 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRestoring Exploration after Post-Training: Latent Exploration Decoding for Large Reasoning Models
Feb 02, 2026Large Reasoning Models (LRMs) have recently achieved strong mathematical and code reasoning performance through Reinforcement Learning (RL) post-training. However, we show that modern reasoning post-training induces an unintended exploration collapse: temperature-based sampling no longer increases pass@$n$ accuracy. Empirically, the final-layer posterior of post-trained LRMs exhibit sharply reduced entropy, while the entropy of intermediate layers remains relatively high. Motivated by this entropy asymmetry, we propose Latent Exploration Decoding (LED), a depth-conditioned decoding strategy. LED aggregates intermediate posteriors via cumulative sum and selects depth configurations with maximal entropy as exploration candidates. Without additional training or parameters, LED consistently improves pass@1 and pass@16 accuracy by 0.61 and 1.03 percentage points across multiple reasoning benchmarks and models. Project page: https://GitHub.com/Xiaomi-Research/LED.
A Unified Masked Jigsaw Puzzle Framework for Vision and Language Models
Jan 17, 2026In federated learning, Transformer, as a popular architecture, faces critical challenges in defending against gradient attacks and improving model performance in both Computer Vision (CV) and Natural Language Processing (NLP) tasks. It has been revealed that the gradient of Position Embeddings (PEs) in Transformer contains sufficient information, which can be used to reconstruct the input data. To mitigate this issue, we introduce a Masked Jigsaw Puzzle (MJP) framework. MJP starts with random token shuffling to break the token order, and then a learnable \textit{unknown (unk)} position embedding is used to mask out the PEs of the shuffled tokens. In this manner, the local spatial information which is encoded in the position embeddings is disrupted, and the models are forced to learn feature representations that are less reliant on the local spatial information. Notably, with the careful use of MJP, we can not only improve models' robustness against gradient attacks, but also boost their performance in both vision and text application scenarios, such as classification for images (\textit{e.g.,} ImageNet-1K) and sentiment analysis for text (\textit{e.g.,} Yelp and Amazon). Experimental results suggest that MJP is a unified framework for different Transformer-based models in both vision and language tasks. Code is publicly available via https://github.com/ywxsuperstar/transformerattack
CounterVid: Counterfactual Video Generation for Mitigating Action and Temporal Hallucinations in Video-Language Models
Jan 08, 2026Video-language models (VLMs) achieve strong multimodal understanding but remain prone to hallucinations, especially when reasoning about actions and temporal order. Existing mitigation strategies, such as textual filtering or random video perturbations, often fail to address the root cause: over-reliance on language priors rather than fine-grained visual dynamics. We propose a scalable framework for counterfactual video generation that synthesizes videos differing only in actions or temporal structure while preserving scene context. Our pipeline combines multimodal LLMs for action proposal and editing guidance with diffusion-based image and video models to generate semantic hard negatives at scale. Using this framework, we build CounterVid, a synthetic dataset of ~26k preference pairs targeting action recognition and temporal reasoning. We further introduce MixDPO, a unified Direct Preference Optimization approach that jointly leverages textual and visual preferences. Fine-tuning Qwen2.5-VL with MixDPO yields consistent improvements, notably in temporal ordering, and transfers effectively to standard video hallucination benchmarks. Code and models will be made publicly available.
Seeing Beyond Words: Self-Supervised Visual Learning for Multimodal Large Language Models
Dec 17, 2025Multimodal Large Language Models (MLLMs) have recently demonstrated impressive capabilities in connecting vision and language, yet their proficiency in fundamental visual reasoning tasks remains limited. This limitation can be attributed to the fact that MLLMs learn visual understanding primarily from textual descriptions, which constitute a subjective and inherently incomplete supervisory signal. Furthermore, the modest scale of multimodal instruction tuning compared to massive text-only pre-training leads MLLMs to overfit language priors while overlooking visual details. To address these issues, we introduce JARVIS, a JEPA-inspired framework for self-supervised visual enhancement in MLLMs. Specifically, we integrate the I-JEPA learning paradigm into the standard vision-language alignment pipeline of MLLMs training. Our approach leverages frozen vision foundation models as context and target encoders, while training the predictor, implemented as the early layers of an LLM, to learn structural and semantic regularities from images without relying exclusively on language supervision. Extensive experiments on standard MLLM benchmarks show that JARVIS consistently improves performance on vision-centric benchmarks across different LLM families, without degrading multimodal reasoning abilities. Our source code is publicly available at: https://github.com/aimagelab/JARVIS.
