 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIMLP: An Energy-Efficient Continual Learning Method for Tabular Data Streams
Oct 06, 2025Tabular data streams are rapidly emerging as a dominant modality for real-time decision-making in healthcare, finance, and the Internet of Things (IoT). These applications commonly run on edge and mobile devices, where energy budgets, memory, and compute are strictly limited. Continual learning (CL) addresses such dynamics by training models sequentially on task streams while preserving prior knowledge and consolidating new knowledge. While recent CL work has advanced in mitigating catastrophic forgetting and improving knowledge transfer, the practical requirements of energy and memory efficiency for tabular data streams remain underexplored. In particular, existing CL solutions mostly depend on replay mechanisms whose buffers grow over time and exacerbate resource costs. We propose a context-aware incremental Multi-Layer Perceptron (IMLP), a compact continual learner for tabular data streams. IMLP incorporates a windowed scaled dot-product attention over a sliding latent feature buffer, enabling constant-size memory and avoiding storing raw data. The attended context is concatenated with current features and processed by shared feed-forward layers, yielding lightweight per-segment updates. To assess practical deployability, we introduce NetScore-T, a tunable metric coupling balanced accuracy with energy for Pareto-aware comparison across models and datasets. IMLP achieves up to $27.6\times$ higher energy efficiency than TabNet and $85.5\times$ higher than TabPFN, while maintaining competitive average accuracy. Overall, IMLP provides an easy-to-deploy, energy-efficient alternative to full retraining for tabular data streams.
WaveStitch: Flexible and Fast Conditional Time Series Generation with Diffusion Models
Mar 08, 2025



Generating temporal data under constraints is critical for forecasting, imputation, and synthesis. These datasets often include auxiliary conditions that influence the values within the time series signal. Existing methods face three key challenges: (1) they fail to adapt to conditions at inference time; (2) they rely on sequential generation, which slows the generation speed; and (3) they inefficiently encode categorical features, leading to increased sparsity and input sizes. We propose WaveStitch, a novel method that addresses these challenges by leveraging denoising diffusion probabilistic models to efficiently generate accurate temporal data under given auxiliary constraints. WaveStitch overcomes these limitations by: (1) modeling interactions between constraints and signals to generalize to new, unseen conditions; (2) enabling the parallel synthesis of sequential segments with a novel "stitching" mechanism to enforce coherence across segments; and (3) encoding categorical features as compact periodic signals while preserving temporal patterns. Extensive evaluations across diverse datasets highlight WaveStitch's ability to generalize to unseen conditions during inference, achieving up to a 10x lower mean-squared-error compared to the state-of-the-art methods. Moreover, WaveStitch generates data up to 460x faster than autoregressive methods while maintaining comparable accuracy. By efficiently encoding categorical features, WaveStitch provides a robust and efficient solution for temporal data generation. Our code is open-sourced: https://github.com/adis98/HierarchicalTS
Accessible and Portable LLM Inference by Compiling Computational Graphs into SQL
Feb 05, 2025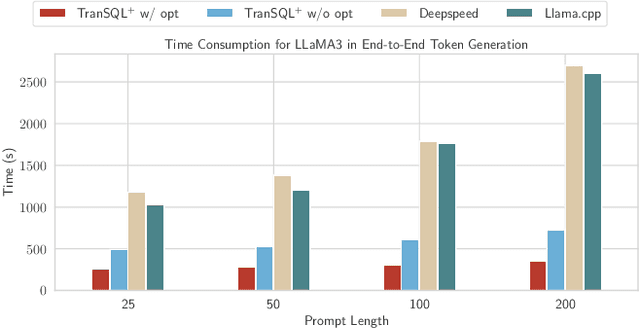
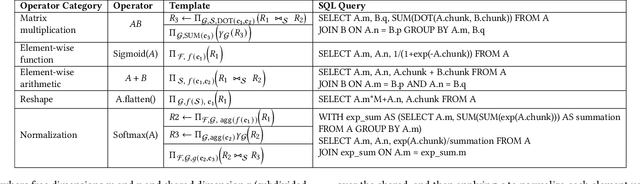
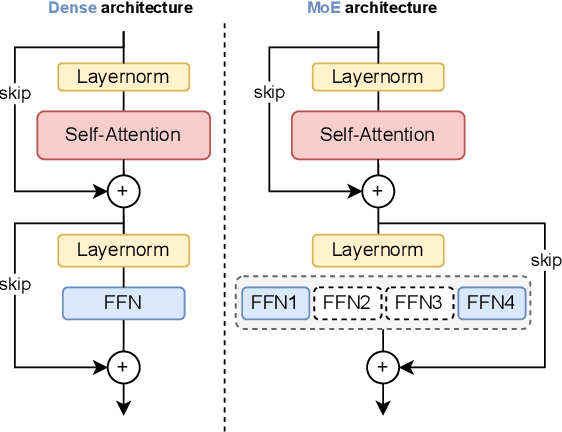
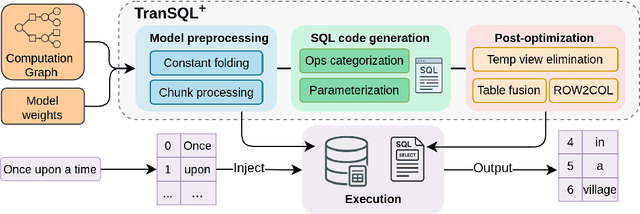
Serving large language models (LLMs) often demands specialized hardware, dedicated frameworks, and substantial development efforts, which restrict their accessibility, especially for edge devices and organizations with limited technical resources. We propose a novel compiler that translates LLM inference graphs into SQL queries, enabling relational databases, one of the most widely used and mature software systems globally, to serve as the runtime. By mapping neural operators such as matrix multiplication and attention into relational primitives like joins and aggregations, our approach leverages database capabilities, including disk-based data management and native caching. Supporting key transformer components, such as attention mechanisms and key-value caching, our system generates SQL pipelines for end-to-end LLM inference. Using the Llama3 family as a case study, we demonstrate up to 30x speedup in token generation for memory-constrained scenarios comparable to competitive CPU-based frameworks. Our work offers an accessible, portable, and efficient solution, facilitating the serving of LLMs across diverse deployment environments.
Ilargi: a GPU Compatible Factorized ML Model Training Framework
