 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDetecting Diffusion-Generated Time Series Under Generator Shift
May 27, 2026The boundary between real and diffusion-generated time series is becoming increasingly difficult to draw, yet detection in this domain remains underexplored, especially when the generator is unknown. We compare white-box detection, which requires access to the generator, against black-box detection, which operates on the raw signal alone. The white-box approach, a reconstruction-based detector adapted from the image domain, works well in in-distribution but breaks down under generator shift: reconstruction-based detection in images succeeds because large generic generators provide a near-universal reconstruction prior, and no analogous generator exists for time series. In contrast, a simple off-the-shelf classifier used as a black-box detector performs remarkably well, achieving an average F1 of 79.2, a 22.1% relative improvement over the white-box approach, and a TPR@1%FPR of 57.2. Diffusion-generated time series detection is therefore not a direct transfer of the image domain problem. This work provides the first systematic exploration of white-box and black-box detection for diffusion-generated time series. We close by identifying several open and promising directions.
CCBNet: Confidential Collaborative Bayesian Networks Inference
May 23, 2024



Effective large-scale process optimization in manufacturing industries requires close cooperation between different human expert parties who encode their knowledge of related domains as Bayesian network models. For instance, Bayesian networks for domains such as lithography equipment, processes, and auxiliary tools must be conjointly used to effectively identify process optimizations in the semiconductor industry. However, business confidentiality across domains hinders such collaboration, and encourages alternatives to centralized inference. We propose CCBNet, the first Confidentiality-preserving Collaborative Bayesian Network inference framework. CCBNet leverages secret sharing to securely perform analysis on the combined knowledge of party models by joining two novel subprotocols: (i) CABN, which augments probability distributions for features across parties by modeling them into secret shares of their normalized combination; and (ii) SAVE, which aggregates party inference result shares through distributed variable elimination. We extensively evaluate CCBNet via 9 public Bayesian networks. Our results show that CCBNet achieves predictive quality that is similar to the ones of centralized methods while preserving model confidentiality. We further demonstrate that CCBNet scales to challenging manufacturing use cases that involve 16-128 parties in large networks of 223-1003 features, and decreases, on average, computational overhead by 23%, while communicating 71k values per request. Finally, we showcase possible attacks and mitigations for partially reconstructing party networks in the two subprotocols.
DALLMi: Domain Adaption for LLM-based Multi-label Classifier
May 03, 2024Large language models (LLMs) increasingly serve as the backbone for classifying text associated with distinct domains and simultaneously several labels (classes). When encountering domain shifts, e.g., classifier of movie reviews from IMDb to Rotten Tomatoes, adapting such an LLM-based multi-label classifier is challenging due to incomplete label sets at the target domain and daunting training overhead. The existing domain adaptation methods address either image multi-label classifiers or text binary classifiers. In this paper, we design DALLMi, Domain Adaptation Large Language Model interpolator, a first-of-its-kind semi-supervised domain adaptation method for text data models based on LLMs, specifically BERT. The core of DALLMi is the novel variation loss and MixUp regularization, which jointly leverage the limited positively labeled and large quantity of unlabeled text and, importantly, their interpolation from the BERT word embeddings. DALLMi also introduces a label-balanced sampling strategy to overcome the imbalance between labeled and unlabeled data. We evaluate DALLMi against the partial-supervised and unsupervised approach on three datasets under different scenarios of label availability for the target domain. Our results show that DALLMi achieves higher mAP than unsupervised and partially-supervised approaches by 19.9% and 52.2%, respectively.
