 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTransporting Task Vectors across Different Architectures without Training
Feb 13, 2026Adapting large pre-trained models to downstream tasks often produces task-specific parameter updates that are expensive to relearn for every model variant. While recent work has shown that such updates can be transferred between models with identical architectures, transferring them across models of different widths remains largely unexplored. In this work, we introduce Theseus, a training-free method for transporting task-specific updates across heterogeneous models. Rather than matching parameters directly, we characterize a task update by the functional effect it induces on intermediate representations. We formalize task-vector transport as a functional matching problem on observed activations and show that, after aligning representation spaces via orthogonal Procrustes analysis, it admits a stable closed-form solution that preserves the geometry of the update. We evaluate Theseus on vision and language models across different widths, showing consistent improvements over strong baselines without additional training or backpropagation. Our results show that task updates can be meaningfully transferred across architectures when task identity is defined functionally rather than parametrically.
Is Multiple Object Tracking a Matter of Specialization?
Nov 01, 2024



End-to-end transformer-based trackers have achieved remarkable performance on most human-related datasets. However, training these trackers in heterogeneous scenarios poses significant challenges, including negative interference - where the model learns conflicting scene-specific parameters - and limited domain generalization, which often necessitates expensive fine-tuning to adapt the models to new domains. In response to these challenges, we introduce Parameter-efficient Scenario-specific Tracking Architecture (PASTA), a novel framework that combines Parameter-Efficient Fine-Tuning (PEFT) and Modular Deep Learning (MDL). Specifically, we define key scenario attributes (e.g, camera-viewpoint, lighting condition) and train specialized PEFT modules for each attribute. These expert modules are combined in parameter space, enabling systematic generalization to new domains without increasing inference time. Extensive experiments on MOTSynth, along with zero-shot evaluations on MOT17 and PersonPath22 demonstrate that a neural tracker built from carefully selected modules surpasses its monolithic counterpart. We release models and code.
CLIP with Generative Latent Replay: a Strong Baseline for Incremental Learning
Jul 22, 2024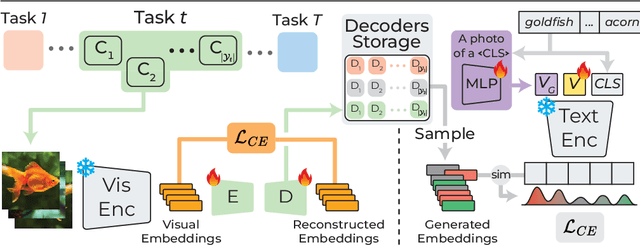
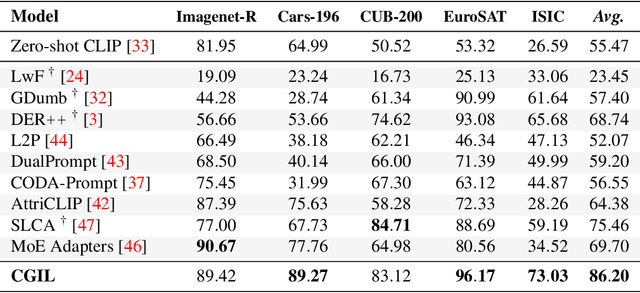
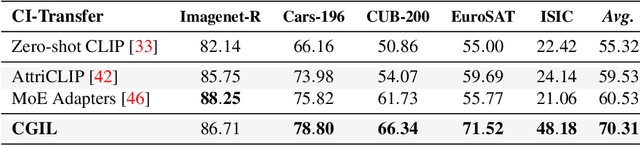
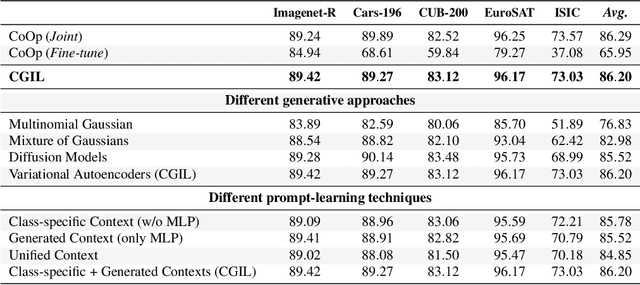
With the emergence of Transformers and Vision-Language Models (VLMs) such as CLIP, large pre-trained models have become a common strategy to enhance performance in Continual Learning scenarios. This led to the development of numerous prompting strategies to effectively fine-tune transformer-based models without succumbing to catastrophic forgetting. However, these methods struggle to specialize the model on domains significantly deviating from the pre-training and preserving its zero-shot capabilities. In this work, we propose Continual Generative training for Incremental prompt-Learning, a novel approach to mitigate forgetting while adapting a VLM, which exploits generative replay to align prompts to tasks. We also introduce a new metric to evaluate zero-shot capabilities within CL benchmarks. Through extensive experiments on different domains, we demonstrate the effectiveness of our framework in adapting to new tasks while improving zero-shot capabilities. Further analysis reveals that our approach can bridge the gap with joint prompt tuning. The codebase is available at https://github.com/aimagelab/mammoth.
