 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDecentralized Time Series Classification with ROCKET Features
Apr 24, 2025Time series classification (TSC) is a critical task with applications in various domains, including healthcare, finance, and industrial monitoring. Due to privacy concerns and data regulations, Federated Learning has emerged as a promising approach for learning from distributed time series data without centralizing raw information. However, most FL solutions rely on a client-server architecture, which introduces robustness and confidentiality risks related to the distinguished role of the server, which is a single point of failure and can observe knowledge extracted from clients. To address these challenges, we propose DROCKS, a fully decentralized FL framework for TSC that leverages ROCKET (RandOm Convolutional KErnel Transform) features. In DROCKS, the global model is trained by sequentially traversing a structured path across federation nodes, where each node refines the model and selects the most effective local kernels before passing them to the successor. Extensive experiments on the UCR archive demonstrate that DROCKS outperforms state-of-the-art client-server FL approaches while being more resilient to node failures and malicious attacks. Our code is available at https://anonymous.4open.science/r/DROCKS-7FF3/README.md.
Benchmarking FedAvg and FedCurv for Image Classification Tasks
Mar 31, 2023Classic Machine Learning techniques require training on data available in a single data lake. However, aggregating data from different owners is not always convenient for different reasons, including security, privacy and secrecy. Data carry a value that might vanish when shared with others; the ability to avoid sharing the data enables industrial applications where security and privacy are of paramount importance, making it possible to train global models by implementing only local policies which can be run independently and even on air-gapped data centres. Federated Learning (FL) is a distributed machine learning approach which has emerged as an effective way to address privacy concerns by only sharing local AI models while keeping the data decentralized. Two critical challenges of Federated Learning are managing the heterogeneous systems in the same federated network and dealing with real data, which are often not independently and identically distributed (non-IID) among the clients. In this paper, we focus on the second problem, i.e., the problem of statistical heterogeneity of the data in the same federated network. In this setting, local models might be strayed far from the local optimum of the complete dataset, thus possibly hindering the convergence of the federated model. Several Federated Learning algorithms, such as FedAvg, FedProx and Federated Curvature (FedCurv), aiming at tackling the non-IID setting, have already been proposed. This work provides an empirical assessment of the behaviour of FedAvg and FedCurv in common non-IID scenarios. Results show that the number of epochs per round is an important hyper-parameter that, when tuned appropriately, can lead to significant performance gains while reducing the communication cost. As a side product of this work, we release the non-IID version of the datasets we used so to facilitate further comparisons from the FL community.
* 12 pages, Proceedings of ITADATA22, The 1st Italian Conference on Big Data and Data Science; Published on CEUR Workshop Proceedings (CEUR-WS.org, ISSN 1613-0073), Vol. 3340, pp. 99-110, 2022
Experimenting with Normalization Layers in Federated Learning on non-IID scenarios
Mar 19, 2023



Training Deep Learning (DL) models require large, high-quality datasets, often assembled with data from different institutions. Federated Learning (FL) has been emerging as a method for privacy-preserving pooling of datasets employing collaborative training from different institutions by iteratively globally aggregating locally trained models. One critical performance challenge of FL is operating on datasets not independently and identically distributed (non-IID) among the federation participants. Even though this fragility cannot be eliminated, it can be debunked by a suitable optimization of two hyper-parameters: layer normalization methods and collaboration frequency selection. In this work, we benchmark five different normalization layers for training Neural Networks (NNs), two families of non-IID data skew, and two datasets. Results show that Batch Normalization, widely employed for centralized DL, is not the best choice for FL, whereas Group and Layer Normalization consistently outperform Batch Normalization. Similarly, frequent model aggregation decreases convergence speed and mode quality.
