 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCLIP with Generative Latent Replay: a Strong Baseline for Incremental Learning
Jul 22, 2024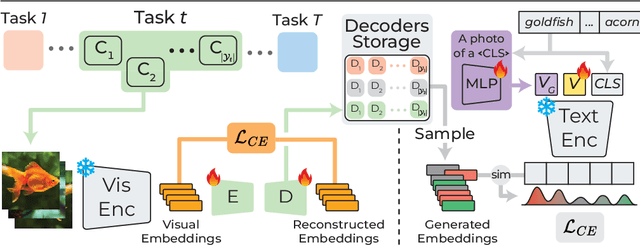
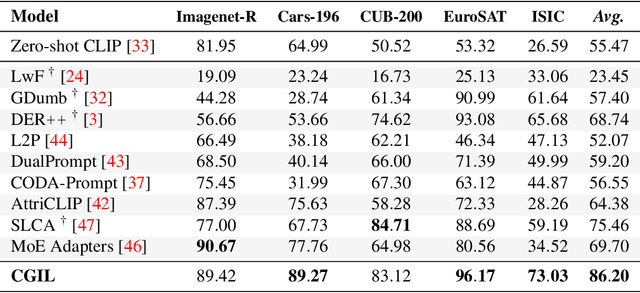
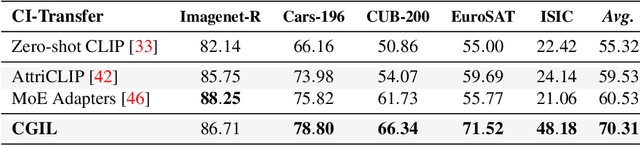
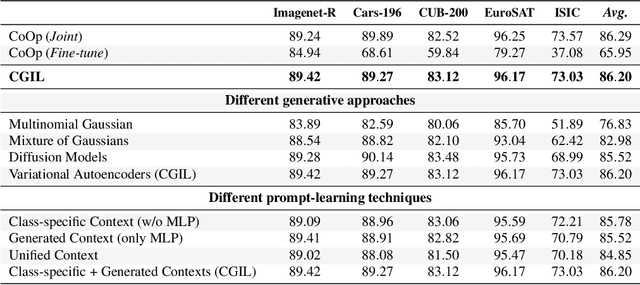
With the emergence of Transformers and Vision-Language Models (VLMs) such as CLIP, large pre-trained models have become a common strategy to enhance performance in Continual Learning scenarios. This led to the development of numerous prompting strategies to effectively fine-tune transformer-based models without succumbing to catastrophic forgetting. However, these methods struggle to specialize the model on domains significantly deviating from the pre-training and preserving its zero-shot capabilities. In this work, we propose Continual Generative training for Incremental prompt-Learning, a novel approach to mitigate forgetting while adapting a VLM, which exploits generative replay to align prompts to tasks. We also introduce a new metric to evaluate zero-shot capabilities within CL benchmarks. Through extensive experiments on different domains, we demonstrate the effectiveness of our framework in adapting to new tasks while improving zero-shot capabilities. Further analysis reveals that our approach can bridge the gap with joint prompt tuning. The codebase is available at https://github.com/aimagelab/mammoth.
An Attention-based Representation Distillation Baseline for Multi-Label Continual Learning
Jul 19, 2024


The field of Continual Learning (CL) has inspired numerous researchers over the years, leading to increasingly advanced countermeasures to the issue of catastrophic forgetting. Most studies have focused on the single-class scenario, where each example comes with a single label. The recent literature has successfully tackled such a setting, with impressive results. Differently, we shift our attention to the multi-label scenario, as we feel it to be more representative of real-world open problems. In our work, we show that existing state-of-the-art CL methods fail to achieve satisfactory performance, thus questioning the real advance claimed in recent years. Therefore, we assess both old-style and novel strategies and propose, on top of them, an approach called Selective Class Attention Distillation (SCAD). It relies on a knowledge transfer technique that seeks to align the representations of the student network -- which trains continuously and is subject to forgetting -- with the teacher ones, which is pretrained and kept frozen. Importantly, our method is able to selectively transfer the relevant information from the teacher to the student, thereby preventing irrelevant information from harming the student's performance during online training. To demonstrate the merits of our approach, we conduct experiments on two different multi-label datasets, showing that our method outperforms the current state-of-the-art Continual Learning methods. Our findings highlight the importance of addressing the unique challenges posed by multi-label environments in the field of Continual Learning. The code of SCAD is available at https://github.com/aimagelab/SCAD-LOD-2024.
Semantic Residual Prompts for Continual Learning
Mar 14, 2024Prompt-tuning methods for Continual Learning (CL) freeze a large pre-trained model and focus training on a few parameter vectors termed prompts. Most of these methods organize these vectors in a pool of key-value pairs, and use the input image as query to retrieve the prompts (values). However, as keys are learned while tasks progress, the prompting selection strategy is itself subject to catastrophic forgetting, an issue often overlooked by existing approaches. For instance, prompts introduced to accommodate new tasks might end up interfering with previously learned prompts. To make the selection strategy more stable, we ask a foundational model (CLIP) to select our prompt within a two-level adaptation mechanism. Specifically, the first level leverages standard textual prompts for the CLIP textual encoder, leading to stable class prototypes. The second level, instead, uses these prototypes along with the query image as keys to index a second pool. The retrieved prompts serve to adapt a pre-trained ViT, granting plasticity. In doing so, we also propose a novel residual mechanism to transfer CLIP semantics to the ViT layers. Through extensive analysis on established CL benchmarks, we show that our method significantly outperforms both state-of-the-art CL approaches and the zero-shot CLIP test. Notably, our findings hold true even for datasets with a substantial domain gap w.r.t. the pre-training knowledge of the backbone model, as showcased by experiments on satellite imagery and medical datasets.
