 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZero-Shot Decentralized Federated Learning
Sep 30, 2025CLIP has revolutionized zero-shot learning by enabling task generalization without fine-tuning. While prompting techniques like CoOp and CoCoOp enhance CLIP's adaptability, their effectiveness in Federated Learning (FL) remains an open challenge. Existing federated prompt learning approaches, such as FedCoOp and FedTPG, improve performance but face generalization issues, high communication costs, and reliance on a central server, limiting scalability and privacy. We propose Zero-shot Decentralized Federated Learning (ZeroDFL), a fully decentralized framework that enables zero-shot adaptation across distributed clients without a central coordinator. ZeroDFL employs an iterative prompt-sharing mechanism, allowing clients to optimize and exchange textual prompts to enhance generalization while drastically reducing communication overhead. We validate ZeroDFL on nine diverse image classification datasets, demonstrating that it consistently outperforms--or remains on par with--state-of-the-art federated prompt learning methods. More importantly, ZeroDFL achieves this performance in a fully decentralized setting while reducing communication overhead by 118x compared to FedTPG. These results highlight that our approach not only enhances generalization in federated zero-shot learning but also improves scalability, efficiency, and privacy preservation--paving the way for decentralized adaptation of large vision-language models in real-world applications.
FedRewind: Rewinding Continual Model Exchange for Decentralized Federated Learning
Nov 14, 2024



In this paper, we present FedRewind, a novel approach to decentralized federated learning that leverages model exchange among nodes to address the issue of data distribution shift. Drawing inspiration from continual learning (CL) principles and cognitive neuroscience theories for memory retention, FedRewind implements a decentralized routing mechanism where nodes send/receive models to/from other nodes in the federation to address spatial distribution challenges inherent in distributed learning (FL). During local training, federation nodes periodically send their models back (i.e., rewind) to the nodes they received them from for a limited number of iterations. This strategy reduces the distribution shift between nodes' data, leading to enhanced learning and generalization performance. We evaluate our method on multiple benchmarks, demonstrating its superiority over standard decentralized federated learning methods and those enforcing specific routing schemes within the federation. Furthermore, the combination of federated and continual learning concepts enables our method to tackle the more challenging federated continual learning task, with data shifts over both space and time, surpassing existing baselines.
Diffexplainer: Towards Cross-modal Global Explanations with Diffusion Models
Apr 03, 2024



We present DiffExplainer, a novel framework that, leveraging language-vision models, enables multimodal global explainability. DiffExplainer employs diffusion models conditioned on optimized text prompts, synthesizing images that maximize class outputs and hidden features of a classifier, thus providing a visual tool for explaining decisions. Moreover, the analysis of generated visual descriptions allows for automatic identification of biases and spurious features, as opposed to traditional methods that often rely on manual intervention. The cross-modal transferability of language-vision models also enables the possibility to describe decisions in a more human-interpretable way, i.e., through text. We conduct comprehensive experiments, which include an extensive user study, demonstrating the effectiveness of DiffExplainer on 1) the generation of high-quality images explaining model decisions, surpassing existing activation maximization methods, and 2) the automated identification of biases and spurious features.
Selective Attention-based Modulation for Continual Learning
Mar 29, 2024



We present SAM, a biologically-plausible selective attention-driven modulation approach to enhance classification models in a continual learning setting. Inspired by neurophysiological evidence that the primary visual cortex does not contribute to object manifold untangling for categorization and that primordial attention biases are still embedded in the modern brain, we propose to employ auxiliary saliency prediction features as a modulation signal to drive and stabilize the learning of a sequence of non-i.i.d. classification tasks. Experimental results confirm that SAM effectively enhances the performance (in some cases up to about twenty percent points) of state-of-the-art continual learning methods, both in class-incremental and task-incremental settings. Moreover, we show that attention-based modulation successfully encourages the learning of features that are more robust to the presence of spurious features and to adversarial attacks than baseline methods. Code is available at: https://github.com/perceivelab/SAM.
