 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeToFu: Visual Tokens Reduction via Fusion for Multi-modal, Multi-patch, Multi-image Task
Mar 06, 2025



Large Multimodal Models (LMMs) are powerful tools that are capable of reasoning and understanding multimodal information beyond text and language. Despite their entrenched impact, the development of LMMs is hindered by the higher computational requirements compared to their unimodal counterparts. One of the main causes of this is the large amount of tokens needed to encode the visual input, which is especially evident for multi-image multimodal tasks. Recent approaches to reduce visual tokens depend on the visual encoder architecture, require fine-tuning the LLM to maintain the performance, and only consider single-image scenarios. To address these limitations, we propose ToFu, a visual encoder-agnostic, training-free Token Fusion strategy that combines redundant visual tokens of LMMs for high-resolution, multi-image, tasks. The core intuition behind our method is straightforward yet effective: preserve distinctive tokens while combining similar ones. We achieve this by sequentially examining visual tokens and deciding whether to merge them with others or keep them as separate entities. We validate our approach on the well-established LLaVA-Interleave Bench, which covers challenging multi-image tasks. In addition, we push to the extreme our method by testing it on a newly-created benchmark, ComPairs, focused on multi-image comparisons where a larger amount of images and visual tokens are inputted to the LMMs. Our extensive analysis, considering several LMM architectures, demonstrates the benefits of our approach both in terms of efficiency and performance gain.
UniCoRN: Unified Commented Retrieval Network with LMMs
Feb 12, 2025Multimodal retrieval methods have limitations in handling complex, compositional queries that require reasoning about the visual content of both the query and the retrieved entities. On the other hand, Large Multimodal Models (LMMs) can answer with language to more complex visual questions, but without the inherent ability to retrieve relevant entities to support their answers. We aim to address these limitations with UniCoRN, a Unified Commented Retrieval Network that combines the strengths of composed multimodal retrieval methods and generative language approaches, going beyond Retrieval-Augmented Generation (RAG). We introduce an entity adapter module to inject the retrieved multimodal entities back into the LMM, so it can attend to them while generating answers and comments. By keeping the base LMM frozen, UniCoRN preserves its original capabilities while being able to perform both retrieval and text generation tasks under a single integrated framework. To assess these new abilities, we introduce the Commented Retrieval task (CoR) and a corresponding dataset, with the goal of retrieving an image that accurately answers a given question and generate an additional textual response that provides further clarification and details about the visual information. We demonstrate the effectiveness of UniCoRN on several datasets showing improvements of +4.5% recall over the state of the art for composed multimodal retrieval and of +14.9% METEOR / +18.4% BEM over RAG for commenting in CoR.
LatteCLIP: Unsupervised CLIP Fine-Tuning via LMM-Synthetic Texts
Oct 10, 2024
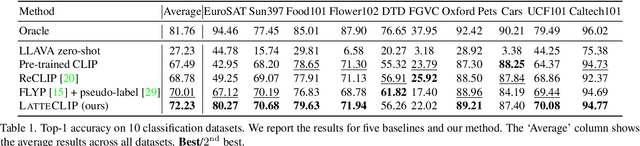

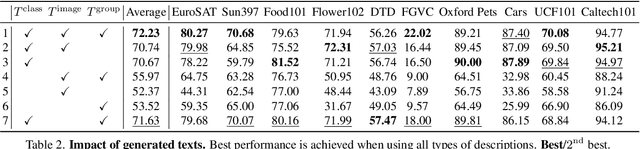
Large-scale vision-language pre-trained (VLP) models (e.g., CLIP) are renowned for their versatility, as they can be applied to diverse applications in a zero-shot setup. However, when these models are used in specific domains, their performance often falls short due to domain gaps or the under-representation of these domains in the training data. While fine-tuning VLP models on custom datasets with human-annotated labels can address this issue, annotating even a small-scale dataset (e.g., 100k samples) can be an expensive endeavor, often requiring expert annotators if the task is complex. To address these challenges, we propose LatteCLIP, an unsupervised method for fine-tuning CLIP models on classification with known class names in custom domains, without relying on human annotations. Our method leverages Large Multimodal Models (LMMs) to generate expressive textual descriptions for both individual images and groups of images. These provide additional contextual information to guide the fine-tuning process in the custom domains. Since LMM-generated descriptions are prone to hallucination or missing details, we introduce a novel strategy to distill only the useful information and stabilize the training. Specifically, we learn rich per-class prototype representations from noisy generated texts and dual pseudo-labels. Our experiments on 10 domain-specific datasets show that LatteCLIP outperforms pre-trained zero-shot methods by an average improvement of +4.74 points in top-1 accuracy and other state-of-the-art unsupervised methods by +3.45 points.