Recurrence Meets Transformers for Universal Multimodal Retrieval
Sep 10, 2025With the rapid advancement of multimodal retrieval and its application in LLMs and multimodal LLMs, increasingly complex retrieval tasks have emerged. Existing methods predominantly rely on task-specific fine-tuning of vision-language models and are limited to single-modality queries or documents. In this paper, we propose ReT-2, a unified retrieval model that supports multimodal queries, composed of both images and text, and searches across multimodal document collections where text and images coexist. ReT-2 leverages multi-layer representations and a recurrent Transformer architecture with LSTM-inspired gating mechanisms to dynamically integrate information across layers and modalities, capturing fine-grained visual and textual details. We evaluate ReT-2 on the challenging M2KR and M-BEIR benchmarks across different retrieval configurations. Results demonstrate that ReT-2 consistently achieves state-of-the-art performance across diverse settings, while offering faster inference and reduced memory usage compared to prior approaches. When integrated into retrieval-augmented generation pipelines, ReT-2 also improves downstream performance on Encyclopedic-VQA and InfoSeek datasets. Our source code and trained models are publicly available at: https://github.com/aimagelab/ReT-2
Dual Orthogonal Guidance for Robust Diffusion-based Handwritten Text Generation
Aug 23, 2025Diffusion-based Handwritten Text Generation (HTG) approaches achieve impressive results on frequent, in-vocabulary words observed at training time and on regular styles. However, they are prone to memorizing training samples and often struggle with style variability and generation clarity. In particular, standard diffusion models tend to produce artifacts or distortions that negatively affect the readability of the generated text, especially when the style is hard to produce. To tackle these issues, we propose a novel sampling guidance strategy, Dual Orthogonal Guidance (DOG), that leverages an orthogonal projection of a negatively perturbed prompt onto the original positive prompt. This approach helps steer the generation away from artifacts while maintaining the intended content, and encourages more diverse, yet plausible, outputs. Unlike standard Classifier-Free Guidance (CFG), which relies on unconditional predictions and produces noise at high guidance scales, DOG introduces a more stable, disentangled direction in the latent space. To control the strength of the guidance across the denoising process, we apply a triangular schedule: weak at the start and end of denoising, when the process is most sensitive, and strongest in the middle steps. Experimental results on the state-of-the-art DiffusionPen and One-DM demonstrate that DOG improves both content clarity and style variability, even for out-of-vocabulary words and challenging writing styles.
Quo Vadis Handwritten Text Generation for Handwritten Text Recognition?
Aug 13, 2025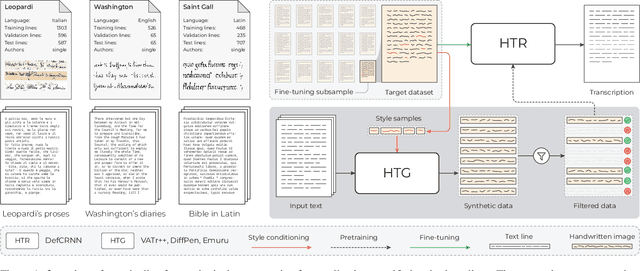
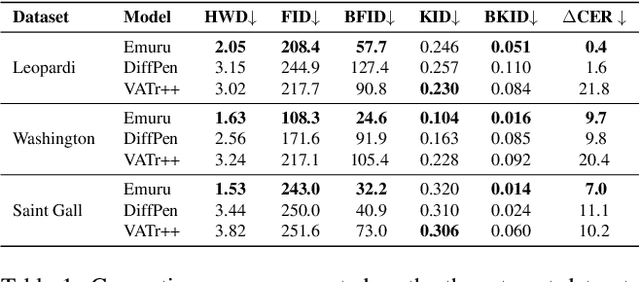

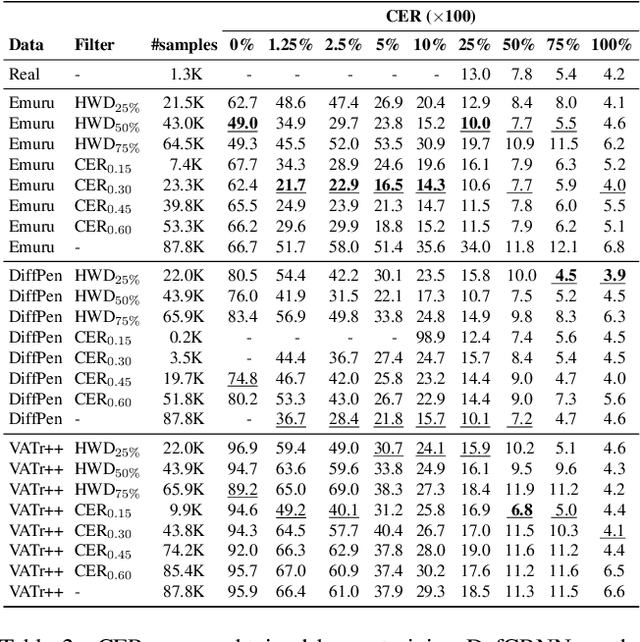