A Privacy-Preserving Walk in the Latent Space of Generative Models for Medical Applications
Jul 06, 2023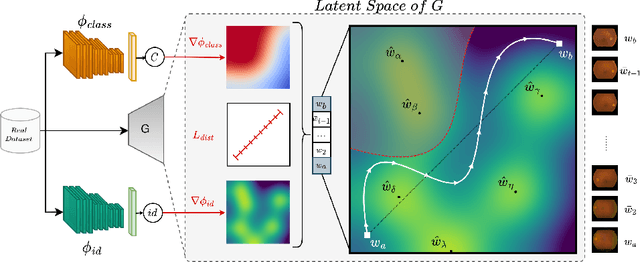
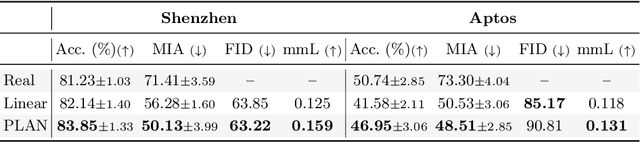
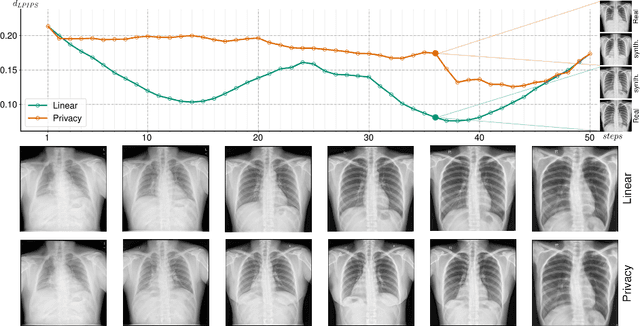

Generative Adversarial Networks (GANs) have demonstrated their ability to generate synthetic samples that match a target distribution. However, from a privacy perspective, using GANs as a proxy for data sharing is not a safe solution, as they tend to embed near-duplicates of real samples in the latent space. Recent works, inspired by k-anonymity principles, address this issue through sample aggregation in the latent space, with the drawback of reducing the dataset by a factor of k. Our work aims to mitigate this problem by proposing a latent space navigation strategy able to generate diverse synthetic samples that may support effective training of deep models, while addressing privacy concerns in a principled way. Our approach leverages an auxiliary identity classifier as a guide to non-linearly walk between points in the latent space, minimizing the risk of collision with near-duplicates of real samples. We empirically demonstrate that, given any random pair of points in the latent space, our walking strategy is safer than linear interpolation. We then test our path-finding strategy combined to k-same methods and demonstrate, on two benchmarks for tuberculosis and diabetic retinopathy classification, that training a model using samples generated by our approach mitigate drops in performance, while keeping privacy preservation.