Cross-modal Learning for Domain Adaptation in 3D Semantic Segmentation
Jan 18, 2021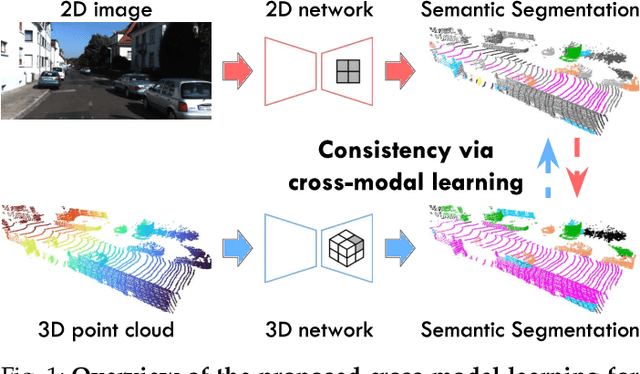
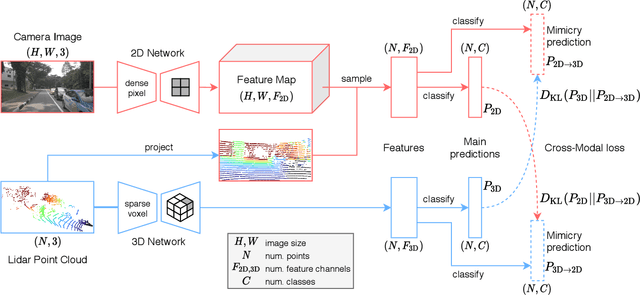
Domain adaptation is an important task to enable learning when labels are scarce. While most works focus only on the image modality, there are many important multi-modal datasets. In order to leverage multi-modality for domain adaptation, we propose cross-modal learning, where we enforce consistency between the predictions of two modalities via mutual mimicking. We constrain our network to make correct predictions on labeled data and consistent predictions across modalities on unlabeled target-domain data. Experiments in unsupervised and semi-supervised domain adaptation settings prove the effectiveness of this novel domain adaptation strategy. Specifically, we evaluate on the task of 3D semantic segmentation using the image and point cloud modality. We leverage recent autonomous driving datasets to produce a wide variety of domain adaptation scenarios including changes in scene layout, lighting, sensor setup and weather, as well as the synthetic-to-real setup. Our method significantly improves over previous uni-modal adaptation baselines on all adaption scenarios. Code will be made available.
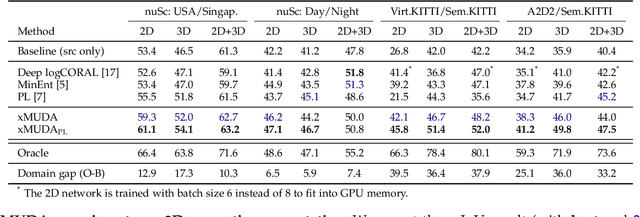
xMUDA: Cross-Modal Unsupervised Domain Adaptation for 3D Semantic Segmentation
Nov 28, 2019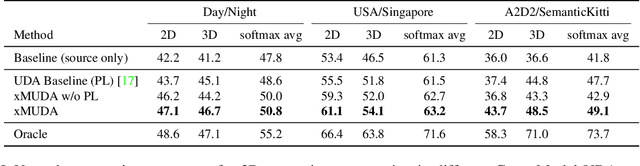
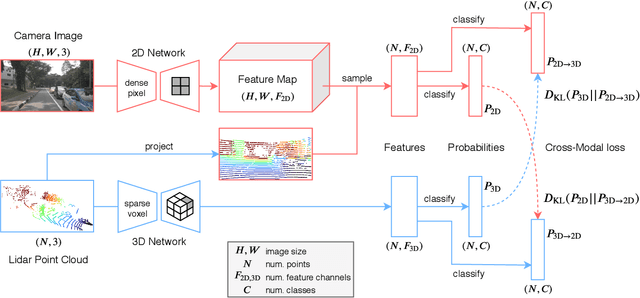

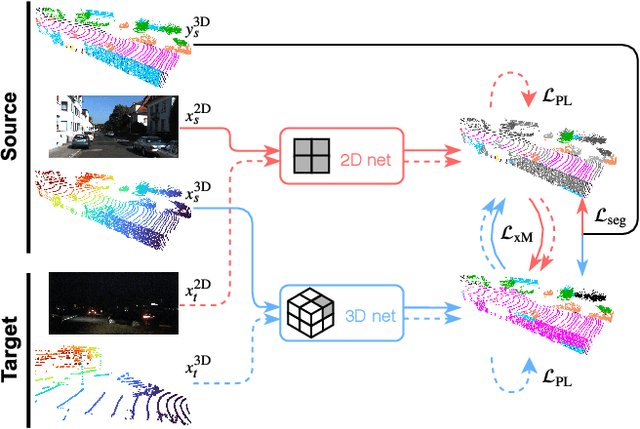
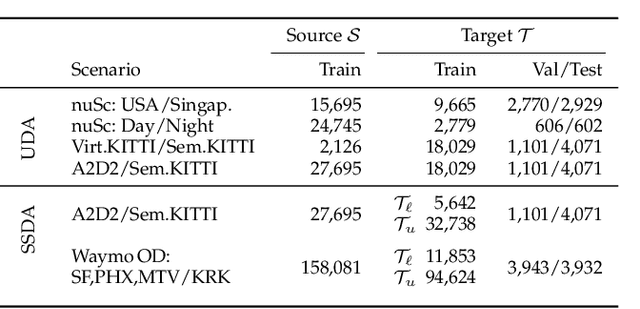
Unsupervised Domain Adaptation (UDA) is crucial to tackle the lack of annotations in a new domain. There are many multi-modal datasets, but most UDA approaches are uni-modal. In this work, we explore how to learn from multi-modality and propose cross-modal UDA (xMUDA) where we assume