 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edgenvblox: GPU-Accelerated Incremental Signed Distance Field Mapping
Nov 01, 2023Dense, volumetric maps are essential for safe robot navigation through cluttered spaces, as well as interaction with the environment. For latency and robustness, it is best if these can be computed on-board on computationally-constrained hardware from camera or LiDAR-based sensors. Previous works leave a gap between CPU-based systems for robotic mapping, which due to computation constraints limit map resolution or scale, and GPU-based reconstruction systems which omit features that are critical to robotic path planning. We introduce a library, nvblox, that aims to fill this gap, by GPU-accelerating robotic volumetric mapping, and which is optimized for embedded GPUs. nvblox delivers a significant performance improvement over the state of the art, achieving up to a 177x speed-up in surface reconstruction, and up to a 31x improvement in distance field computation, and is available open-source.
VRUNet: Multi-Task Learning Model for Intent Prediction of Vulnerable Road Users
Jul 10, 2020
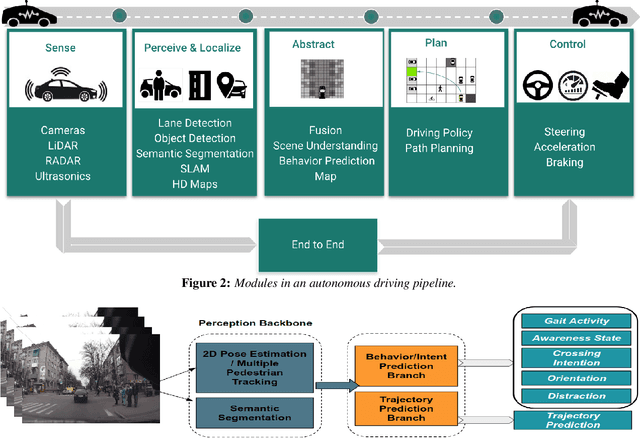
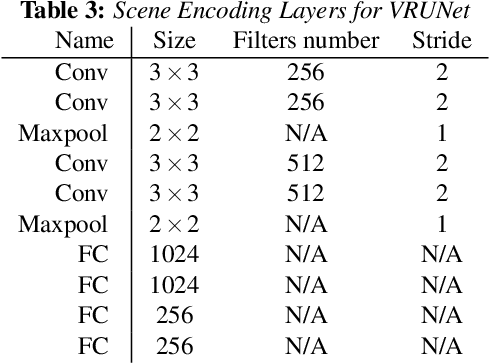

Advanced perception and path planning are at the core for any self-driving vehicle. Autonomous vehicles need to understand the scene and intentions of other road users for safe motion planning. For urban use cases it is very important to perceive and predict the intentions of pedestrians, cyclists, scooters, etc., classified as vulnerable road users (VRU). Intent is a combination of pedestrian activities and long term trajectories defining their future motion. In this paper we propose a multi-task learning model to predict pedestrian actions, crossing intent and forecast their future path from video sequences. We have trained the model on naturalistic driving open-source JAAD dataset, which is rich in behavioral annotations and real world scenarios. Experimental results show state-of-the-art performance on JAAD dataset and how we can benefit from jointly learning and predicting actions and trajectories using 2D human pose features and scene context.
