 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGraph Convolutional Branch and Bound
Jun 06, 2024This article demonstrates the effectiveness of employing a deep learning model in an optimization pipeline. Specifically, in a generic exact algorithm for a NP problem, multiple heuristic criteria are usually used to guide the search of the optimum within the set of all feasible solutions. In this context, neural networks can be leveraged to rapidly acquire valuable information, enabling the identification of a more expedient path in this vast space. So, after the explanation of the tackled traveling salesman problem, the implemented branch and bound for its classical resolution is described. This algorithm is then compared with its hybrid version termed "graph convolutional branch and bound" that integrates the previous branch and bound with a graph convolutional neural network. The empirical results obtained highlight the efficacy of this approach, leading to conclusive findings and suggesting potential directions for future research.
A preferential interpretation of MultiLayer Perceptrons in a conditional logic with typicality
May 11, 2023In this paper we investigate the relationships between a multipreferential semantics for defeasible reasoning in knowledge representation and a multilayer neural network model. Weighted knowledge bases for a simple description logic with typicality are considered under a (many-valued) ``concept-wise" multipreference semantics. The semantics is used to provide a preferential interpretation of MultiLayer Perceptrons (MLPs). A model checking and an entailment based approach are exploited in the verification of conditional properties of MLPs.
Benchmarking FedAvg and FedCurv for Image Classification Tasks
Mar 31, 2023Classic Machine Learning techniques require training on data available in a single data lake. However, aggregating data from different owners is not always convenient for different reasons, including security, privacy and secrecy. Data carry a value that might vanish when shared with others; the ability to avoid sharing the data enables industrial applications where security and privacy are of paramount importance, making it possible to train global models by implementing only local policies which can be run independently and even on air-gapped data centres. Federated Learning (FL) is a distributed machine learning approach which has emerged as an effective way to address privacy concerns by only sharing local AI models while keeping the data decentralized. Two critical challenges of Federated Learning are managing the heterogeneous systems in the same federated network and dealing with real data, which are often not independently and identically distributed (non-IID) among the clients. In this paper, we focus on the second problem, i.e., the problem of statistical heterogeneity of the data in the same federated network. In this setting, local models might be strayed far from the local optimum of the complete dataset, thus possibly hindering the convergence of the federated model. Several Federated Learning algorithms, such as FedAvg, FedProx and Federated Curvature (FedCurv), aiming at tackling the non-IID setting, have already been proposed. This work provides an empirical assessment of the behaviour of FedAvg and FedCurv in common non-IID scenarios. Results show that the number of epochs per round is an important hyper-parameter that, when tuned appropriately, can lead to significant performance gains while reducing the communication cost. As a side product of this work, we release the non-IID version of the datasets we used so to facilitate further comparisons from the FL community.
* 12 pages, Proceedings of ITADATA22, The 1st Italian Conference on Big Data and Data Science; Published on CEUR Workshop Proceedings (CEUR-WS.org, ISSN 1613-0073), Vol. 3340, pp. 99-110, 2022
Experimenting with Normalization Layers in Federated Learning on non-IID scenarios
Mar 19, 2023



Training Deep Learning (DL) models require large, high-quality datasets, often assembled with data from different institutions. Federated Learning (FL) has been emerging as a method for privacy-preserving pooling of datasets employing collaborative training from different institutions by iteratively globally aggregating locally trained models. One critical performance challenge of FL is operating on datasets not independently and identically distributed (non-IID) among the federation participants. Even though this fragility cannot be eliminated, it can be debunked by a suitable optimization of two hyper-parameters: layer normalization methods and collaboration frequency selection. In this work, we benchmark five different normalization layers for training Neural Networks (NNs), two families of non-IID data skew, and two datasets. Results show that Batch Normalization, widely employed for centralized DL, is not the best choice for FL, whereas Group and Layer Normalization consistently outperform Batch Normalization. Similarly, frequent model aggregation decreases convergence speed and mode quality.
Experimenting with Emerging ARM and RISC-V Systems for Decentralised Machine Learning
Feb 15, 2023



Decentralised Machine Learning (DML) enables collaborative machine learning without centralised input data. Federated Learning (FL) and Edge Inference are examples of DML. While tools for DML (especially FL) are starting to flourish, many are not flexible and portable enough to experiment with novel systems (e.g., RISC-V), non-fully connected topologies, and asynchronous collaboration schemes. We overcome these limitations via a domain-specific language allowing to map DML schemes to an underlying middleware, i.e. the \ff parallel programming library. We experiment with it by generating different working DML schemes on two emerging architectures (ARM-v8, RISC-V) and the x86-64 platform. We characterise the performance and energy efficiency of the presented schemes and systems. As a byproduct, we introduce a RISC-V porting of the PyTorch framework, the first publicly available to our knowledge.