SiloFuse: Cross-silo Synthetic Data Generation with Latent Tabular Diffusion Models
Apr 04, 2024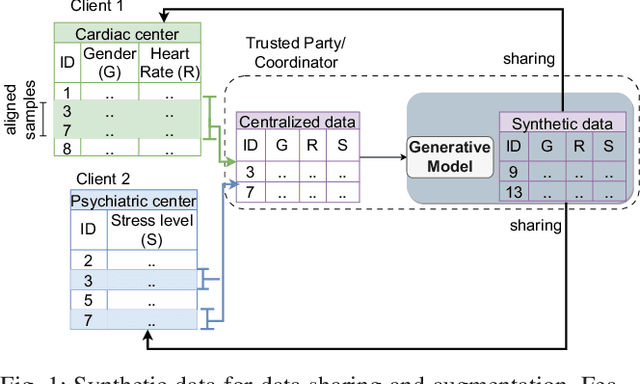
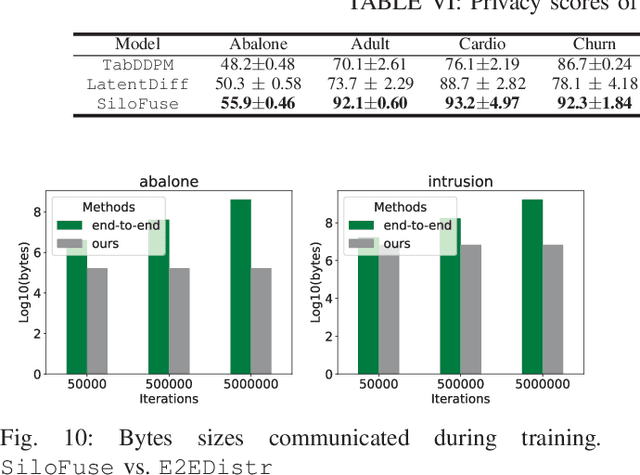
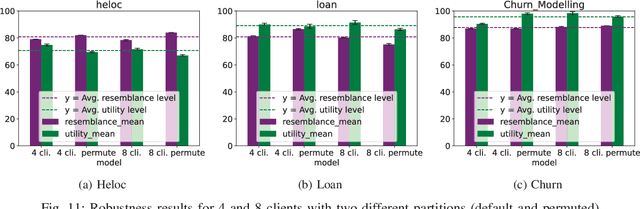
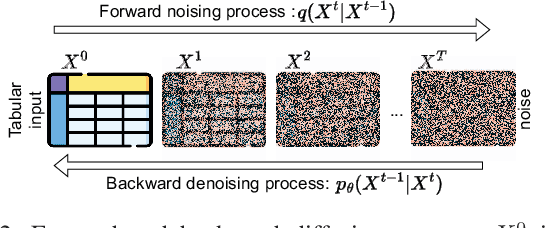
Synthetic tabular data is crucial for sharing and augmenting data across silos, especially for enterprises with proprietary data. However, existing synthesizers are designed for centrally stored data. Hence, they struggle with real-world scenarios where features are distributed across multiple silos, necessitating on-premise data storage. We introduce SiloFuse, a novel generative framework for high-quality synthesis from cross-silo tabular data. To ensure privacy, SiloFuse utilizes a distributed latent tabular diffusion architecture. Through autoencoders, latent representations are learned for each client's features, masking their actual values. We employ stacked distributed training to improve communication efficiency, reducing the number of rounds to a single step. Under SiloFuse, we prove the impossibility of data reconstruction for vertically partitioned synthesis and quantify privacy risks through three attacks using our benchmark framework. Experimental results on nine datasets showcase SiloFuse's competence against centralized diffusion-based synthesizers. Notably, SiloFuse achieves 43.8 and 29.8 higher percentage points over GANs in resemblance and utility. Experiments on communication show stacked training's fixed cost compared to the growing costs of end-to-end training as the number of training iterations increases. Additionally, SiloFuse proves robust to feature permutations and varying numbers of clients.
TabuLa: Harnessing Language Models for Tabular Data Synthesis
Oct 19, 2023



Given the ubiquitous use of tabular data in industries and the growing concerns in data privacy and security, tabular data synthesis emerges as a critical research area. The recent state-of-the-art methods show that large language models (LLMs) can be adopted to generate realistic tabular data. As LLMs pre-process tabular data as full text, they have the advantage of avoiding the curse of dimensionality associated with one-hot encoding high-dimensional data. However, their long training time and limited re-usability on new tasks prevent them from replacing exiting tabular generative models. In this paper, we propose Tabula, a tabular data synthesizer based on the language model structure. Through Tabula, we demonstrate the inherent limitation of employing pre-trained language models designed for natural language processing (NLP) in the context of tabular data synthesis. Our investigation delves into the development of a dedicated foundational model tailored specifically for tabular data synthesis. Additionally, we propose a token sequence compression strategy to significantly reduce training time while preserving the quality of synthetic data. Extensive experiments on six datasets demonstrate that using a language model structure without loading the well-trained model weights yields a better starting model for tabular data synthesis. Moreover, the Tabula model, previously trained on other tabular data, serves as an excellent foundation model for new tabular data synthesis tasks. Additionally, the token sequence compression method substantially reduces the model's training time. Results show that Tabula averagely reduces 46.2% training time per epoch comparing to current LLMs-based state-of-the-art algorithm and consistently achieves even higher synthetic data utility.