PLOP: Probabilistic poLynomial Objects trajectory Planning for autonomous driving
Mar 09, 2020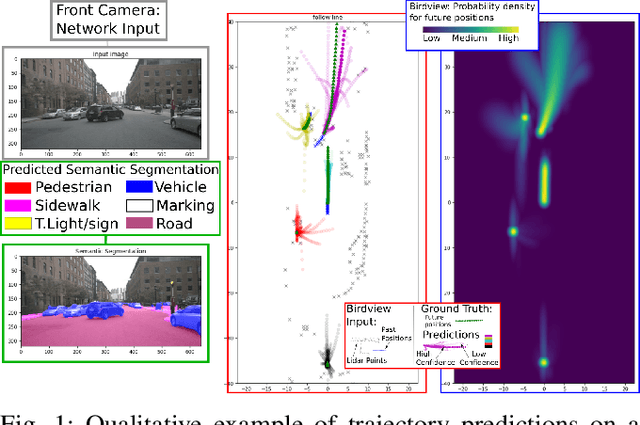
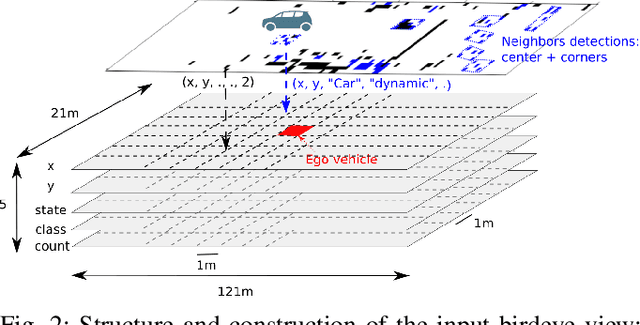
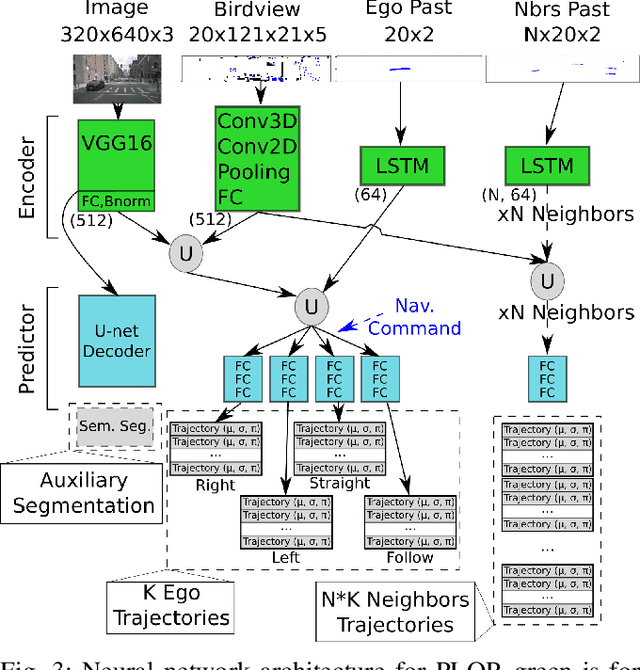
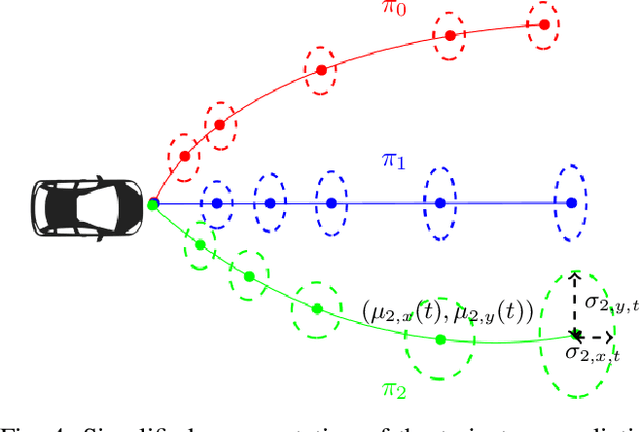
To navigate safely in an urban environment, an autonomous vehicle (ego vehicle) needs to understand and anticipate its surroundings, in particular the behavior of other road users (neighbors). However, multiple choices are often acceptable (e.g. turn right or left, or different ways of avoiding an obstacle). We focus here on predicting multiple feasible future trajectories both for the ego vehicle and neighbors through a probabilistic framework. We use a conditional imitation learning algorithm, conditioned by a navigation command for the ego vehicle (e.g. "turn right"). It takes as input the ego car front camera image, a Lidar point cloud in a bird-eye view grid and present and past objects detections to output ego vehicle and neighbors possible trajectories but also semantic segmentation as an auxiliary loss. We evaluate our method on the publicly available dataset nuScenes, showing state-of-the-art performance and investigating the impact of our architecture choices.
End-to-End Model-Free Reinforcement Learning for Urban Driving using Implicit Affordances
Nov 25, 2019

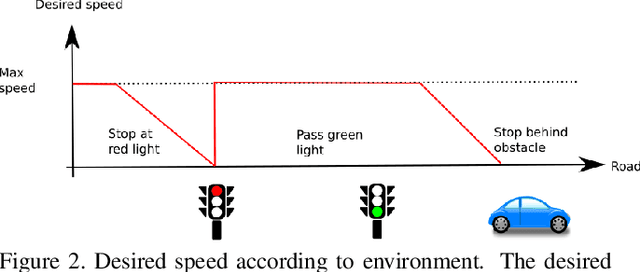

Reinforcement Learning (RL) aims at learning an optimal behavior policy from its own experiments and not rule-based control methods. However, there is no RL algorithm yet capable of handling a task as difficult as urban driving. We present a novel technique, coined implicit affordances, to effectively leverage RL for urban driving thus including lane keeping, pedestrians and vehicles avoidance, and traffic light detection. To our knowledge we are the first to present a successful RL agent handling such a complex task especially regarding the traffic light detection. We demonstrate the effectiveness of our method by being one of the top teams of the camera only track of the CARLA challenge.
