 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTMPDiff: Temporal Mixed-Precision for Diffusion Models
Mar 14, 2026Diffusion models are the go-to method for Text-to-Image generation, but their iterative denoising processes has high inference latency. Quantization reduces compute time by using lower bitwidths, but applies a fixed precision across all denoising timesteps, leaving an entire optimization axis unexplored. We propose TMPDiff, a temporal mixed-precision framework for diffusion models that assigns different numeric precision to different denoising timesteps. We hypothesize that quantization errors accumulate additively across timesteps, which we then validate experimentally. Based on our observations, we develop an adaptive bisectioning-based algorithm, which assigns per-step precisions with linear evaluation complexity, reducing an otherwise exponential search problem. Across four state-of-the-art diffusion models and three datasets, TMPDiff consistently outperforms uniform-precision baselines at matched speedup, achieving 10 to 20% improvement in perceptual quality. On FLUX.1-dev, TMPDiff achieves 90% SSIM relative to the full-precision model at a speedup of 2.5x over 16-bit inference.
Optimization-Free Universal Watermark Forgery with Regenerative Diffusion Models
Jun 06, 2025Watermarking becomes one of the pivotal solutions to trace and verify the origin of synthetic images generated by artificial intelligence models, but it is not free of risks. Recent studies demonstrate the capability to forge watermarks from a target image onto cover images via adversarial optimization without knowledge of the target generative model and watermark schemes. In this paper, we uncover a greater risk of an optimization-free and universal watermark forgery that harnesses existing regenerative diffusion models. Our proposed forgery attack, PnP (Plug-and-Plant), seamlessly extracts and integrates the target watermark via regenerating the image, without needing any additional optimization routine. It allows for universal watermark forgery that works independently of the target image's origin or the watermarking model used. We explore the watermarked latent extracted from the target image and visual-textual context of cover images as priors to guide sampling of the regenerative process. Extensive evaluation on 24 scenarios of model-data-watermark combinations demonstrates that PnP can successfully forge the watermark (up to 100% detectability and user attribution), and maintain the best visual perception. By bypassing model retraining and enabling adaptability to any image, our approach significantly broadens the scope of forgery attacks, presenting a greater challenge to the security of current watermarking techniques for diffusion models and the authority of watermarking schemes in synthetic data generation and governance.
SFDDM: Single-fold Distillation for Diffusion models
May 23, 2024



While diffusion models effectively generate remarkable synthetic images, a key limitation is the inference inefficiency, requiring numerous sampling steps. To accelerate inference and maintain high-quality synthesis, teacher-student distillation is applied to compress the diffusion models in a progressive and binary manner by retraining, e.g., reducing the 1024-step model to a 128-step model in 3 folds. In this paper, we propose a single-fold distillation algorithm, SFDDM, which can flexibly compress the teacher diffusion model into a student model of any desired step, based on reparameterization of the intermediate inputs from the teacher model. To train the student diffusion, we minimize not only the output distance but also the distribution of the hidden variables between the teacher and student model. Extensive experiments on four datasets demonstrate that our student model trained by the proposed SFDDM is able to sample high-quality data with steps reduced to as little as approximately 1%, thus, trading off inference time. Our remarkable performance highlights that SFDDM effectively transfers knowledge in single-fold distillation, achieving semantic consistency and meaningful image interpolation.
DALLMi: Domain Adaption for LLM-based Multi-label Classifier
May 03, 2024Large language models (LLMs) increasingly serve as the backbone for classifying text associated with distinct domains and simultaneously several labels (classes). When encountering domain shifts, e.g., classifier of movie reviews from IMDb to Rotten Tomatoes, adapting such an LLM-based multi-label classifier is challenging due to incomplete label sets at the target domain and daunting training overhead. The existing domain adaptation methods address either image multi-label classifiers or text binary classifiers. In this paper, we design DALLMi, Domain Adaptation Large Language Model interpolator, a first-of-its-kind semi-supervised domain adaptation method for text data models based on LLMs, specifically BERT. The core of DALLMi is the novel variation loss and MixUp regularization, which jointly leverage the limited positively labeled and large quantity of unlabeled text and, importantly, their interpolation from the BERT word embeddings. DALLMi also introduces a label-balanced sampling strategy to overcome the imbalance between labeled and unlabeled data. We evaluate DALLMi against the partial-supervised and unsupervised approach on three datasets under different scenarios of label availability for the target domain. Our results show that DALLMi achieves higher mAP than unsupervised and partially-supervised approaches by 19.9% and 52.2%, respectively.
TabuLa: Harnessing Language Models for Tabular Data Synthesis
Oct 19, 2023