The digitization of historical manuscripts presents significant challenges for Handwritten Text Recognition (HTR) systems, particularly when dealing with small, author-specific collections that diverge from the training data distributions. Handwritten Text Generation (HTG) techniques, which generate synthetic data tailored to specific handwriting styles, offer a promising solution to address these challenges. However, the effectiveness of various HTG models in enhancing HTR performance, especially in low-resource transcription settings, has not been thoroughly evaluated. In this work, we systematically compare three state-of-the-art styled HTG models (representing the generative adversarial, diffusion, and autoregressive paradigms for HTG) to assess their impact on HTR fine-tuning. We analyze how visual and linguistic characteristics of synthetic data influence fine-tuning outcomes and provide quantitative guidelines for selecting the most effective HTG model. The results of our analysis provide insights into the current capabilities of HTG methods and highlight key areas for further improvement in their application to low-resource HTR.
BRUM: Robust 3D Vehicle Reconstruction from 360 Sparse Images
Jul 16, 2025Accurate 3D reconstruction of vehicles is vital for applications such as vehicle inspection, predictive maintenance, and urban planning. Existing methods like Neural Radiance Fields and Gaussian Splatting have shown impressive results but remain limited by their reliance on dense input views, which hinders real-world applicability. This paper addresses the challenge of reconstructing vehicles from sparse-view inputs, leveraging depth maps and a robust pose estimation architecture to synthesize novel views and augment training data. Specifically, we enhance Gaussian Splatting by integrating a selective photometric loss, applied only to high-confidence pixels, and replacing standard Structure-from-Motion pipelines with the DUSt3R architecture to improve camera pose estimation. Furthermore, we present a novel dataset featuring both synthetic and real-world public transportation vehicles, enabling extensive evaluation of our approach. Experimental results demonstrate state-of-the-art performance across multiple benchmarks, showcasing the method's ability to achieve high-quality reconstructions even under constrained input conditions.
RAID: A Dataset for Testing the Adversarial Robustness of AI-Generated Image Detectors
Jun 09, 2025AI-generated images have reached a quality level at which humans are incapable of reliably distinguishing them from real images. To counteract the inherent risk of fraud and disinformation, the detection of AI-generated images is a pressing challenge and an active research topic. While many of the presented methods claim to achieve high detection accuracy, they are usually evaluated under idealized conditions. In particular, the adversarial robustness is often neglected, potentially due to a lack of awareness or the substantial effort required to conduct a comprehensive robustness analysis. In this work, we tackle this problem by providing a simpler means to assess the robustness of AI-generated image detectors. We present RAID (Robust evaluation of AI-generated image Detectors), a dataset of 72k diverse and highly transferable adversarial examples. The dataset is created by running attacks against an ensemble of seven state-of-the-art detectors and images generated by four different text-to-image models. Extensive experiments show that our methodology generates adversarial images that transfer with a high success rate to unseen detectors, which can be used to quickly provide an approximate yet still reliable estimate of a detector's adversarial robustness. Our findings indicate that current state-of-the-art AI-generated image detectors can be easily deceived by adversarial examples, highlighting the critical need for the development of more robust methods. We release our dataset at https://huggingface.co/datasets/aimagelab/RAID and evaluation code at https://github.com/pralab/RAID.