Conditional Vehicle Trajectories Prediction in CARLA Urban Environment
Sep 02, 2019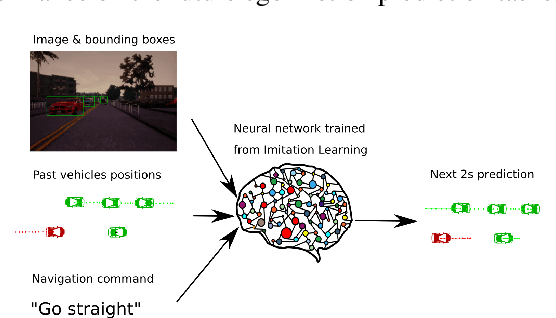
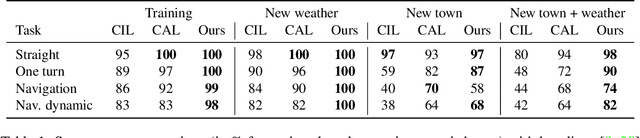
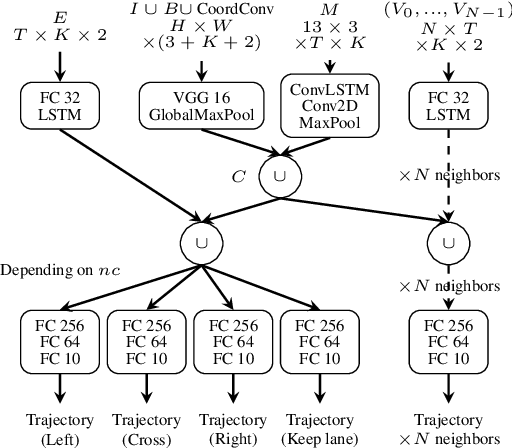
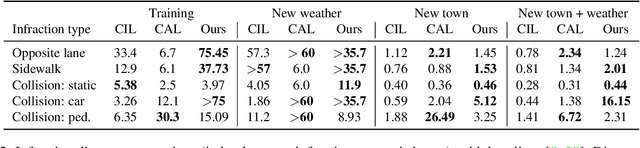
Imitation learning is becoming more and more successful for autonomous driving. End-to-end (raw signal to command) performs well on relatively simple tasks (lane keeping and navigation). Mid-to-mid (environment abstraction to mid-level trajectory representation) or direct perception (raw signal to performance) approaches strive to handle more complex, real life environment and tasks (e.g. complex intersection). In this work, we show that complex urban situations can be handled with raw signal input and mid-level representation. We build a hybrid end-to-mid approach predicting trajectories for neighbor vehicles and for the ego vehicle with a conditional navigation goal. We propose an original architecture inspired from social pooling LSTM taking low and mid level data as input and producing trajectories as polynomials of time. We introduce a label augmentation mechanism to get the level of generalization that is required to control a vehicle. The performance is evaluated on CARLA 0.8 benchmark, showing significant improvements over previously published state of the art.
Is Deep Reinforcement Learning Really Superhuman on Atari?
Aug 22, 2019
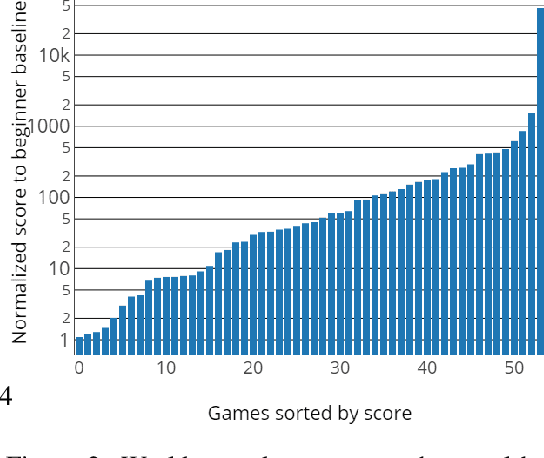


Consistent and reproducible evaluation of Deep Reinforcement Learning (DRL) is not straightforward. In the Arcade Learning Environment (ALE), small changes in environment parameters such as stochasticity or the maximum allowed play time can lead to very different performance. In this work, we discuss the difficulties of comparing different agents trained on ALE. In order to take a step further towards reproducible and comparable DRL, we introduce SABER, a Standardized Atari BEnchmark for general Reinforcement learning algorithms. Our methodology extends previous recommendations and contains a complete set of environment parameters as well as train and test procedures. We then use SABER to evaluate the current state of the art, Rainbow. Furthermore, we introduce a human world records baseline, and argue that previous claims of expert or superhuman performance of DRL might not be accurate. Finally, we propose Rainbow-IQN by extending Rainbow with Implicit Quantile Networks (IQN) leading to new state-of-the-art performance. Source code is available for reproducibility.