On the Effectiveness of Equivariant Regularization for Robust Online Continual Learning
May 05, 2023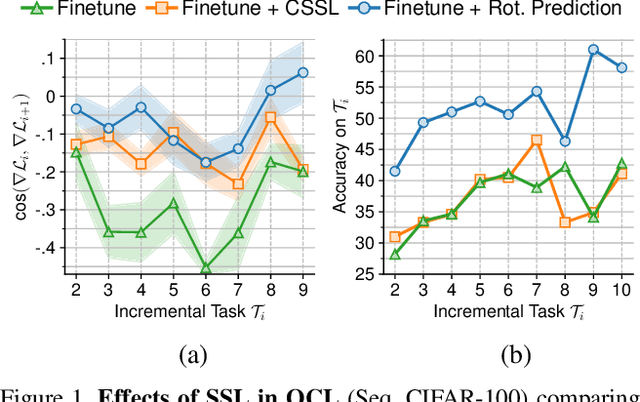
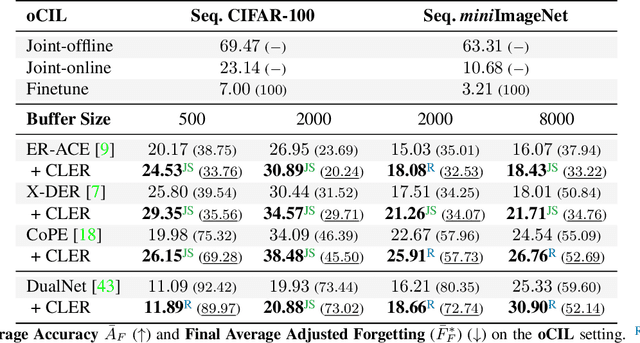
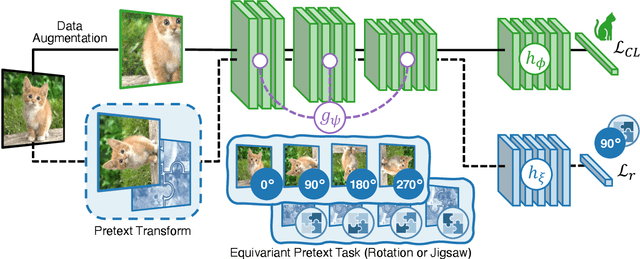
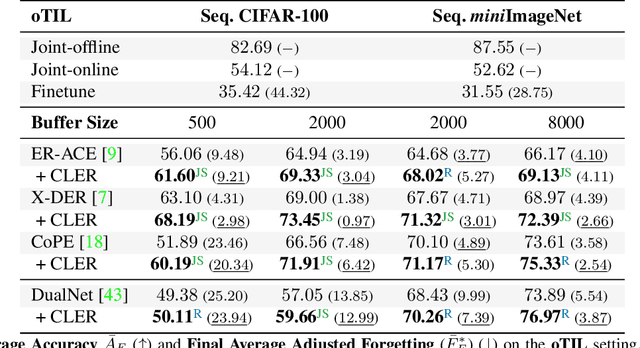
Humans can learn incrementally, whereas neural networks forget previously acquired information catastrophically. Continual Learning (CL) approaches seek to bridge this gap by facilitating the transfer of knowledge to both previous tasks (backward transfer) and future ones (forward transfer) during training. Recent research has shown that self-supervision can produce versatile models that can generalize well to diverse downstream tasks. However, contrastive self-supervised learning (CSSL), a popular self-supervision technique, has limited effectiveness in online CL (OCL). OCL only permits one iteration of the input dataset, and CSSL's low sample efficiency hinders its use on the input data-stream. In this work, we propose Continual Learning via Equivariant Regularization (CLER), an OCL approach that leverages equivariant tasks for self-supervision, avoiding CSSL's limitations. Our method represents the first attempt at combining equivariant knowledge with CL and can be easily integrated with existing OCL methods. Extensive ablations shed light on how equivariant pretext tasks affect the network's information flow and its impact on CL dynamics.
CaSpeR: Latent Spectral Regularization for Continual Learning
Jan 09, 2023While biological intelligence grows organically as new knowledge is gathered throughout life, Artificial Neural Networks forget catastrophically whenever they face a changing training data distribution. Rehearsal-based Continual Learning (CL) approaches have been established as a versatile and reliable solution to overcome this limitation; however, sudden input disruptions and memory constraints are known to alter the consistency of their predictions. We study this phenomenon by investigating the geometric characteristics of the learner's latent space and find that replayed data points of different classes increasingly mix up, interfering with classification. Hence, we propose a geometric regularizer that enforces weak requirements on the Laplacian spectrum of the latent space, promoting a partitioning behavior. We show that our proposal, called Continual Spectral Regularizer (CaSpeR), can be easily combined with any rehearsal-based CL approach and improves the performance of SOTA methods on standard benchmarks. Finally, we conduct additional analysis to provide insights into CaSpeR's effects and applicability.