Feb 04, 2025The machine learning (ML) training over disparate data sources traditionally involves materialization, which can impose substantial time and space overhead due to data movement and replication. Factorized learning, which leverages direct computation on disparate sources through linear algebra (LA) rewriting, has emerged as a viable alternative to improve computational efficiency. However, the adaptation of factorized learning to leverage the full capabilities of modern LA-friendly hardware like GPUs has been limited, often requiring manual intervention for algorithm compatibility. This paper introduces Ilargi, a novel factorized learning framework that utilizes matrix-represented data integration (DI) metadata to facilitate automatic factorization across CPU and GPU environments without the need for costly relational joins. Ilargi incorporates an ML-based cost estimator to intelligently selects between factorization and materialization based on data properties, algorithm complexity, hardware environments, and their interactions. This strategy ensures up to 8.9x speedups on GPUs and achieves over 20% acceleration in batch ML training workloads, thereby enhancing the practicability of ML training across diverse data integration scenarios and hardware platforms. To our knowledge, this work is the very first effort in GPU-compatible factorized learning.
LLM-PQA: LLM-enhanced Prediction Query Answering
Sep 02, 2024



The advent of Large Language Models (LLMs) provides an opportunity to change the way queries are processed, moving beyond the constraints of conventional SQL-based database systems. However, using an LLM to answer a prediction query is still challenging, since an external ML model has to be employed and inference has to be performed in order to provide an answer. This paper introduces LLM-PQA, a novel tool that addresses prediction queries formulated in natural language. LLM-PQA is the first to combine the capabilities of LLMs and retrieval-augmented mechanism for the needs of prediction queries by integrating data lakes and model zoos. This integration provides users with access to a vast spectrum of heterogeneous data and diverse ML models, facilitating dynamic prediction query answering. In addition, LLM-PQA can dynamically train models on demand, based on specific query requirements, ensuring reliable and relevant results even when no pre-trained model in a model zoo, available for the task.
Share Your Secrets for Privacy! Confidential Forecasting with Vertical Federated Learning
May 31, 2024Vertical federated learning (VFL) is a promising area for time series forecasting in industrial applications, such as predictive maintenance and machine control. Critical challenges to address in manufacturing include data privacy and over-fitting on small and noisy datasets during both training and inference. Additionally, to increase industry adaptability, such forecasting models must scale well with the number of parties while ensuring strong convergence and low-tuning complexity. We address those challenges and propose 'Secret-shared Time Series Forecasting with VFL' (STV), a novel framework that exhibits the following key features: i) a privacy-preserving algorithm for forecasting with SARIMAX and autoregressive trees on vertically partitioned data; ii) serverless forecasting using secret sharing and multi-party computation; iii) novel N-party algorithms for matrix multiplication and inverse operations for direct parameter optimization, giving strong convergence with minimal hyperparameter tuning complexity. We conduct evaluations on six representative datasets from public and industry-specific contexts. Our results demonstrate that STV's forecasting accuracy is comparable to those of centralized approaches. They also show that our direct optimization can outperform centralized methods, which include state-of-the-art diffusion models and long-short-term memory, by 23.81% on forecasting accuracy. We also conduct a scalability analysis by examining the communication costs of direct and iterative optimization to navigate the choice between the two. Code and appendix are available: https://github.com/adis98/STV
Model Selection with Model Zoo via Graph Learning
Apr 05, 2024



Pre-trained deep learning (DL) models are increasingly accessible in public repositories, i.e., model zoos. Given a new prediction task, finding the best model to fine-tune can be computationally intensive and costly, especially when the number of pre-trained models is large. Selecting the right pre-trained models is crucial, yet complicated by the diversity of models from various model families (like ResNet, Vit, Swin) and the hidden relationships between models and datasets. Existing methods, which utilize basic information from models and datasets to compute scores indicating model performance on target datasets, overlook the intrinsic relationships, limiting their effectiveness in model selection. In this study, we introduce TransferGraph, a novel framework that reformulates model selection as a graph learning problem. TransferGraph constructs a graph using extensive metadata extracted from models and datasets, while capturing their inherent relationships. Through comprehensive experiments across 16 real datasets, both images and texts, we demonstrate TransferGraph's effectiveness in capturing essential model-dataset relationships, yielding up to a 32% improvement in correlation between predicted performance and the actual fine-tuning results compared to the state-of-the-art methods.