the presence of 2D images and 3D point clouds for 3D semantic segmentation. This is challenging as the two input spaces are heterogeneous and can be impacted differently by domain shift. In xMUDA, modalities learn from each other through mutual mimicking, disentangled from the segmentation objective, to prevent the stronger modality from adopting false predictions from the weaker one. We evaluate on new UDA scenarios including day-to-night, country-to-country and dataset-to-dataset, leveraging recent autonomous driving datasets. xMUDA brings large improvements over uni-modal UDA on all tested scenarios, and is complementary to state-of-the-art UDA techniques.
Multi-view PointNet for 3D Scene Understanding
Sep 30, 2019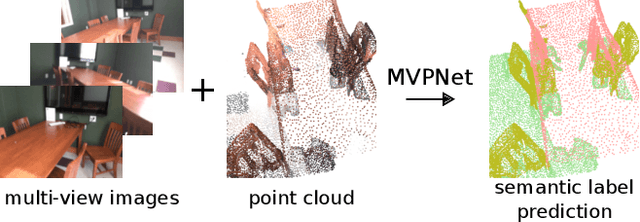



Fusion of 2D images and 3D point clouds is important because information from dense images can enhance sparse point clouds. However, fusion is challenging because 2D and 3D data live in different spaces. In this work, we propose MVPNet (Multi-View PointNet), where we aggregate 2D multi-view image features into 3D point clouds, and then use a point based network to fuse the features in 3D canonical space to predict 3D semantic labels. To this end, we introduce view selection along with a 2D-3D feature aggregation module. Extensive experiments show the benefit of leveraging features from dense images and reveal superior robustness to varying point cloud density compared to 3D-only methods. On the ScanNetV2 benchmark, our MVPNet significantly outperforms prior point cloud based approaches on the task of 3D Semantic Segmentation. It is much faster to train than the large networks of the sparse voxel approach. We provide solid ablation studies to ease the future design of 2D-3D fusion methods and their extension to other tasks, as we showcase for 3D instance segmentation.