On the Effectiveness of Equivariant Regularization for Robust Online Continual Learning
May 05, 2023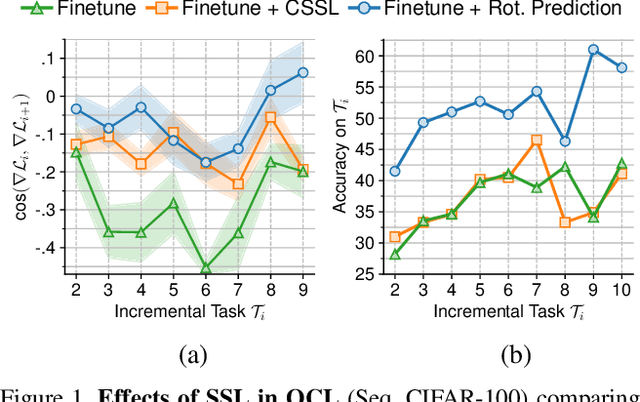
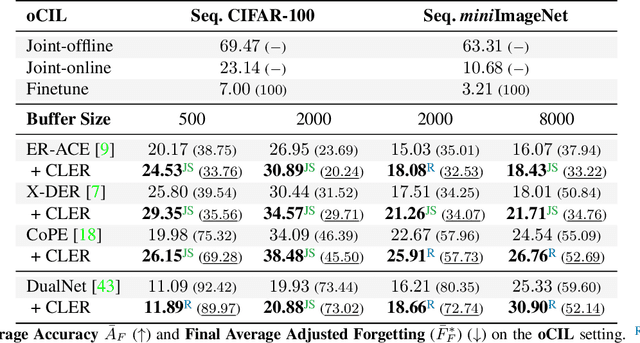
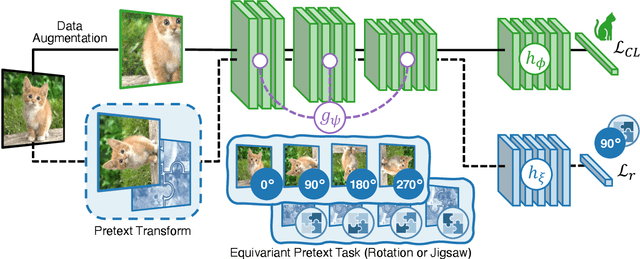
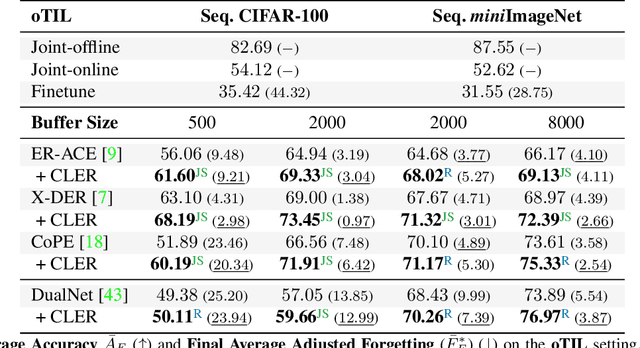
Humans can learn incrementally, whereas neural networks forget previously acquired information catastrophically. Continual Learning (CL) approaches seek to bridge this gap by facilitating the transfer of knowledge to both previous tasks (backward transfer) and future ones (forward transfer) during training. Recent research has shown that self-supervision can produce versatile models that can generalize well to diverse downstream tasks. However, contrastive self-supervised learning (CSSL), a popular self-supervision technique, has limited effectiveness in online CL (OCL). OCL only permits one iteration of the input dataset, and CSSL's low sample efficiency hinders its use on the input data-stream. In this work, we propose Continual Learning via Equivariant Regularization (CLER), an OCL approach that leverages equivariant tasks for self-supervision, avoiding CSSL's limitations. Our method represents the first attempt at combining equivariant knowledge with CL and can be easily integrated with existing OCL methods. Extensive ablations shed light on how equivariant pretext tasks affect the network's information flow and its impact on CL dynamics.