ComicGAN: Text-to-Comic Generative Adversarial Network
Sep 19, 2021


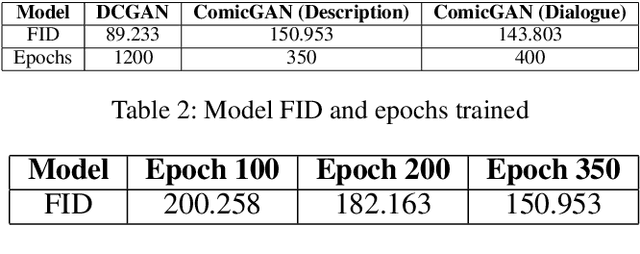
Drawing and annotating comic illustrations is a complex and difficult process. No existing machine learning algorithms have been developed to create comic illustrations based on descriptions of illustrations, or the dialogue in comics. Moreover, it is not known if a generative adversarial network (GAN) can generate original comics that correspond to the dialogue and/or descriptions. GANs are successful in producing photo-realistic images, but this technology does not necessarily translate to generation of flawless comics. What is more, comic evaluation is a prominent challenge as common metrics such as Inception Score will not perform comparably, as they are designed to work on photos. In this paper: 1. We implement ComicGAN, a novel text-to-comic pipeline based on a text-to-image GAN that synthesizes comics according to text descriptions. 2. We describe an in-depth empirical study of the technical difficulties of comic generation using GAN's. ComicGAN has two novel features: (i) text description creation from labels via permutation and augmentation, and (ii) custom image encoding with Convolutional Neural Networks. We extensively evaluate the proposed ComicGAN in two scenarios, namely image generation from descriptions, and image generation from dialogue. Our results on 1000 Dilbert comic panels and 6000 descriptions show synthetic comic panels from text inputs resemble original Dilbert panels. Novel methods for text description creation and custom image encoding brought improvements to Frechet Inception Distance, detail, and overall image quality over baseline algorithms. Generating illustrations from descriptions provided clear comics including characters and colours that were specified in the descriptions.
DTGAN: Differential Private Training for Tabular GANs
Aug 02, 2021


Tabular generative adversarial networks (TGAN) have recently emerged to cater to the need of synthesizing tabular data -- the most widely used data format. While synthetic tabular data offers the advantage of complying with privacy regulations, there still exists a risk of privacy leakage via inference attacks due to interpolating the properties of real data during training. Differential private (DP) training algorithms provide theoretical guarantees for training machine learning models by injecting statistical noise to prevent privacy leaks. However, the challenges of applying DP on TGAN are to determine the most optimal framework (i.e., PATE/DP-SGD) and neural network (i.e., Generator/Discriminator)to inject noise such that the data utility is well maintained under a given privacy guarantee. In this paper, we propose DTGAN, a novel conditional Wasserstein tabular GAN that comes in two variants DTGAN_G and DTGAN_D, for providing a detailed comparison of tabular GANs trained using DP-SGD for the generator vs discriminator, respectively. We elicit the privacy analysis associated with training the generator with complex loss functions (i.e., classification and information losses) needed for high quality tabular data synthesis. Additionally, we rigorously evaluate the theoretical privacy guarantees offered by DP empirically against membership and attribute inference attacks. Our results on 3 datasets show that the DP-SGD framework is superior to PATE and that a DP discriminator is more optimal for training convergence. Thus, we find (i) DTGAN_D is capable of maintaining the highest data utility across 4 ML models by up to 18% in terms of the average precision score for a strict privacy budget, epsilon = 1, as compared to the prior studies and (ii) DP effectively prevents privacy loss against inference attacks by restricting the success probability of membership attacks to be close to 50%.