Mask and Compress: Efficient Skeleton-based Action Recognition in Continual Learning
Jul 01, 2024



The use of skeletal data allows deep learning models to perform action recognition efficiently and effectively. Herein, we believe that exploring this problem within the context of Continual Learning is crucial. While numerous studies focus on skeleton-based action recognition from a traditional offline perspective, only a handful venture into online approaches. In this respect, we introduce CHARON (Continual Human Action Recognition On skeletoNs), which maintains consistent performance while operating within an efficient framework. Through techniques like uniform sampling, interpolation, and a memory-efficient training stage based on masking, we achieve improved recognition accuracy while minimizing computational overhead. Our experiments on Split NTU-60 and the proposed Split NTU-120 datasets demonstrate that CHARON sets a new benchmark in this domain. The code is available at https://github.com/Sperimental3/CHARON.
DistFormer: Enhancing Local and Global Features for Monocular Per-Object Distance Estimation
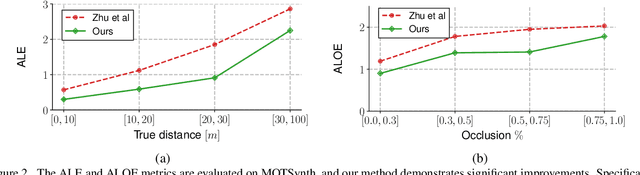
Jan 06, 2024Accurate per-object distance estimation is crucial in safety-critical applications such as autonomous driving, surveillance, and robotics. Existing approaches rely on two scales: local information (i.e., the bounding box proportions) or global information, which encodes the semantics of the scene as well as the spatial relations with neighboring objects. However, these approaches may struggle with long-range objects and in the presence of strong occlusions or unusual visual patterns. In this respect, our work aims to strengthen both local and global cues. Our architecture -- named DistFormer -- builds upon three major components acting jointly: i) a robust context encoder extracting fine-grained per-object representations; ii) a masked encoder-decoder module exploiting self-supervision to promote the learning of useful per-object features; iii) a global refinement module that aggregates object representations and computes a joint, spatially-consistent estimation. To evaluate the effectiveness of DistFormer, we conduct experiments on the standard KITTI dataset and the large-scale NuScenes and MOTSynth datasets. Such datasets cover various indoor/outdoor environments, changing weather conditions, appearances, and camera viewpoints. Our comprehensive analysis shows that DistFormer outperforms existing methods. Moreover, we further delve into its generalization capabilities, showing its regularization benefits in zero-shot synth-to-real transfer.