Decentralized Distributed Learning with Privacy-Preserving Data Synthesis
Jun 20, 2022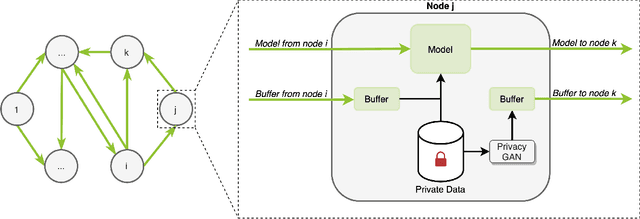
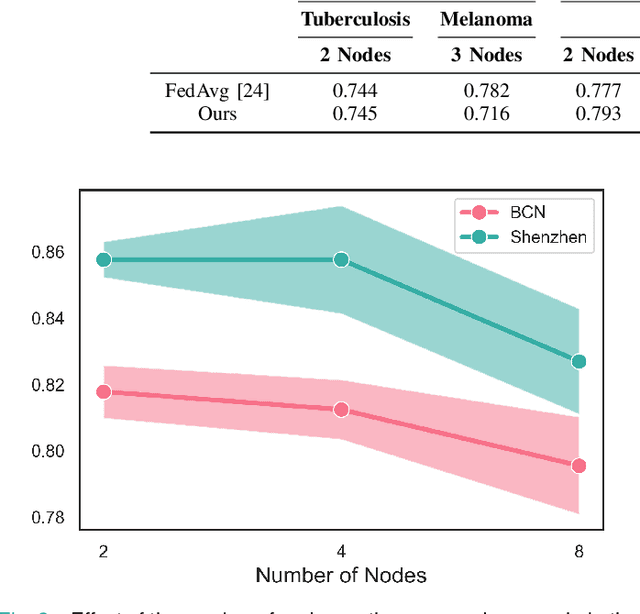
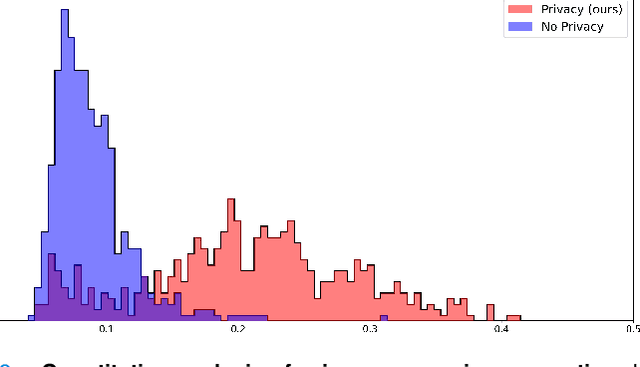
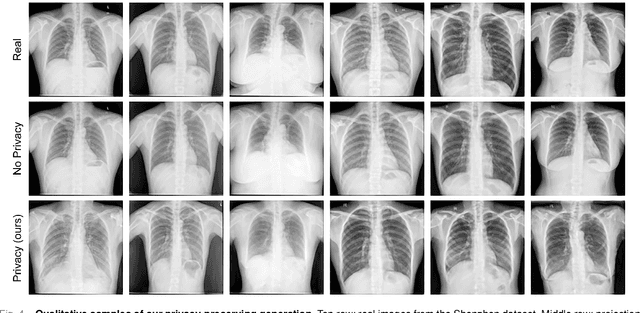
In the medical field, multi-center collaborations are often sought to yield more generalizable findings by leveraging the heterogeneity of patient and clinical data. However, recent privacy regulations hinder the possibility to share data, and consequently, to come up with machine learning-based solutions that support diagnosis and prognosis. Federated learning (FL) aims at sidestepping this limitation by bringing AI-based solutions to data owners and only sharing local AI models, or parts thereof, that need then to be aggregated. However, most of the existing federated learning solutions are still at their infancy and show several shortcomings, from the lack of a reliable and effective aggregation scheme able to retain the knowledge learned locally to weak privacy preservation as real data may be reconstructed from model updates. Furthermore, the majority of these approaches, especially those dealing with medical data, relies on a centralized distributed learning strategy that poses robustness, scalability and trust issues. In this paper we present a decentralized distributed method that, exploiting concepts from experience replay and generative adversarial research, effectively integrates features from local nodes, providing models able to generalize across multiple datasets while maintaining privacy. The proposed approach is tested on two tasks - tuberculosis and melanoma classification - using multiple datasets in order to simulate realistic non-i.i.d. data scenarios. Results show that our approach achieves performance comparable to both standard (non-federated) learning and federated methods in their centralized (thus, more favourable) formulation.
