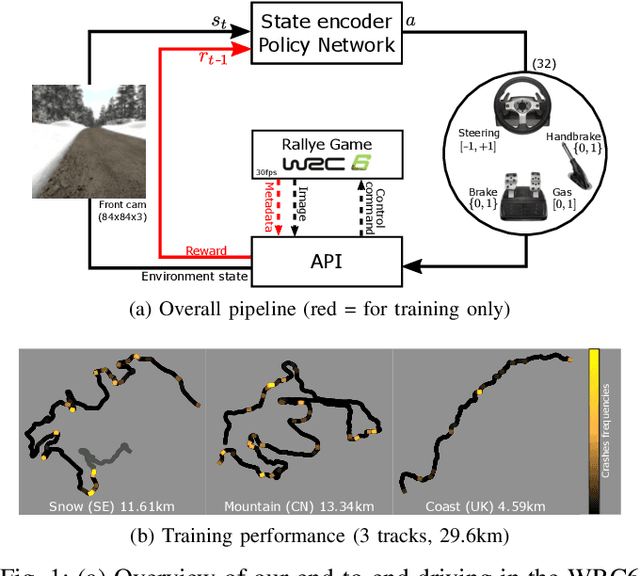
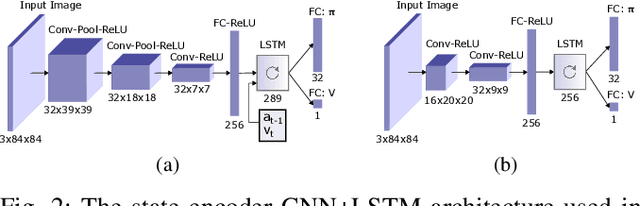
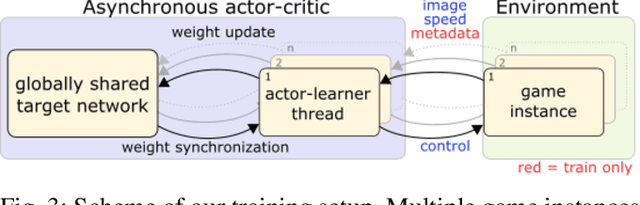
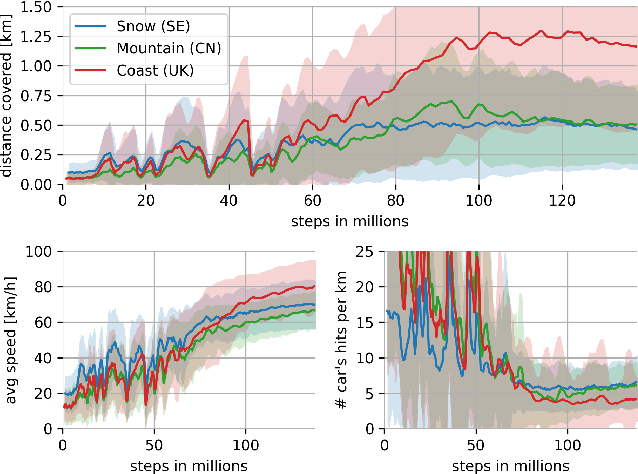
We present research using the latest reinforcement learning algorithm for end-to-end driving without any mediated perception (object recognition, scene understanding). The newly proposed reward and learning strategies lead together to faster convergence and more robust driving using only RGB image from a forward facing camera. An Asynchronous Actor Critic (A3C) framework is used to learn the car control in a physically and graphically realistic rally game, with the agents evolving simultaneously on tracks with a variety of road structures (turns, hills), graphics (seasons, location) and physics (road adherence). A thorough evaluation is conducted and generalization is proven on unseen tracks and using legal speed limits. Open loop tests on real sequences of images show some domain adaption capability of our method.
End to End Vehicle Lateral Control Using a Single Fisheye Camera
Aug 20, 2018
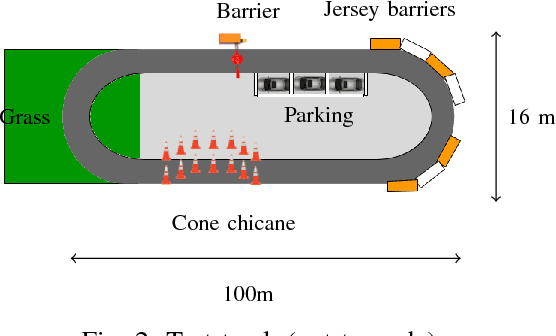


Convolutional neural networks are commonly used to control the steering angle for autonomous cars. Most of the time, multiple long range cameras are used to generate lateral failure cases. In this paper we present a novel model to generate this data and label augmentation using only one short range fisheye camera. We present our simulator and how it can be used as a consistent metric for lateral end-to-end control evaluation. Experiments are conducted on a custom dataset corresponding to more than 10000 km and 200 hours of open road driving. Finally we evaluate this model on real world driving scenarios, open road and a custom test track with challenging obstacle avoidance and sharp turns. In our simulator based on real-world videos, the final model was capable of more than 99% autonomy on urban road