End-to-End Race Driving with Deep Reinforcement Learning
Aug 31, 2018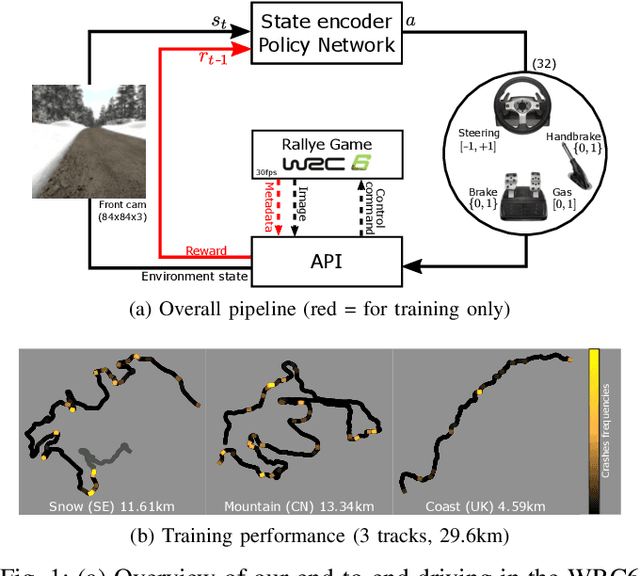
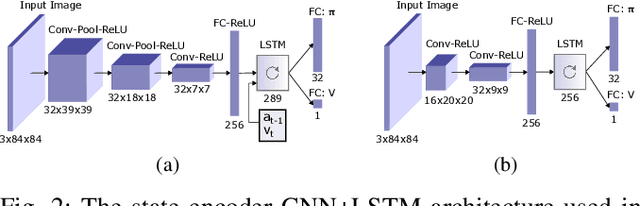
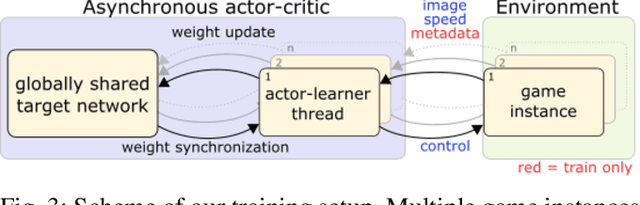
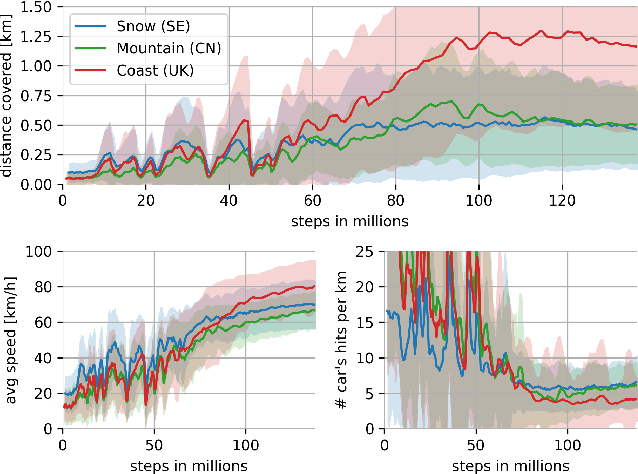
We present research using the latest reinforcement learning algorithm for end-to-end driving without any mediated perception (object recognition, scene understanding). The newly proposed reward and learning strategies lead together to faster convergence and more robust driving using only RGB image from a forward facing camera. An Asynchronous Actor Critic (A3C) framework is used to learn the car control in a physically and graphically realistic rally game, with the agents evolving simultaneously on tracks with a variety of road structures (turns, hills), graphics (seasons, location) and physics (road adherence). A thorough evaluation is conducted and generalization is proven on unseen tracks and using legal speed limits. Open loop tests on real sequences of images show some domain adaption capability of our method.
Sparse and Dense Data with CNNs: Depth Completion and Semantic Segmentation
Aug 31, 2018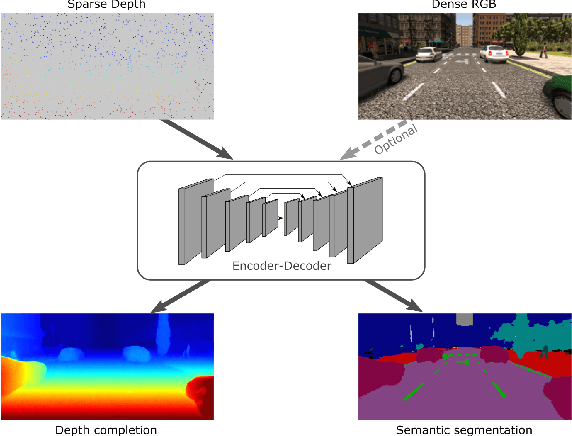
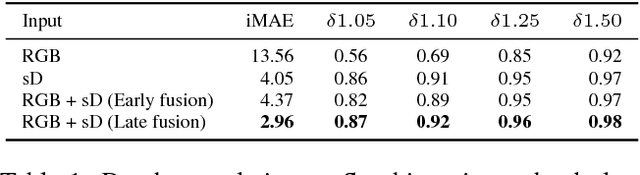


Convolutional neural networks are designed for dense data, but vision data is often sparse (stereo depth, point clouds, pen stroke, etc.). We present a method to handle sparse depth data with optional dense RGB, and accomplish depth completion and semantic segmentation changing only the last layer. Our proposal efficiently learns sparse features without the need of an additional validity mask. We show how to ensure network robustness to varying input sparsities. Our method even works with densities as low as 0.8% (8 layer lidar), and outperforms all published state-of-the-art on the Kitti depth completion benchmark.