SiloFuse: Cross-silo Synthetic Data Generation with Latent Tabular Diffusion Models
Apr 04, 2024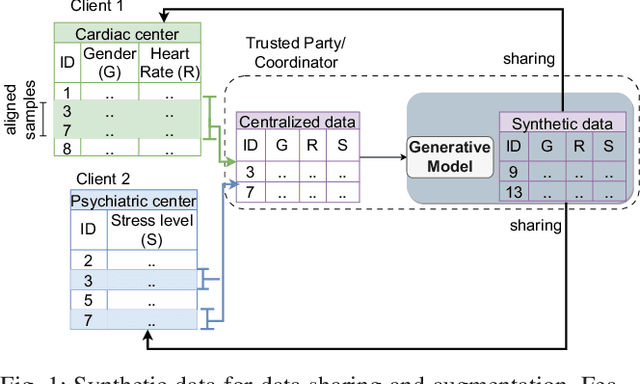
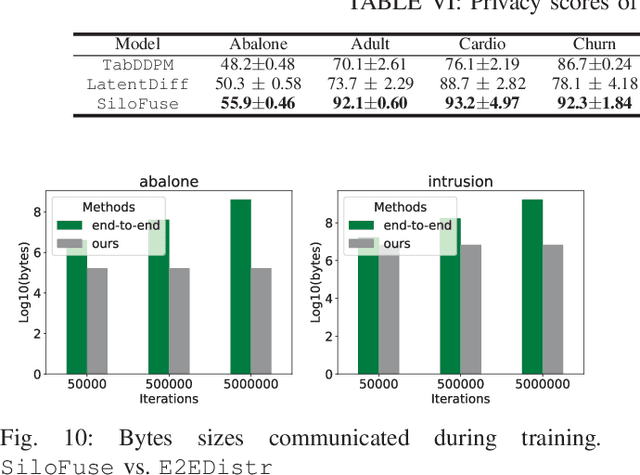
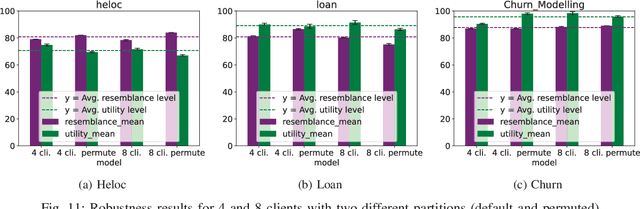
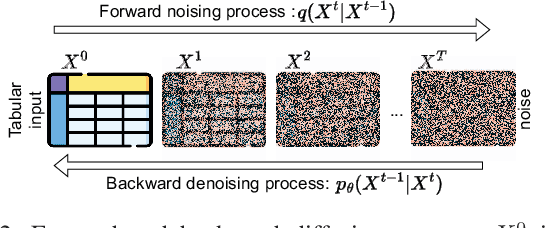
Synthetic tabular data is crucial for sharing and augmenting data across silos, especially for enterprises with proprietary data. However, existing synthesizers are designed for centrally stored data. Hence, they struggle with real-world scenarios where features are distributed across multiple silos, necessitating on-premise data storage. We introduce SiloFuse, a novel generative framework for high-quality synthesis from cross-silo tabular data. To ensure privacy, SiloFuse utilizes a distributed latent tabular diffusion architecture. Through autoencoders, latent representations are learned for each client's features, masking their actual values. We employ stacked distributed training to improve communication efficiency, reducing the number of rounds to a single step. Under SiloFuse, we prove the impossibility of data reconstruction for vertically partitioned synthesis and quantify privacy risks through three attacks using our benchmark framework. Experimental results on nine datasets showcase SiloFuse's competence against centralized diffusion-based synthesizers. Notably, SiloFuse achieves 43.8 and 29.8 higher percentage points over GANs in resemblance and utility. Experiments on communication show stacked training's fixed cost compared to the growing costs of end-to-end training as the number of training iterations increases. Additionally, SiloFuse proves robust to feature permutations and varying numbers of clients.