TrackFlow: Multi-Object Tracking with Normalizing Flows
Aug 22, 2023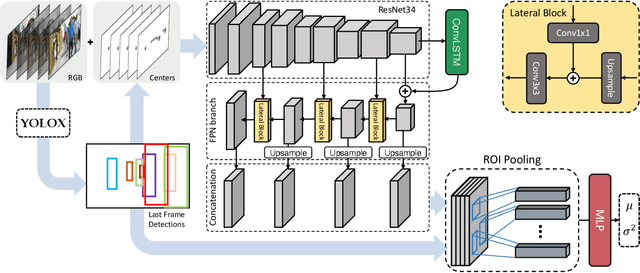


The field of multi-object tracking has recently seen a renewed interest in the good old schema of tracking-by-detection, as its simplicity and strong priors spare it from the complex design and painful babysitting of tracking-by-attention approaches. In view of this, we aim at extending tracking-by-detection to multi-modal settings, where a comprehensive cost has to be computed from heterogeneous information e.g., 2D motion cues, visual appearance, and pose estimates. More precisely, we follow a case study where a rough estimate of 3D information is also available and must be merged with other traditional metrics (e.g., the IoU). To achieve that, recent approaches resort to either simple rules or complex heuristics to balance the contribution of each cost. However, i) they require careful tuning of tailored hyperparameters on a hold-out set, and ii) they imply these costs to be independent, which does not hold in reality. We address these issues by building upon an elegant probabilistic formulation, which considers the cost of a candidate association as the negative log-likelihood yielded by a deep density estimator, trained to model the conditional joint probability distribution of correct associations. Our experiments, conducted on both simulated and real benchmarks, show that our approach consistently enhances the performance of several tracking-by-detection algorithms.
Consistency-based Self-supervised Learning for Temporal Anomaly Localization
Aug 10, 2022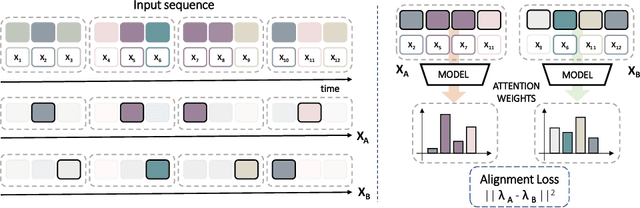

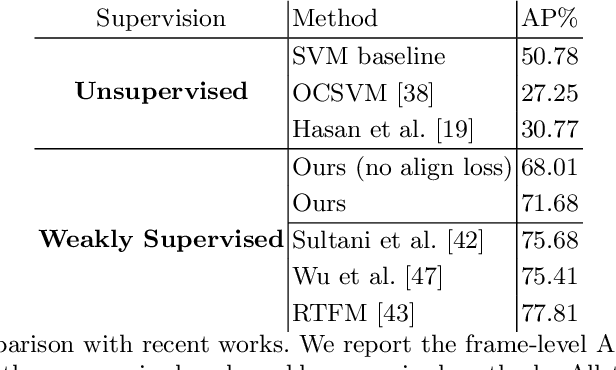
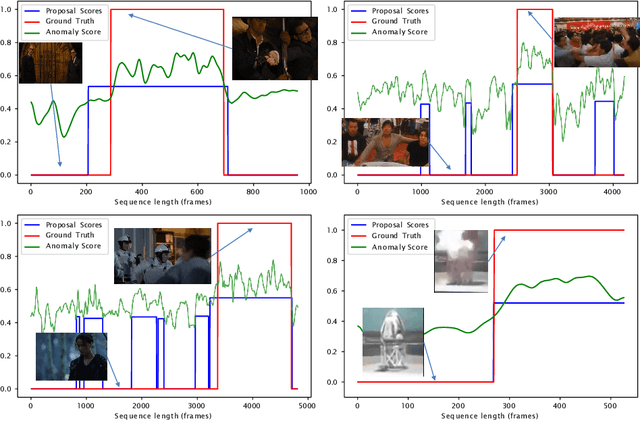
This work tackles Weakly Supervised Anomaly detection, in which a predictor is allowed to learn not only from normal examples but also from a few labeled anomalies made available during training. In particular, we deal with the localization of anomalous activities within the video stream: this is a very challenging scenario, as training examples come only with video-level annotations (and not frame-level). Several recent works have proposed various regularization terms to address it i.e. by enforcing sparsity and smoothness constraints over the weakly-learned frame-level anomaly scores. In this work, we get inspired by recent advances within the field of self-supervised learning and ask the model to yield the same scores for different augmentations of the same video sequence. We show that enforcing such an alignment improves the performance of the model on XD-Violence.