 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Privacy-Preserving Walk in the Latent Space of Generative Models for Medical Applications
Paper and Code
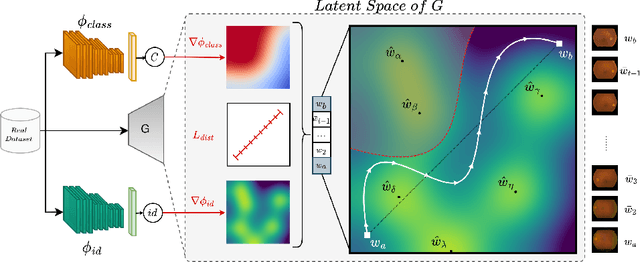
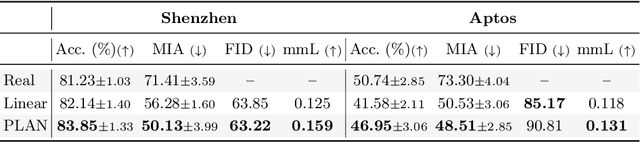
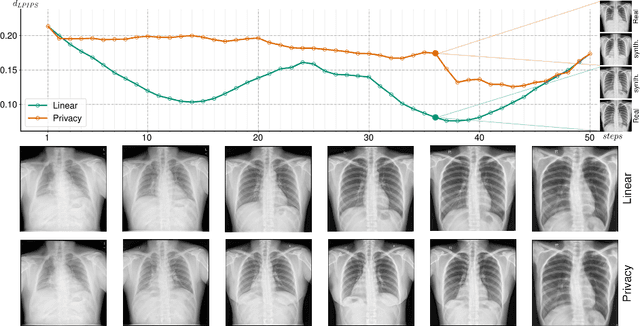

Generative Adversarial Networks (GANs) have demonstrated their ability to generate synthetic samples that match a target distribution. However, from a privacy perspective, using GANs as a proxy for data sharing is not a safe solution, as they tend to embed near-duplicates of real samples in the latent space. Recent works, inspired by k-anonymity principles, address this issue through sample aggregation in the latent space, with the drawback of reducing the dataset by a factor of k. Our work aims to mitigate this problem by proposing a latent space navigation strategy able to generate diverse synthetic samples that may support effective training of deep models, while addressing privacy concerns in a principled way. Our approach leverages an auxiliary identity classifier as a guide to non-linearly walk between points in the latent space, minimizing the risk of collision with near-duplicates of real samples. We empirically demonstrate that, given any random pair of points in the latent space, our walking strategy is safer than linear interpolation. We then test our path-finding strategy combined to k-same methods and demonstrate, on two benchmarks for tuberculosis and diabetic retinopathy classification, that training a model using samples generated by our approach mitigate drops in performance, while keeping privacy preservation.