Imitation Learning for End to End Vehicle Longitudinal Control with Forward Camera
Dec 14, 2018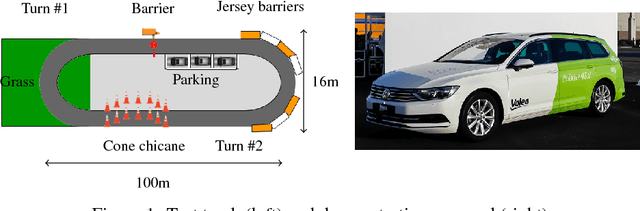
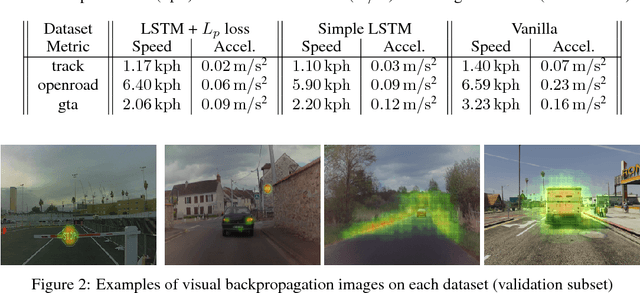
In this paper we present a complete study of an end-to-end imitation learning system for speed control of a real car, based on a neural network with a Long Short Term Memory (LSTM). To achieve robustness and generalization from expert demonstrations, we propose data augmentation and label augmentation that are relevant for imitation learning in longitudinal control context. Based on front camera image only, our system is able to correctly control the speed of a car in simulation environment, and in a real car on a challenging test track. The system also shows promising results in open road context.
Sparse and Dense Data with CNNs: Depth Completion and Semantic Segmentation
Aug 31, 2018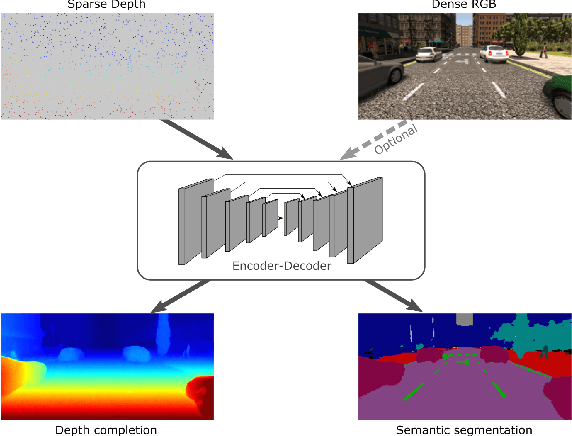
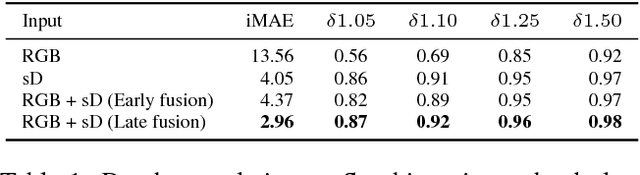


Convolutional neural networks are designed for dense data, but vision data is often sparse (stereo depth, point clouds, pen stroke, etc.). We present a method to handle sparse depth data with optional dense RGB, and accomplish depth completion and semantic segmentation changing only the last layer. Our proposal efficiently learns sparse features without the need of an additional validity mask. We show how to ensure network robustness to varying input sparsities. Our method even works with densities as low as 0.8% (8 layer lidar), and outperforms all published state-of-the-art on the Kitti depth completion benchmark.
End to End Vehicle Lateral Control Using a Single Fisheye Camera
Aug 20, 2018
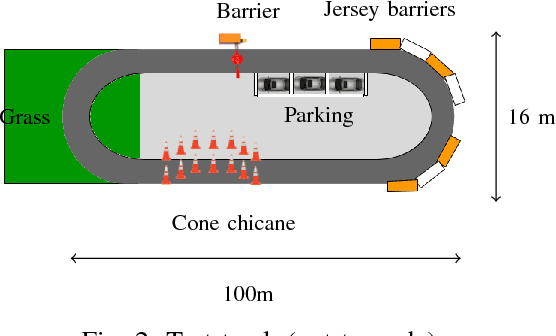


Convolutional neural networks are commonly used to control the steering angle for autonomous cars. Most of the time, multiple long range cameras are used to generate lateral failure cases. In this paper we present a novel model to generate this data and label augmentation using only one short range fisheye camera. We present our simulator and how it can be used as a consistent metric for lateral end-to-end control evaluation. Experiments are conducted on a custom dataset corresponding to more than 10000 km and 200 hours of open road driving. Finally we evaluate this model on real world driving scenarios, open road and a custom test track with challenging obstacle avoidance and sharp turns. In our simulator based on real-world videos, the final model was capable of more than 99% autonomy on urban road