Invariant Representations with Stochastically Quantized Neural Networks
Aug 04, 2022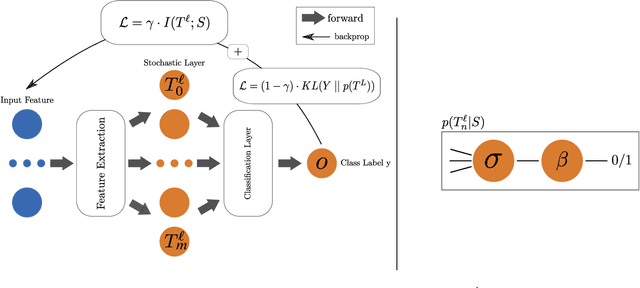
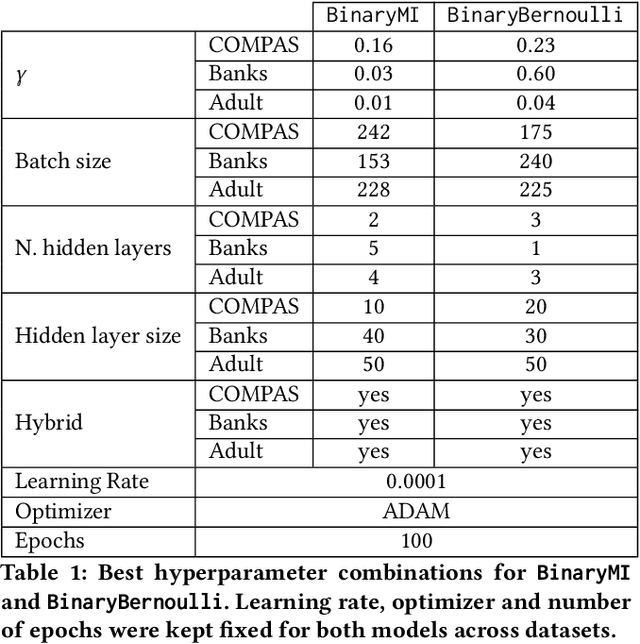
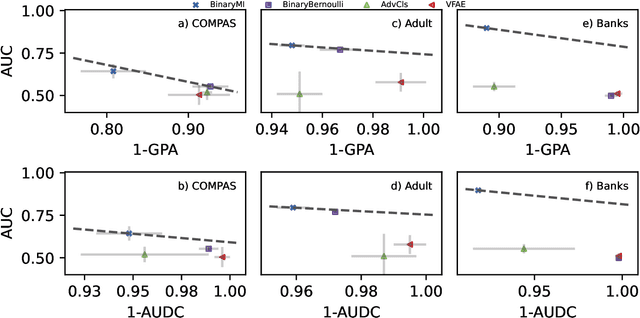

Representation learning algorithms offer the opportunity to learn invariant representations of the input data with regard to nuisance factors. Many authors have leveraged such strategies to learn fair representations, i.e., vectors where information about sensitive attributes is removed. These methods are attractive as they may be interpreted as minimizing the mutual information between a neural layer's activations and a sensitive attribute. However, the theoretical grounding of such methods relies either on the computation of infinitely accurate adversaries or on minimizing a variational upper bound of a mutual information estimate. In this paper, we propose a methodology for direct computation of the mutual information between a neural layer and a sensitive attribute. We employ stochastically-activated binary neural networks, which lets us treat neurons as random variables. We are then able to compute (not bound) the mutual information between a layer and a sensitive attribute and use this information as a regularization factor during gradient descent. We show that this method compares favorably with the state of the art in fair representation learning and that the learned representations display a higher level of invariance compared to full-precision neural networks.