Metadata Representations for Queryable ML Model Zoos
Jul 19, 2022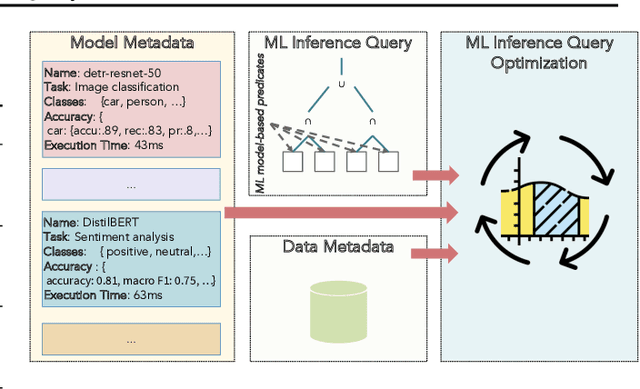
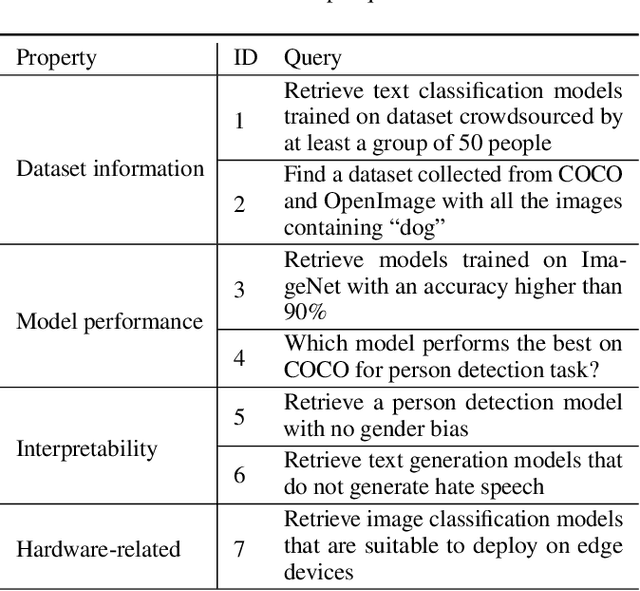
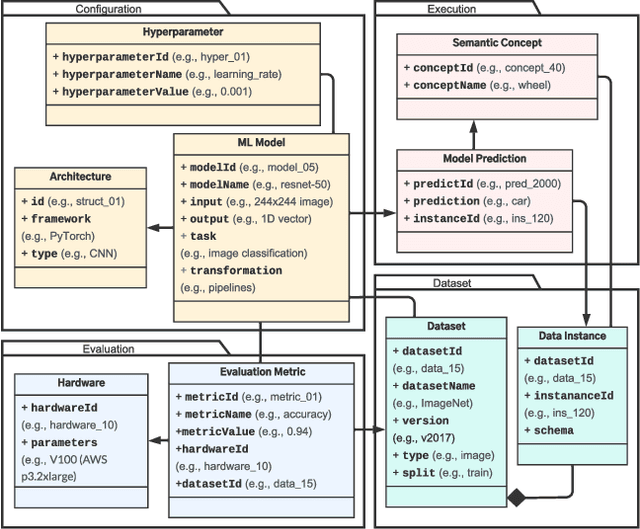
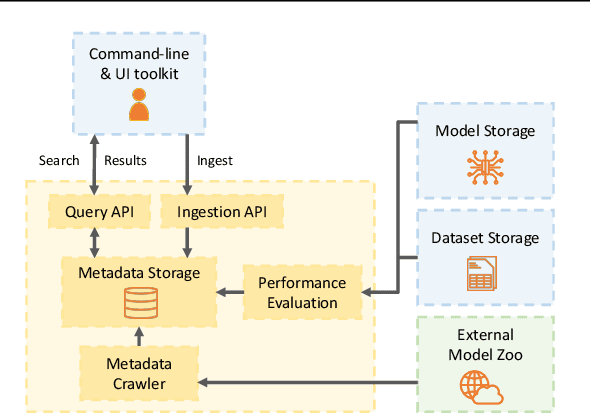
Machine learning (ML) practitioners and organizations are building model zoos of pre-trained models, containing metadata describing properties of the ML models and datasets that are useful for reporting, auditing, reproducibility, and interpretability purposes. The metatada is currently not standardised; its expressivity is limited; and there is no interoperable way to store and query it. Consequently, model search, reuse, comparison, and composition are hindered. In this paper, we advocate for standardized ML model meta-data representation and management, proposing a toolkit supported to help practitioners manage and query that metadata.