Effects of Auxiliary Knowledge on Continual Learning
Jun 03, 2022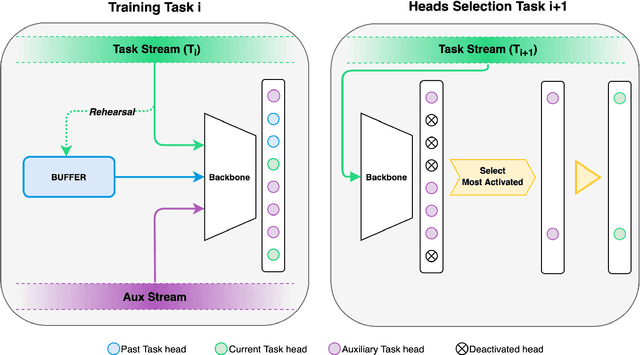
In Continual Learning (CL), a neural network is trained on a stream of data whose distribution changes over time. In this context, the main problem is how to learn new information without forgetting old knowledge (i.e., Catastrophic Forgetting). Most existing CL approaches focus on finding solutions to preserve acquired knowledge, so working on the past of the model. However, we argue that as the model has to continually learn new tasks, it is also important to put focus on the present knowledge that could improve following tasks learning. In this paper we propose a new, simple, CL algorithm that focuses on solving the current task in a way that might facilitate the learning of the next ones. More specifically, our approach combines the main data stream with a secondary, diverse and uncorrelated stream, from which the network can draw auxiliary knowledge. This helps the model from different perspectives, since auxiliary data may contain useful features for the current and the next tasks and incoming task classes can be mapped onto auxiliary classes. Furthermore, the addition of data to the current task is implicitly making the classifier more robust as we are forcing the extraction of more discriminative features. Our method can outperform existing state-of-the-art models on the most common CL Image Classification benchmarks.
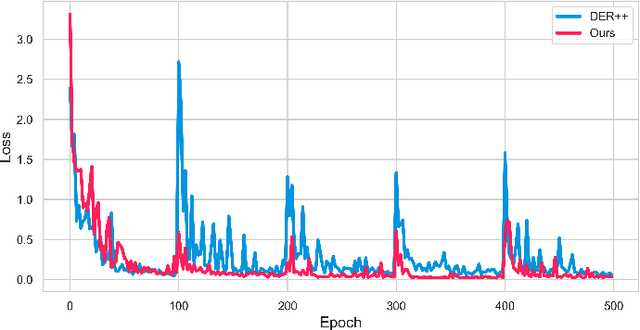
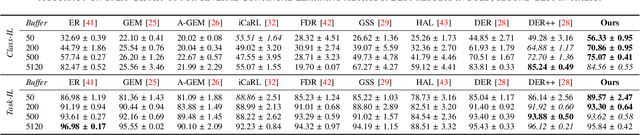
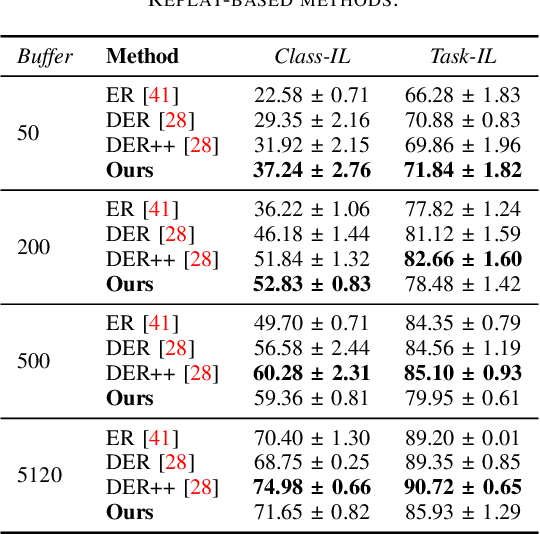
Transfer without Forgetting
Jun 01, 2022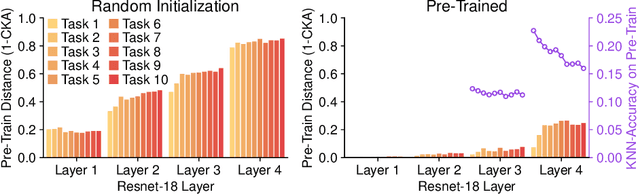
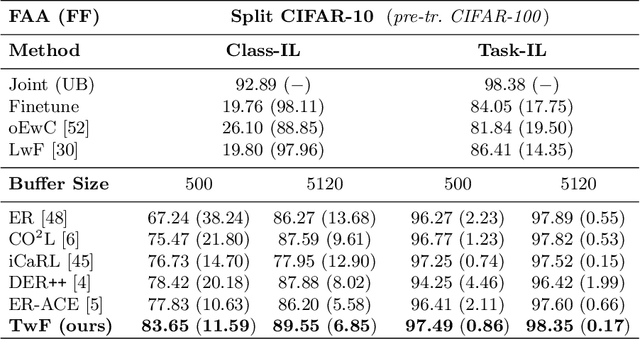
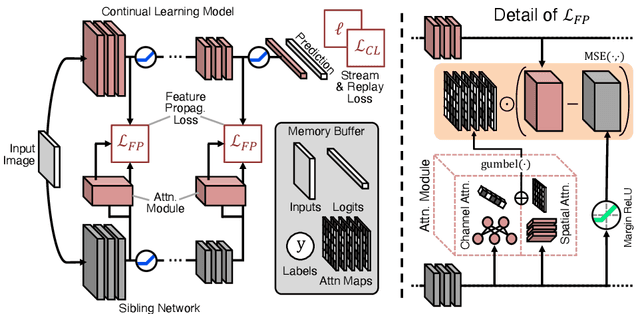
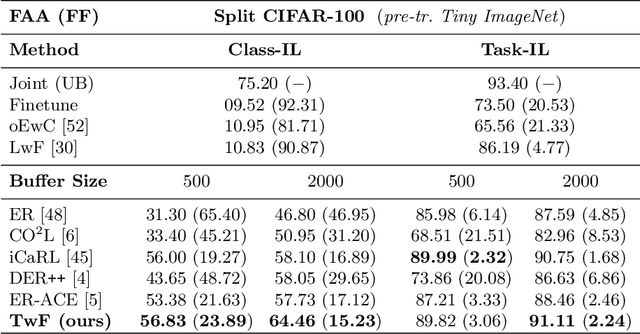
