 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCounterfactual Training: Teaching Models Plausible and Actionable Explanations
Jan 22, 2026We propose a novel training regime termed counterfactual training that leverages counterfactual explanations to increase the explanatory capacity of models. Counterfactual explanations have emerged as a popular post-hoc explanation method for opaque machine learning models: they inform how factual inputs would need to change in order for a model to produce some desired output. To be useful in real-world decision-making systems, counterfactuals should be plausible with respect to the underlying data and actionable with respect to the feature mutability constraints. Much existing research has therefore focused on developing post-hoc methods to generate counterfactuals that meet these desiderata. In this work, we instead hold models directly accountable for the desired end goal: counterfactual training employs counterfactuals during the training phase to minimize the divergence between learned representations and plausible, actionable explanations. We demonstrate empirically and theoretically that our proposed method facilitates training models that deliver inherently desirable counterfactual explanations and additionally exhibit improved adversarial robustness.
Model See, Model Do? Exposure-Aware Evaluation of Bug-vs-Fix Preference in Code LLMs
Jan 15, 2026Large language models are increasingly used for code generation and debugging, but their outputs can still contain bugs, that originate from training data. Distinguishing whether an LLM prefers correct code, or a familiar incorrect version might be influenced by what it's been exposed to during training. We introduce an exposure-aware evaluation framework that quantifies how prior exposure to buggy versus fixed code influences a model's preference. Using the ManySStuBs4J benchmark, we apply Data Portraits for membership testing on the Stack-V2 corpus to estimate whether each buggy and fixed variant was seen during training. We then stratify examples by exposure and compare model preference using code completion as well as multiple likelihood-based scoring metrics We find that most examples (67%) have neither variant in the training data, and when only one is present, fixes are more frequently present than bugs. In model generations, models reproduce buggy lines far more often than fixes, with bug-exposed examples amplifying this tendency and fix-exposed examples showing only marginal improvement. In likelihood scoring, minimum and maximum token-probability metrics consistently prefer the fixed code across all conditions, indicating a stable bias toward correct fixes. In contrast, metrics like the Gini coefficient reverse preference when only the buggy variant was seen. Our results indicate that exposure can skew bug-fix evaluations and highlight the risk that LLMs may propagate memorised errors in practice.
A Qualitative Investigation into LLM-Generated Multilingual Code Comments and Automatic Evaluation Metrics
May 21, 2025Large Language Models are essential coding assistants, yet their training is predominantly English-centric. In this study, we evaluate the performance of code language models in non-English contexts, identifying challenges in their adoption and integration into multilingual workflows. We conduct an open-coding study to analyze errors in code comments generated by five state-of-the-art code models, CodeGemma, CodeLlama, CodeQwen1.5, GraniteCode, and StarCoder2 across five natural languages: Chinese, Dutch, English, Greek, and Polish. Our study yields a dataset of 12,500 labeled generations, which we publicly release. We then assess the reliability of standard metrics in capturing comment \textit{correctness} across languages and evaluate their trustworthiness as judgment criteria. Through our open-coding investigation, we identified a taxonomy of 26 distinct error categories in model-generated code comments. They highlight variations in language cohesion, informativeness, and syntax adherence across different natural languages. Our analysis shows that, while these models frequently produce partially correct comments, modern neural metrics fail to reliably differentiate meaningful completions from random noise. Notably, the significant score overlap between expert-rated correct and incorrect comments calls into question the effectiveness of these metrics in assessing generated comments.
Code Red! On the Harmfulness of Applying Off-the-shelf Large Language Models to Programming Tasks
Apr 02, 2025Nowadays, developers increasingly rely on solutions powered by Large Language Models (LLM) to assist them with their coding tasks. This makes it crucial to align these tools with human values to prevent malicious misuse. In this paper, we propose a comprehensive framework for assessing the potential harmfulness of LLMs within the software engineering domain. We begin by developing a taxonomy of potentially harmful software engineering scenarios and subsequently, create a dataset of prompts based on this taxonomy. To systematically assess the responses, we design and validate an automatic evaluator that classifies the outputs of a variety of LLMs both open-source and closed-source models, as well as general-purpose and code-specific LLMs. Furthermore, we investigate the impact of models size, architecture family, and alignment strategies on their tendency to generate harmful content. The results show significant disparities in the alignment of various LLMs for harmlessness. We find that some models and model families, such as Openhermes, are more harmful than others and that code-specific models do not perform better than their general-purpose counterparts. Notably, some fine-tuned models perform significantly worse than their base-models due to their design choices. On the other side, we find that larger models tend to be more helpful and are less likely to respond with harmful information. These results highlight the importance of targeted alignment strategies tailored to the unique challenges of software engineering tasks and provide a foundation for future work in this critical area.