Transfer Learning via Test-Time Neural Networks Aggregation
Jun 27, 2022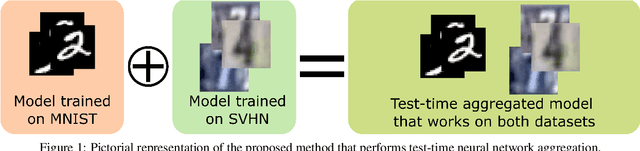
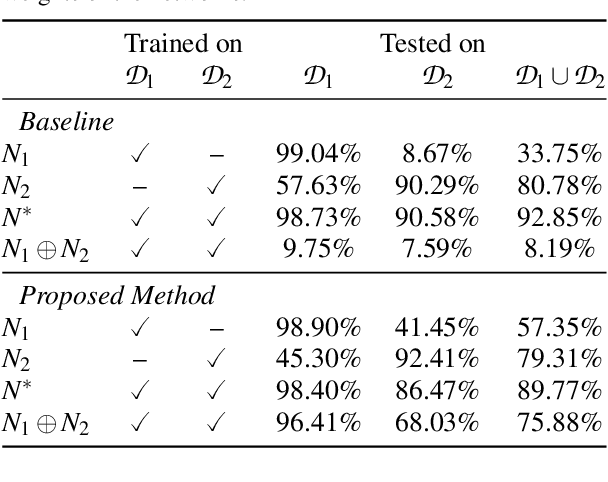
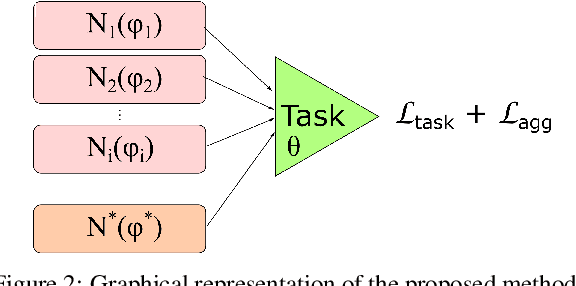
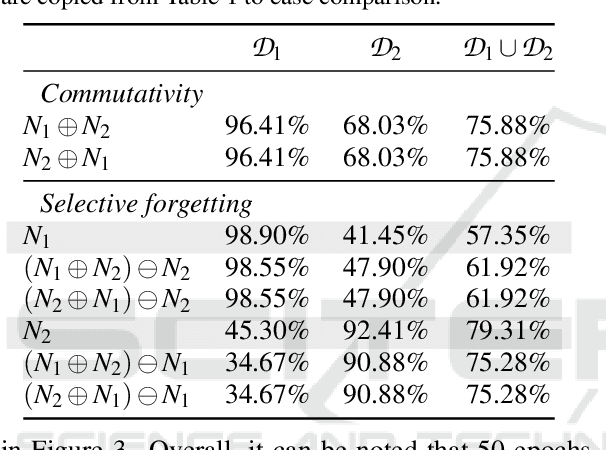
It has been demonstrated that deep neural networks outperform traditional machine learning. However, deep networks lack generalisability, that is, they will not perform as good as in a new (testing) set drawn from a different distribution due to the domain shift. In order to tackle this known issue, several transfer learning approaches have been proposed, where the knowledge of a trained model is transferred into another to improve performance with different data. However, most of these approaches require additional training steps, or they suffer from catastrophic forgetting that occurs when a trained model has overwritten previously learnt knowledge. We address both problems with a novel transfer learning approach that uses network aggregation. We train dataset-specific networks together with an aggregation network in a unified framework. The loss function includes two main components: a task-specific loss (such as cross-entropy) and an aggregation loss. The proposed aggregation loss allows our model to learn how trained deep network parameters can be aggregated with an aggregation operator. We demonstrate that the proposed approach learns model aggregation at test time without any further training step, reducing the burden of transfer learning to a simple arithmetical operation. The proposed approach achieves comparable performance w.r.t. the baseline. Besides, if the aggregation operator has an inverse, we will show that our model also inherently allows for selective forgetting, i.e., the aggregated model can forget one of the datasets it was trained on, retaining information on the others.
