 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDitHub: A Modular Framework for Incremental Open-Vocabulary Object Detection
Mar 12, 2025Open-Vocabulary object detectors can recognize a wide range of categories using simple textual prompts. However, improving their ability to detect rare classes or specialize in certain domains remains a challenge. While most recent methods rely on a single set of model weights for adaptation, we take a different approach by using modular deep learning. We introduce DitHub, a framework designed to create and manage a library of efficient adaptation modules. Inspired by Version Control Systems, DitHub organizes expert modules like branches that can be fetched and merged as needed. This modular approach enables a detailed study of how adaptation modules combine, making it the first method to explore this aspect in Object Detection. Our approach achieves state-of-the-art performance on the ODinW-13 benchmark and ODinW-O, a newly introduced benchmark designed to evaluate how well models adapt when previously seen classes reappear. For more details, visit our project page: https://aimagelab.github.io/DitHub/
Is Multiple Object Tracking a Matter of Specialization?
Nov 01, 2024



End-to-end transformer-based trackers have achieved remarkable performance on most human-related datasets. However, training these trackers in heterogeneous scenarios poses significant challenges, including negative interference - where the model learns conflicting scene-specific parameters - and limited domain generalization, which often necessitates expensive fine-tuning to adapt the models to new domains. In response to these challenges, we introduce Parameter-efficient Scenario-specific Tracking Architecture (PASTA), a novel framework that combines Parameter-Efficient Fine-Tuning (PEFT) and Modular Deep Learning (MDL). Specifically, we define key scenario attributes (e.g, camera-viewpoint, lighting condition) and train specialized PEFT modules for each attribute. These expert modules are combined in parameter space, enabling systematic generalization to new domains without increasing inference time. Extensive experiments on MOTSynth, along with zero-shot evaluations on MOT17 and PersonPath22 demonstrate that a neural tracker built from carefully selected modules surpasses its monolithic counterpart. We release models and code.
DistFormer: Enhancing Local and Global Features for Monocular Per-Object Distance Estimation
Jan 06, 2024Accurate per-object distance estimation is crucial in safety-critical applications such as autonomous driving, surveillance, and robotics. Existing approaches rely on two scales: local information (i.e., the bounding box proportions) or global information, which encodes the semantics of the scene as well as the spatial relations with neighboring objects. However, these approaches may struggle with long-range objects and in the presence of strong occlusions or unusual visual patterns. In this respect, our work aims to strengthen both local and global cues. Our architecture -- named DistFormer -- builds upon three major components acting jointly: i) a robust context encoder extracting fine-grained per-object representations; ii) a masked encoder-decoder module exploiting self-supervision to promote the learning of useful per-object features; iii) a global refinement module that aggregates object representations and computes a joint, spatially-consistent estimation. To evaluate the effectiveness of DistFormer, we conduct experiments on the standard KITTI dataset and the large-scale NuScenes and MOTSynth datasets. Such datasets cover various indoor/outdoor environments, changing weather conditions, appearances, and camera viewpoints. Our comprehensive analysis shows that DistFormer outperforms existing methods. Moreover, we further delve into its generalization capabilities, showing its regularization benefits in zero-shot synth-to-real transfer.
TrackFlow: Multi-Object Tracking with Normalizing Flows
Aug 22, 2023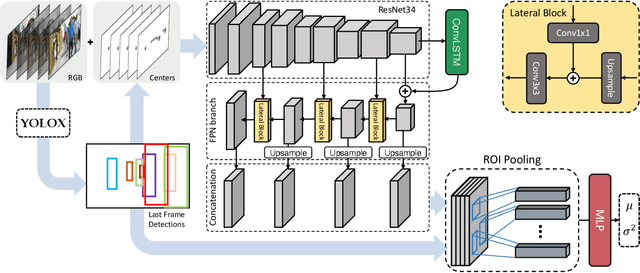


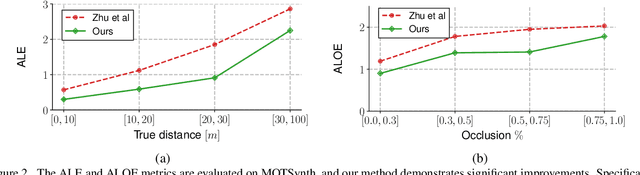
The field of multi-object tracking has recently seen a renewed interest in the good old schema of tracking-by-detection, as its simplicity and strong priors spare it from the complex design and painful babysitting of tracking-by-attention approaches. In view of this, we aim at extending tracking-by-detection to multi-modal settings, where a comprehensive cost has to be computed from heterogeneous information e.g., 2D motion cues, visual appearance, and pose estimates. More precisely, we follow a case study where a rough estimate of 3D information is also available and must be merged with other traditional metrics (e.g., the IoU). To achieve that, recent approaches resort to either simple rules or complex heuristics to balance the contribution of each cost. However, i) they require careful tuning of tailored hyperparameters on a hold-out set, and ii) they imply these costs to be independent, which does not hold in reality. We address these issues by building upon an elegant probabilistic formulation, which considers the cost of a candidate association as the negative log-likelihood yielded by a deep density estimator, trained to model the conditional joint probability distribution of correct associations. Our experiments, conducted on both simulated and real benchmarks, show that our approach consistently enhances the performance of several tracking-by-detection algorithms.