WaveStitch: Flexible and Fast Conditional Time Series Generation with Diffusion Models
Mar 08, 2025



Generating temporal data under constraints is critical for forecasting, imputation, and synthesis. These datasets often include auxiliary conditions that influence the values within the time series signal. Existing methods face three key challenges: (1) they fail to adapt to conditions at inference time; (2) they rely on sequential generation, which slows the generation speed; and (3) they inefficiently encode categorical features, leading to increased sparsity and input sizes. We propose WaveStitch, a novel method that addresses these challenges by leveraging denoising diffusion probabilistic models to efficiently generate accurate temporal data under given auxiliary constraints. WaveStitch overcomes these limitations by: (1) modeling interactions between constraints and signals to generalize to new, unseen conditions; (2) enabling the parallel synthesis of sequential segments with a novel "stitching" mechanism to enforce coherence across segments; and (3) encoding categorical features as compact periodic signals while preserving temporal patterns. Extensive evaluations across diverse datasets highlight WaveStitch's ability to generalize to unseen conditions during inference, achieving up to a 10x lower mean-squared-error compared to the state-of-the-art methods. Moreover, WaveStitch generates data up to 460x faster than autoregressive methods while maintaining comparable accuracy. By efficiently encoding categorical features, WaveStitch provides a robust and efficient solution for temporal data generation. Our code is open-sourced: https://github.com/adis98/HierarchicalTS
The Heap: A Contamination-Free Multilingual Code Dataset for Evaluating Large Language Models
Jan 16, 2025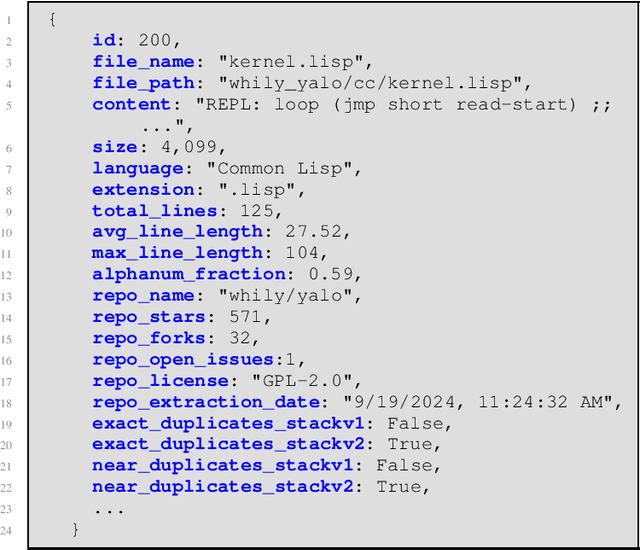
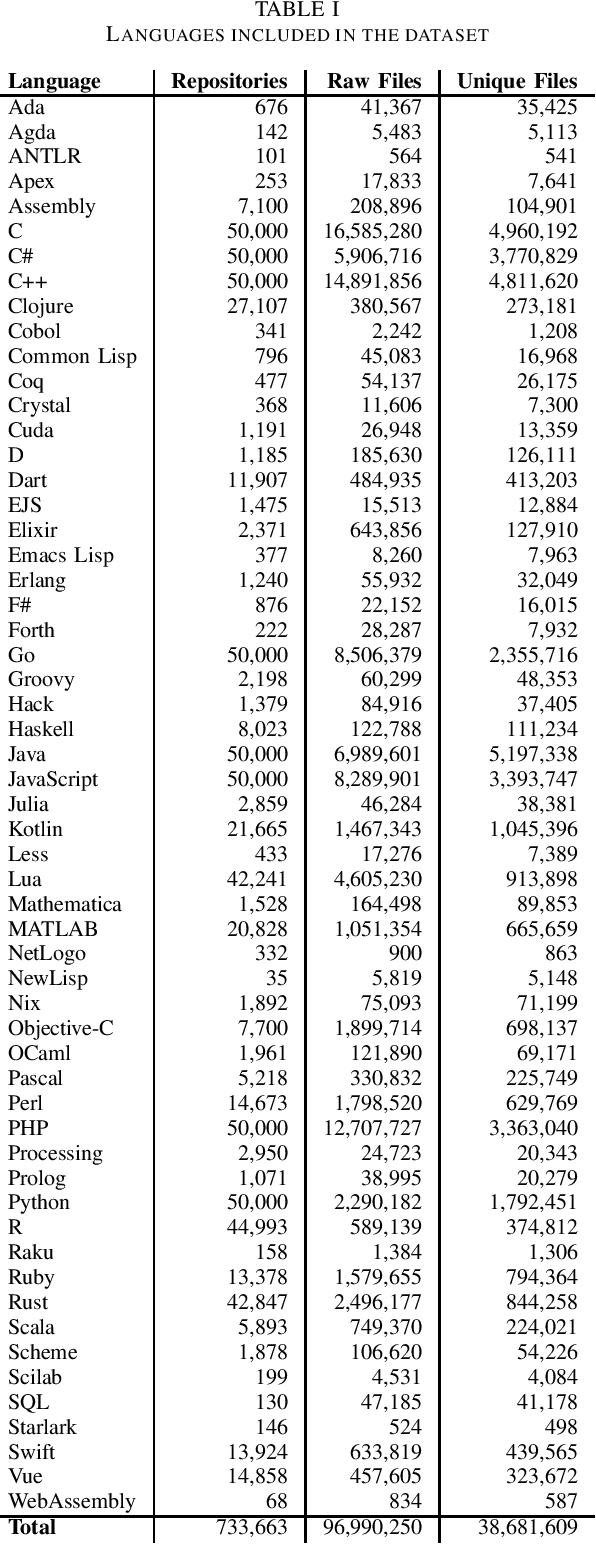
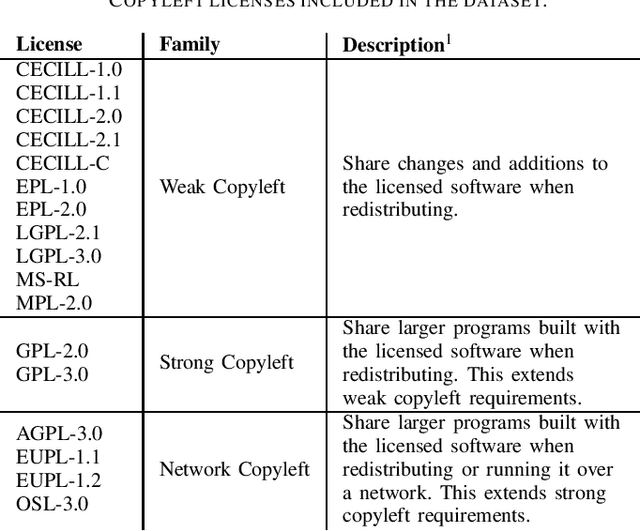

The recent rise in the popularity of large language models has spurred the development of extensive code datasets needed to train them. This has left limited code available for collection and use in the downstream investigation of specific behaviors, or evaluation of large language models without suffering from data contamination. To address this problem, we release The Heap, a large multilingual dataset covering 57 programming languages that has been deduplicated with respect to other open datasets of code, enabling researchers to conduct fair evaluations of large language models without significant data cleaning overhead.
