 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFederated Time Series Generation on Feature and Temporally Misaligned Data
Oct 28, 2024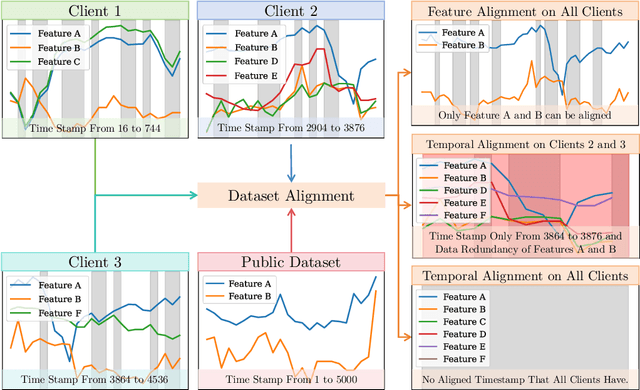

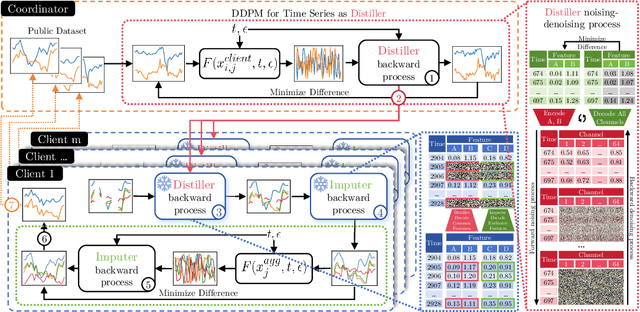
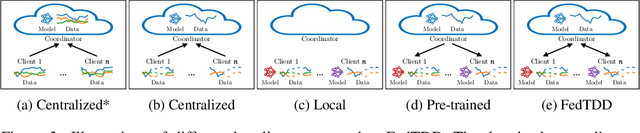
Distributed time series data presents a challenge for federated learning, as clients often possess different feature sets and have misaligned time steps. Existing federated time series models are limited by the assumption of perfect temporal or feature alignment across clients. In this paper, we propose FedTDD, a novel federated time series diffusion model that jointly learns a synthesizer across clients. At the core of FedTDD is a novel data distillation and aggregation framework that reconciles the differences between clients by imputing the misaligned timesteps and features. In contrast to traditional federated learning, FedTDD learns the correlation across clients' time series through the exchange of local synthetic outputs instead of model parameters. A coordinator iteratively improves a global distiller network by leveraging shared knowledge from clients through the exchange of synthetic data. As the distiller becomes more refined over time, it subsequently enhances the quality of the clients' local feature estimates, allowing each client to then improve its local imputations for missing data using the latest, more accurate distiller. Experimental results on five datasets demonstrate FedTDD's effectiveness compared to centralized training, and the effectiveness of sharing synthetic outputs to transfer knowledge of local time series. Notably, FedTDD achieves 79.4% and 62.8% improvement over local training in Context-FID and Correlational scores.
Asynchronous Byzantine Federated Learning
Jun 03, 2024Federated learning (FL) enables a set of geographically distributed clients to collectively train a model through a server. Classically, the training process is synchronous, but can be made asynchronous to maintain its speed in presence of slow clients and in heterogeneous networks. The vast majority of Byzantine fault-tolerant FL systems however rely on a synchronous training process. Our solution is one of the first Byzantine-resilient and asynchronous FL algorithms that does not require an auxiliary server dataset and is not delayed by stragglers, which are shortcomings of previous works. Intuitively, the server in our solution waits to receive a minimum number of updates from clients on its latest model to safely update it, and is later able to safely leverage the updates that late clients might send. We compare the performance of our solution with state-of-the-art algorithms on both image and text datasets under gradient inversion, perturbation, and backdoor attacks. Our results indicate that our solution trains a model faster than previous synchronous FL solution, and maintains a higher accuracy, up to 1.54x and up to 1.75x for perturbation and gradient inversion attacks respectively, in the presence of Byzantine clients than previous asynchronous FL solutions.
CCBNet: Confidential Collaborative Bayesian Networks Inference
May 23, 2024



Effective large-scale process optimization in manufacturing industries requires close cooperation between different human expert parties who encode their knowledge of related domains as Bayesian network models. For instance, Bayesian networks for domains such as lithography equipment, processes, and auxiliary tools must be conjointly used to effectively identify process optimizations in the semiconductor industry. However, business confidentiality across domains hinders such collaboration, and encourages alternatives to centralized inference. We propose CCBNet, the first Confidentiality-preserving Collaborative Bayesian Network inference framework. CCBNet leverages secret sharing to securely perform analysis on the combined knowledge of party models by joining two novel subprotocols: (i) CABN, which augments probability distributions for features across parties by modeling them into secret shares of their normalized combination; and (ii) SAVE, which aggregates party inference result shares through distributed variable elimination. We extensively evaluate CCBNet via 9 public Bayesian networks. Our results show that CCBNet achieves predictive quality that is similar to the ones of centralized methods while preserving model confidentiality. We further demonstrate that CCBNet scales to challenging manufacturing use cases that involve 16-128 parties in large networks of 223-1003 features, and decreases, on average, computational overhead by 23%, while communicating 71k values per request. Finally, we showcase possible attacks and mitigations for partially reconstructing party networks in the two subprotocols.
DALLMi: Domain Adaption for LLM-based Multi-label Classifier
May 03, 2024Large language models (LLMs) increasingly serve as the backbone for classifying text associated with distinct domains and simultaneously several labels (classes). When encountering domain shifts, e.g., classifier of movie reviews from IMDb to Rotten Tomatoes, adapting such an LLM-based multi-label classifier is challenging due to incomplete label sets at the target domain and daunting training overhead. The existing domain adaptation methods address either image multi-label classifiers or text binary classifiers. In this paper, we design DALLMi, Domain Adaptation Large Language Model interpolator, a first-of-its-kind semi-supervised domain adaptation method for text data models based on LLMs, specifically BERT. The core of DALLMi is the novel variation loss and MixUp regularization, which jointly leverage the limited positively labeled and large quantity of unlabeled text and, importantly, their interpolation from the BERT word embeddings. DALLMi also introduces a label-balanced sampling strategy to overcome the imbalance between labeled and unlabeled data. We evaluate DALLMi against the partial-supervised and unsupervised approach on three datasets under different scenarios of label availability for the target domain. Our results show that DALLMi achieves higher mAP than unsupervised and partially-supervised approaches by 19.9% and 52.2%, respectively.