Inverse Virtual Try-On: Generating Multi-Category Product-Style Images from Clothed Individuals
May 27, 2025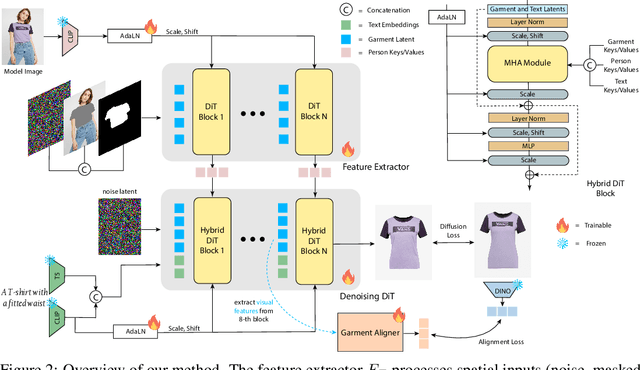
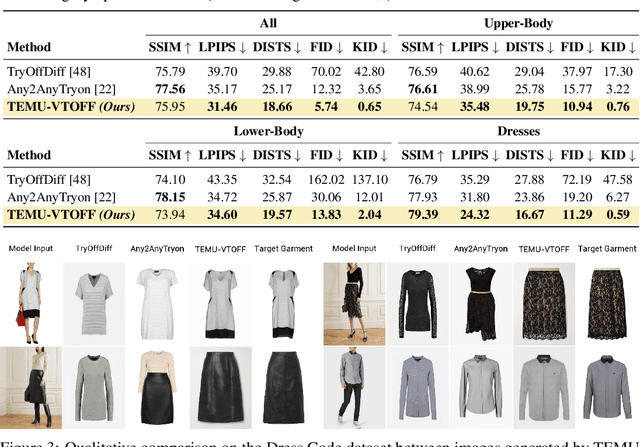
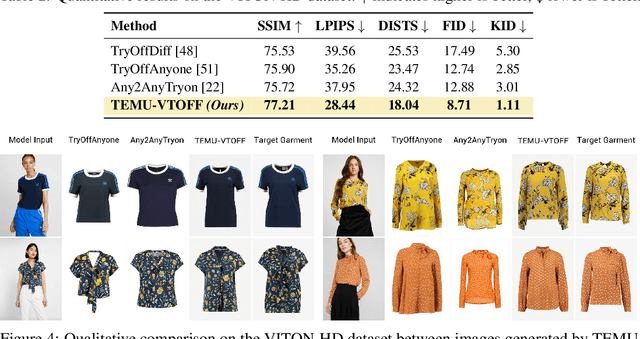
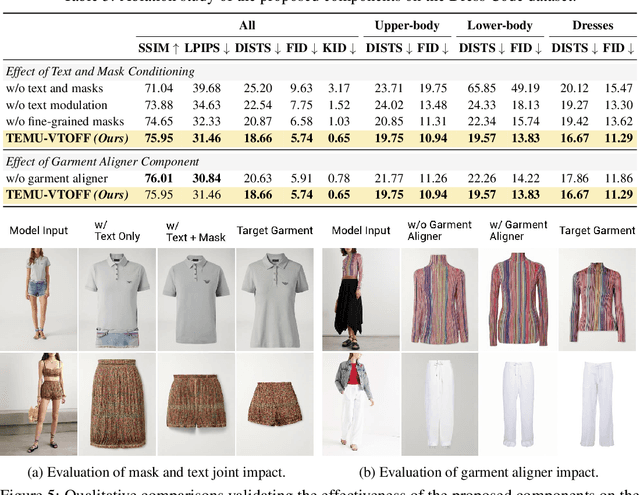
While virtual try-on (VTON) systems aim to render a garment onto a target person image, this paper tackles the novel task of virtual try-off (VTOFF), which addresses the inverse problem: generating standardized product images of garments from real-world photos of clothed individuals. Unlike VTON, which must resolve diverse pose and style variations, VTOFF benefits from a consistent and well-defined output format -- typically a flat, lay-down-style representation of the garment -- making it a promising tool for data generation and dataset enhancement. However, existing VTOFF approaches face two major limitations: (i) difficulty in disentangling garment features from occlusions and complex poses, often leading to visual artifacts, and (ii) restricted applicability to single-category garments (e.g., upper-body clothes only), limiting generalization. To address these challenges, we present Text-Enhanced MUlti-category Virtual Try-Off (TEMU-VTOFF), a novel architecture featuring a dual DiT-based backbone with a modified multimodal attention mechanism for robust garment feature extraction. Our architecture is designed to receive garment information from multiple modalities like images, text, and masks to work in a multi-category setting. Finally, we propose an additional alignment module to further refine the generated visual details. Experiments on VITON-HD and Dress Code datasets show that TEMU-VTOFF sets a new state-of-the-art on the VTOFF task, significantly improving both visual quality and fidelity to the target garments.