Long Code Arena: a Set of Benchmarks for Long-Context Code Models
Jun 17, 2024



Nowadays, the fields of code and natural language processing are evolving rapidly. In particular, models become better at processing long context windows - supported context sizes have increased by orders of magnitude over the last few years. However, there is a shortage of benchmarks for code processing that go beyond a single file of context, while the most popular ones are limited to a single method. With this work, we aim to close this gap by introducing Long Code Arena, a suite of six benchmarks for code processing tasks that require project-wide context. These tasks cover different aspects of code processing: library-based code generation, CI builds repair, project-level code completion, commit message generation, bug localization, and module summarization. For each task, we provide a manually verified dataset for testing, an evaluation suite, and open-source baseline solutions based on popular LLMs to showcase the usage of the dataset and to simplify adoption by other researchers. We publish the benchmark page on HuggingFace Spaces with the leaderboard, links to HuggingFace Hub for all the datasets, and link to the GitHub repository with baselines: https://huggingface.co/spaces/JetBrains-Research/long-code-arena.
A Transformer-Based Approach for Smart Invocation of Automatic Code Completion
May 23, 2024



Transformer-based language models are highly effective for code completion, with much research dedicated to enhancing the content of these completions. Despite their effectiveness, these models come with high operational costs and can be intrusive, especially when they suggest too often and interrupt developers who are concentrating on their work. Current research largely overlooks how these models interact with developers in practice and neglects to address when a developer should receive completion suggestions. To tackle this issue, we developed a machine learning model that can accurately predict when to invoke a code completion tool given the code context and available telemetry data. To do so, we collect a dataset of 200k developer interactions with our cross-IDE code completion plugin and train several invocation filtering models. Our results indicate that our small-scale transformer model significantly outperforms the baseline while maintaining low enough latency. We further explore the search space for integrating additional telemetry data into a pre-trained transformer directly and obtain promising results. To further demonstrate our approach's practical potential, we deployed the model in an online environment with 34 developers and provided real-world insights based on 74k actual invocations.
An Exploratory Investigation into Code License Infringements in Large Language Model Training Datasets
Mar 22, 2024

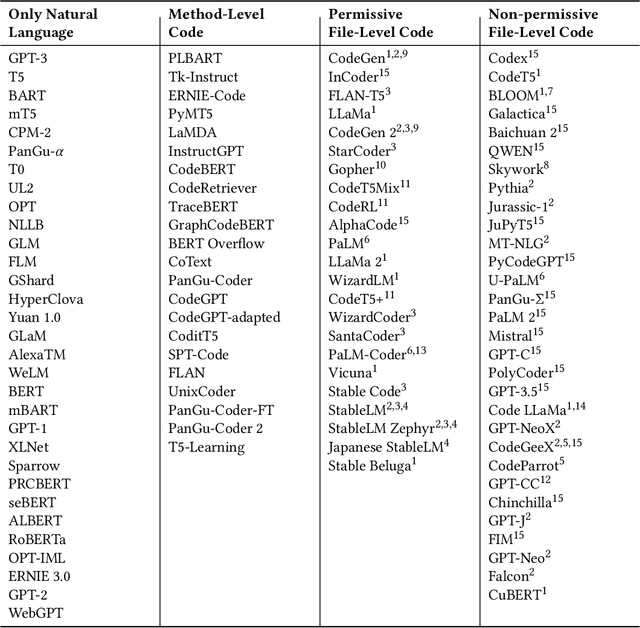
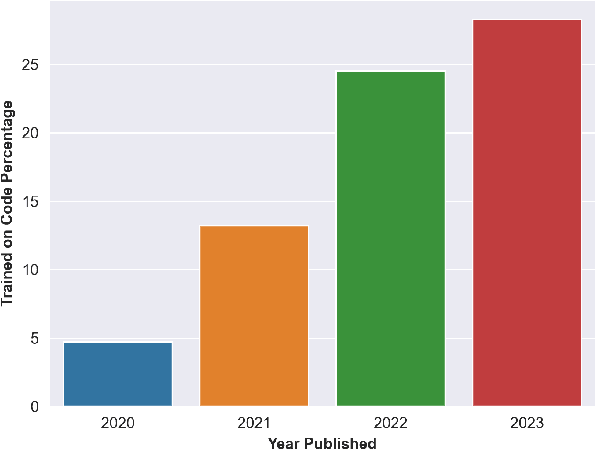
Does the training of large language models potentially infringe upon code licenses? Furthermore, are there any datasets available that can be safely used for training these models without violating such licenses? In our study, we assess the current trends in the field and the importance of incorporating code into the training of large language models. Additionally, we examine publicly available datasets to see whether these models can be trained on them without the risk of legal issues in the future. To accomplish this, we compiled a list of 53 large language models trained on file-level code. We then extracted their datasets and analyzed how much they overlap with a dataset we created, consisting exclusively of strong copyleft code. Our analysis revealed that every dataset we examined contained license inconsistencies, despite being selected based on their associated repository licenses. We analyzed a total of 514 million code files, discovering 38 million exact duplicates present in our strong copyleft dataset. Additionally, we examined 171 million file-leading comments, identifying 16 million with strong copyleft licenses and another 11 million comments that discouraged copying without explicitly mentioning a license. Based on the findings of our study, which highlights the pervasive issue of license inconsistencies in large language models trained on code, our recommendation for both researchers and the community is to prioritize the development and adoption of best practices for dataset creation and management.