This work investigates the entanglement between Continual Learning (CL) and Transfer Learning (TL). In particular, we shed light on the widespread application of network pretraining, highlighting that it is itself subject to catastrophic forgetting. Unfortunately, this issue leads to the under-exploitation of knowledge transfer during later tasks. On this ground, we propose Transfer without Forgetting (TwF), a hybrid Continual Transfer Learning approach building upon a fixed pretrained sibling network, which continuously propagates the knowledge inherent in the source domain through a layer-wise loss term. Our experiments indicate that TwF steadily outperforms other CL methods across a variety of settings, averaging a 4.81% gain in Class-Incremental accuracy over a variety of datasets and different buffer sizes.
Bringing AI pipelines onto cloud-HPC: setting a baseline for accuracy of COVID-19 AI diagnosis
Aug 02, 2021HPC is an enabling platform for AI. The introduction of AI workloads in the HPC applications basket has non-trivial consequences both on the way of designing AI applications and on the way of providing HPC computing. This is the leitmotif of the convergence between HPC and AI. The formalized definition of AI pipelines is one of the milestones of HPC-AI convergence. If well conducted, it allows, on the one hand, to obtain portable and scalable applications. On the other hand, it is crucial for the reproducibility of scientific pipelines. In this work, we advocate the StreamFlow Workflow Management System as a crucial ingredient to define a parametric pipeline, called "CLAIRE COVID-19 Universal Pipeline," which is able to explore the optimization space of methods to classify COVID-19 lung lesions from CT scans, compare them for accuracy, and therefore set a performance baseline. The universal pipeline automatizes the training of many different Deep Neural Networks (DNNs) and many different hyperparameters. It, therefore, requires a massive computing power, which is found in traditional HPC infrastructure thanks to the portability-by-design of pipelines designed with StreamFlow. Using the universal pipeline, we identified a DNN reaching over 90% accuracy in detecting COVID-19 lesions in CT scans.