Fair Interpretable Representation Learning with Correction Vectors
Feb 07, 2022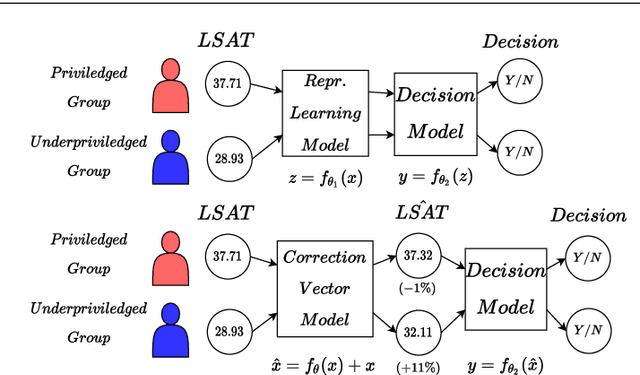
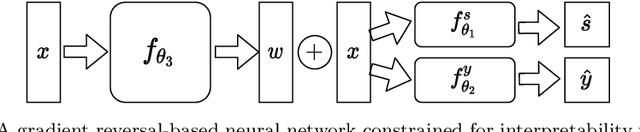
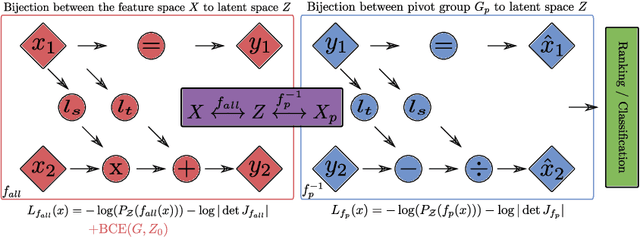
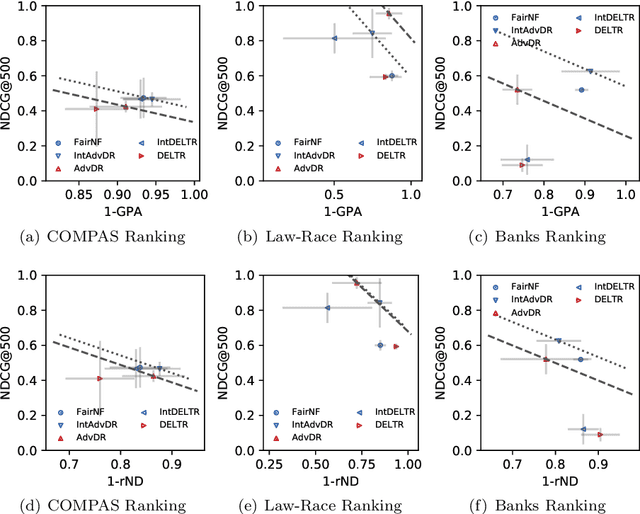
Neural network architectures have been extensively employed in the fair representation learning setting, where the objective is to learn a new representation for a given vector which is independent of sensitive information. Various representation debiasing techniques have been proposed in the literature. However, as neural networks are inherently opaque, these methods are hard to comprehend, which limits their usefulness. We propose a new framework for fair representation learning that is centered around the learning of "correction vectors", which have the same dimensionality as the given data vectors. Correction vectors may be computed either explicitly via architectural constraints or implicitly by training an invertible model based on Normalizing Flows. We show experimentally that several fair representation learning models constrained in such a way do not exhibit losses in ranking or classification performance. Furthermore, we demonstrate that state-of-the-art results can be achieved by the invertible model. Finally, we discuss the law standing of our methodology in light of recent legislation in the European Union.
Partitioned Least Squares
Jun 29, 2020


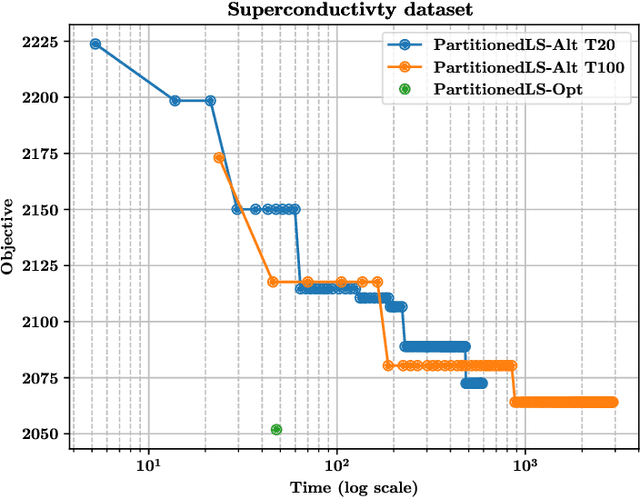
In this paper we propose a variant of the linear least squares model allowing practitioners to partition the input features into groups of variables that they require to contribute similarly to the final result. The output allows practitioners to assess the importance of each group and of each variable in the group. We formally show that the new formulation is not convex and provide two alternative methods to deal with the problem: one non-exact method based on an alternating least squares approach; and one exact method based on a reformulation of the problem using an exponential number of sub-problems whose minimum is guaranteed to be the optimal solution. We formally show the correctness of the exact method and also compare the two solutions showing that the exact solution provides better results in a fraction of the time required by the alternating least squares solution (assuming that the number of partitions is small). For the sake of completeness, we also provide an alternative branch and bound algorithm that can be used in place of the exact method when the number of partitions is too large, and a proof of NP-completeness of the optimization problem introduced in this paper.