Language Models for Code Completion: A Practical Evaluation
Feb 25, 2024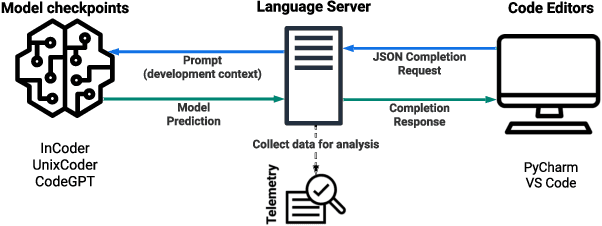
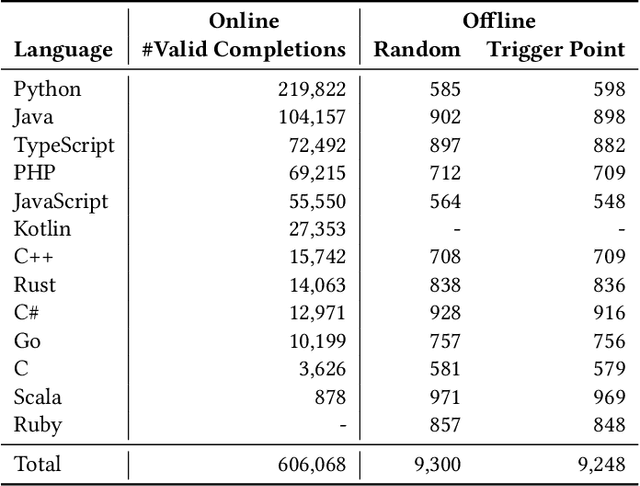
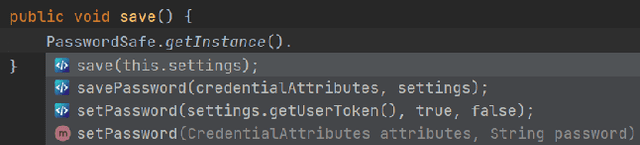

Transformer-based language models for automatic code completion have shown great promise so far, yet the evaluation of these models rarely uses real data. This study provides both quantitative and qualitative assessments of three public code language models when completing real-world code. We first developed an open-source IDE extension, Code4Me, for the online evaluation of the models. We collected real auto-completion usage data for over a year from more than 1200 users, resulting in over 600K valid completions. These models were then evaluated using six standard metrics across twelve programming languages. Next, we conducted a qualitative study of 1690 real-world completion requests to identify the reasons behind the poor model performance. A comparative analysis of the models' performance in online and offline settings was also performed, using benchmark synthetic datasets and two masking strategies. Our findings suggest that while developers utilize code completion across various languages, the best results are achieved for mainstream languages such as Python and Java. InCoder outperformed the other models across all programming languages, highlighting the significance of training data and objectives. Our study also revealed that offline evaluations do not accurately reflect real-world scenarios. Upon qualitative analysis of the model's predictions, we found that 66.3% of failures were due to the models' limitations, 24.4% occurred due to inappropriate model usage in a development context, and 9.3% were valid requests that developers overwrote. Given these findings, we propose several strategies to overcome the current limitations. These include refining training objectives, improving resilience to typographical errors, adopting hybrid approaches, and enhancing implementations and usability.