Given the ubiquitous use of tabular data in industries and the growing concerns in data privacy and security, tabular data synthesis emerges as a critical research area. The recent state-of-the-art methods show that large language models (LLMs) can be adopted to generate realistic tabular data. As LLMs pre-process tabular data as full text, they have the advantage of avoiding the curse of dimensionality associated with one-hot encoding high-dimensional data. However, their long training time and limited re-usability on new tasks prevent them from replacing exiting tabular generative models. In this paper, we propose Tabula, a tabular data synthesizer based on the language model structure. Through Tabula, we demonstrate the inherent limitation of employing pre-trained language models designed for natural language processing (NLP) in the context of tabular data synthesis. Our investigation delves into the development of a dedicated foundational model tailored specifically for tabular data synthesis. Additionally, we propose a token sequence compression strategy to significantly reduce training time while preserving the quality of synthetic data. Extensive experiments on six datasets demonstrate that using a language model structure without loading the well-trained model weights yields a better starting model for tabular data synthesis. Moreover, the Tabula model, previously trained on other tabular data, serves as an excellent foundation model for new tabular data synthesis tasks. Additionally, the token sequence compression method substantially reduces the model's training time. Results show that Tabula averagely reduces 46.2% training time per epoch comparing to current LLMs-based state-of-the-art algorithm and consistently achieves even higher synthetic data utility.
BatMan-CLR: Making Few-shots Meta-Learners Resilient Against Label Noise
Sep 12, 2023



The negative impact of label noise is well studied in classical supervised learning yet remains an open research question in meta-learning. Meta-learners aim to adapt to unseen learning tasks by learning a good initial model in meta-training and consecutively fine-tuning it according to new tasks during meta-testing. In this paper, we present the first extensive analysis of the impact of varying levels of label noise on the performance of state-of-the-art meta-learners, specifically gradient-based $N$-way $K$-shot learners. We show that the accuracy of Reptile, iMAML, and foMAML drops by up to 42% on the Omniglot and CifarFS datasets when meta-training is affected by label noise. To strengthen the resilience against label noise, we propose two sampling techniques, namely manifold (Man) and batch manifold (BatMan), which transform the noisy supervised learners into semi-supervised ones to increase the utility of noisy labels. We first construct manifold samples of $N$-way $2$-contrastive-shot tasks through augmentation, learning the embedding via a contrastive loss in meta-training, and then perform classification through zeroing on the embedding in meta-testing. We show that our approach can effectively mitigate the impact of meta-training label noise. Even with 60% wrong labels \batman and \man can limit the meta-testing accuracy drop to ${2.5}$, ${9.4}$, ${1.1}$ percent points, respectively, with existing meta-learners across the Omniglot, CifarFS, and MiniImagenet datasets.
A Survey on Deep Learning Hardware Accelerators for Heterogeneous HPC Platforms
Jun 27, 2023



Recent trends in deep learning (DL) imposed hardware accelerators as the most viable solution for several classes of high-performance computing (HPC) applications such as image classification, computer vision, and speech recognition. This survey summarizes and classifies the most recent advances in designing DL accelerators suitable to reach the performance requirements of HPC applications. In particular, it highlights the most advanced approaches to support deep learning accelerations including not only GPU and TPU-based accelerators but also design-specific hardware accelerators such as FPGA-based and ASIC-based accelerators, Neural Processing Units, open hardware RISC-V-based accelerators and co-processors. The survey also describes accelerators based on emerging memory technologies and computing paradigms, such as 3D-stacked Processor-In-Memory, non-volatile memories (mainly, Resistive RAM and Phase Change Memories) to implement in-memory computing, Neuromorphic Processing Units, and accelerators based on Multi-Chip Modules. The survey classifies the most influential architectures and technologies proposed in the last years, with the purpose of offering the reader a comprehensive perspective in the rapidly evolving field of deep learning. Finally, it provides some insights into future challenges in DL accelerators such as quantum accelerators and photonics.
Model-Agnostic Federated Learning
Mar 08, 2023Since its debut in 2016, Federated Learning (FL) has been tied to the inner workings of Deep Neural Networks (DNNs). On the one hand, this allowed its development and widespread use as DNNs proliferated. On the other hand, it neglected all those scenarios in which using DNNs is not possible or advantageous. The fact that most current FL frameworks only allow training DNNs reinforces this problem. To address the lack of FL solutions for non-DNN-based use cases, we propose MAFL (Model-Agnostic Federated Learning). MAFL marries a model-agnostic FL algorithm, AdaBoost.F, with an open industry-grade FL framework: Intel OpenFL. MAFL is the first FL system not tied to any specific type of machine learning model, allowing exploration of FL scenarios beyond DNNs and trees. We test MAFL from multiple points of view, assessing its correctness, flexibility and scaling properties up to 64 nodes. We optimised the base software achieving a 5.5x speedup on a standard FL scenario. MAFL is compatible with x86-64, ARM-v8, Power and RISC-V.
Experimenting with Emerging ARM and RISC-V Systems for Decentralised Machine Learning
Feb 15, 2023