* 8 pages
Decentralized Distributed Learning with Privacy-Preserving Data Synthesis
Jun 20, 2022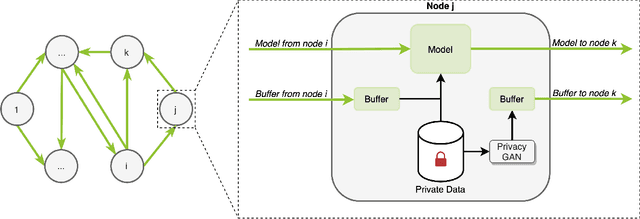
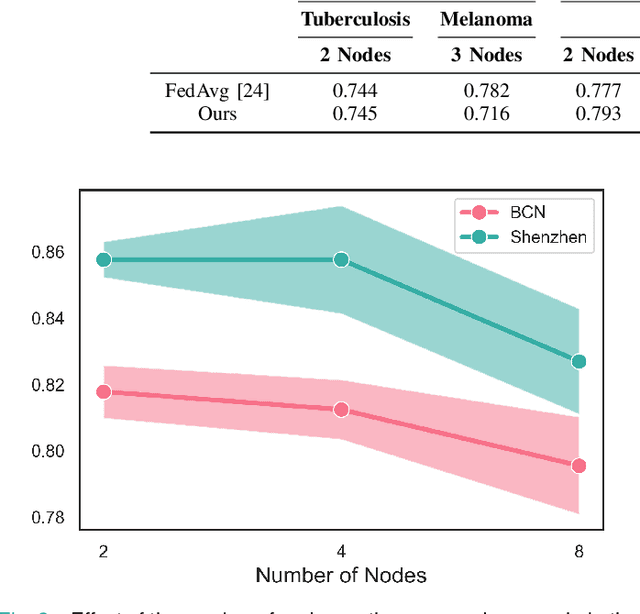
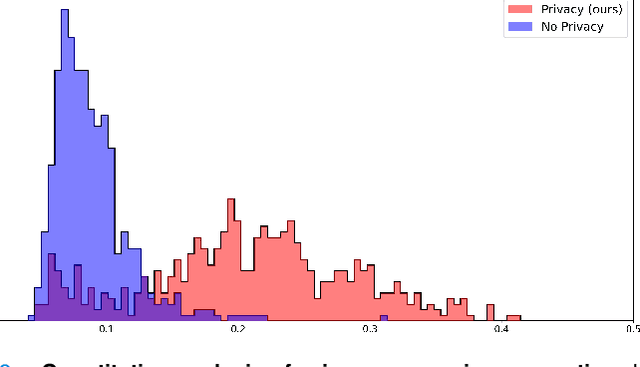
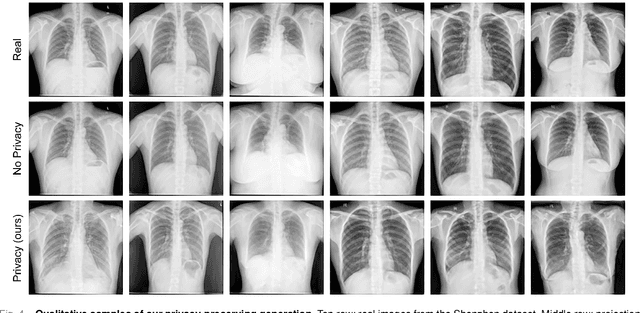
In the medical field, multi-center collaborations are often sought to yield more generalizable findings by leveraging the heterogeneity of patient and clinical data. However, recent privacy regulations hinder the possibility to share data, and consequently, to come up with machine learning-based solutions that support diagnosis and prognosis. Federated learning (FL) aims at sidestepping this limitation by bringing AI-based solutions to data owners and only sharing local AI models, or parts thereof, that need then to be aggregated. However, most of the existing federated learning solutions are still at their infancy and show several shortcomings, from the lack of a reliable and effective aggregation scheme able to retain the knowledge learned locally to weak privacy preservation as real data may be reconstructed from model updates. Furthermore, the majority of these approaches, especially those dealing with medical data, relies on a centralized distributed learning strategy that poses robustness, scalability and trust issues. In this paper we present a decentralized distributed method that, exploiting concepts from experience replay and generative adversarial research, effectively integrates features from local nodes, providing models able to generalize across multiple datasets while maintaining privacy. The proposed approach is tested on two tasks - tuberculosis and melanoma classification - using multiple datasets in order to simulate realistic non-i.i.d. data scenarios. Results show that our approach achieves performance comparable to both standard (non-federated) learning and federated methods in their centralized (thus, more favourable) formulation.