Decentralised Machine Learning (DML) enables collaborative machine learning without centralised input data. Federated Learning (FL) and Edge Inference are examples of DML. While tools for DML (especially FL) are starting to flourish, many are not flexible and portable enough to experiment with novel systems (e.g., RISC-V), non-fully connected topologies, and asynchronous collaboration schemes. We overcome these limitations via a domain-specific language allowing to map DML schemes to an underlying middleware, i.e. the \ff parallel programming library. We experiment with it by generating different working DML schemes on two emerging architectures (ARM-v8, RISC-V) and the x86-64 platform. We characterise the performance and energy efficiency of the presented schemes and systems. As a byproduct, we introduce a RISC-V porting of the PyTorch framework, the first publicly available to our knowledge.
Permutation-Invariant Tabular Data Synthesis
Nov 17, 2022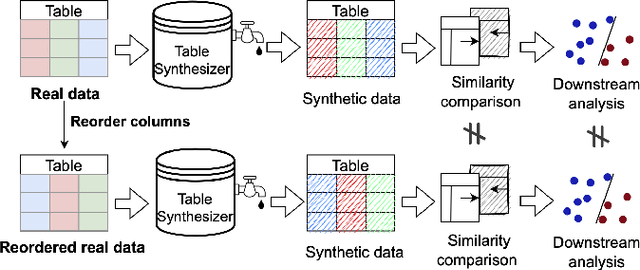
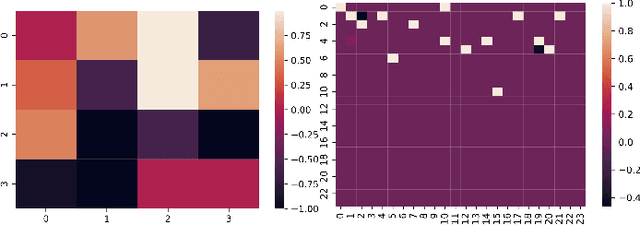
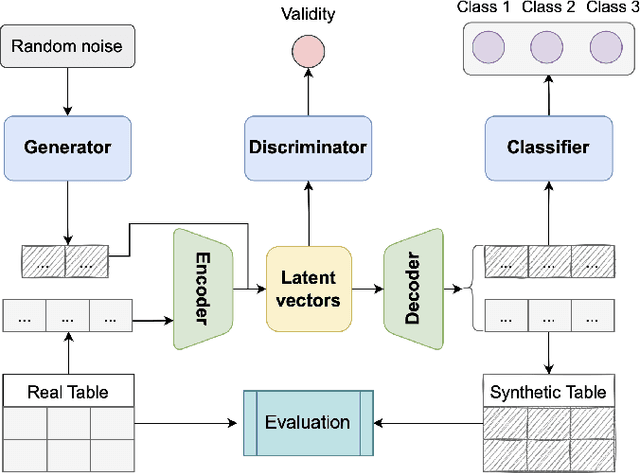
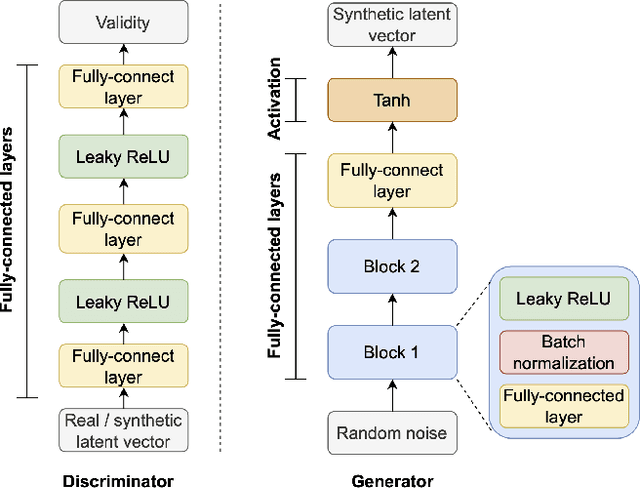
Tabular data synthesis is an emerging approach to circumvent strict regulations on data privacy while discovering knowledge through big data. Although state-of-the-art AI-based tabular data synthesizers, e.g., table-GAN, CTGAN, TVAE, and CTAB-GAN, are effective at generating synthetic tabular data, their training is sensitive to column permutations of input data. In this paper, we first conduct an extensive empirical study to disclose such a property of permutation invariance and an in-depth analysis of the existing synthesizers. We show that changing the input column order worsens the statistical difference between real and synthetic data by up to 38.67% due to the encoding of tabular data and the network architectures. To fully unleash the potential of big synthetic tabular data, we propose two solutions: (i) AE-GAN, a synthesizer that uses an autoencoder network to represent the tabular data and GAN networks to synthesize the latent representation, and (ii) a feature sorting algorithm to find the suitable column order of input data for CNN-based synthesizers. We evaluate the proposed solutions on five datasets in terms of the sensitivity to the column permutation, the quality of synthetic data, and the utility in downstream analyses. Our results show that we enhance the property of permutation-invariance when training synthesizers and further improve the quality and utility of synthetic data, up to 22%, compared to the existing synthesizers.