 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnvBench: A Benchmark for Automated Environment Setup
Mar 18, 2025
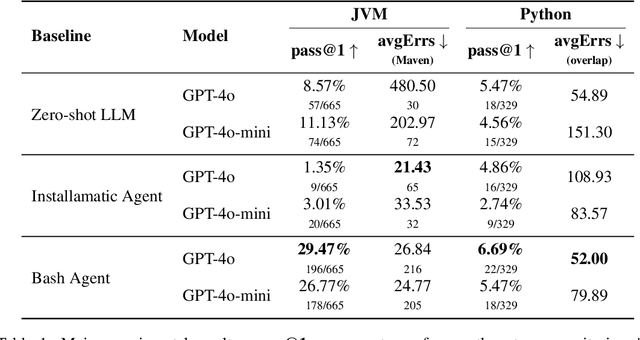
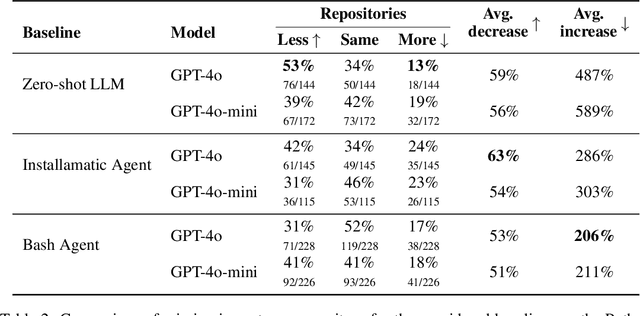
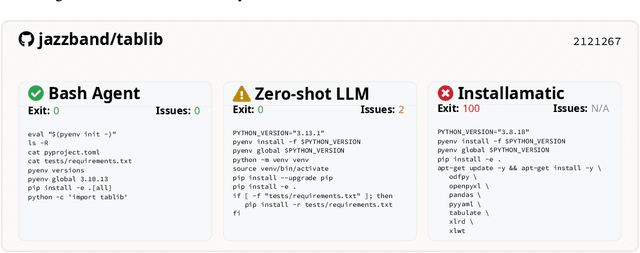
Recent advances in Large Language Models (LLMs) have enabled researchers to focus on practical repository-level tasks in software engineering domain. In this work, we consider a cornerstone task for automating work with software repositories-environment setup, i.e., a task of configuring a repository-specific development environment on a system. Existing studies on environment setup introduce innovative agentic strategies, but their evaluation is often based on small datasets that may not capture the full range of configuration challenges encountered in practice. To address this gap, we introduce a comprehensive environment setup benchmark EnvBench. It encompasses 329 Python and 665 JVM-based (Java, Kotlin) repositories, with a focus on repositories that present genuine configuration challenges, excluding projects that can be fully configured by simple deterministic scripts. To enable further benchmark extension and usage for model tuning, we implement two automatic metrics: a static analysis check for missing imports in Python and a compilation check for JVM languages. We demonstrate the applicability of our benchmark by evaluating three environment setup approaches, including a simple zero-shot baseline and two agentic workflows, that we test with two powerful LLM backbones, GPT-4o and GPT-4o-mini. The best approach manages to successfully configure 6.69% repositories for Python and 29.47% repositories for JVM, suggesting that EnvBench remains challenging for current approaches. Our benchmark suite is publicly available at https://github.com/JetBrains-Research/EnvBench. The dataset and experiment trajectories are available at https://jb.gg/envbench.
Long Code Arena: a Set of Benchmarks for Long-Context Code Models
Jun 17, 2024



Nowadays, the fields of code and natural language processing are evolving rapidly. In particular, models become better at processing long context windows - supported context sizes have increased by orders of magnitude over the last few years. However, there is a shortage of benchmarks for code processing that go beyond a single file of context, while the most popular ones are limited to a single method. With this work, we aim to close this gap by introducing Long Code Arena, a suite of six benchmarks for code processing tasks that require project-wide context. These tasks cover different aspects of code processing: library-based code generation, CI builds repair, project-level code completion, commit message generation, bug localization, and module summarization. For each task, we provide a manually verified dataset for testing, an evaluation suite, and open-source baseline solutions based on popular LLMs to showcase the usage of the dataset and to simplify adoption by other researchers. We publish the benchmark page on HuggingFace Spaces with the leaderboard, links to HuggingFace Hub for all the datasets, and link to the GitHub repository with baselines: https://huggingface.co/spaces/JetBrains-Research/long-code-arena.
On The Importance of Reasoning for Context Retrieval in Repository-Level Code Editing
Jun 06, 2024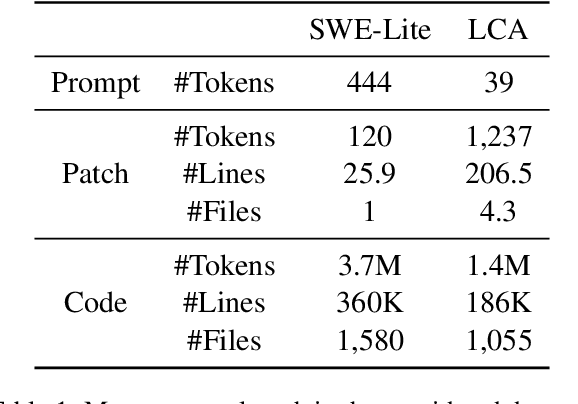
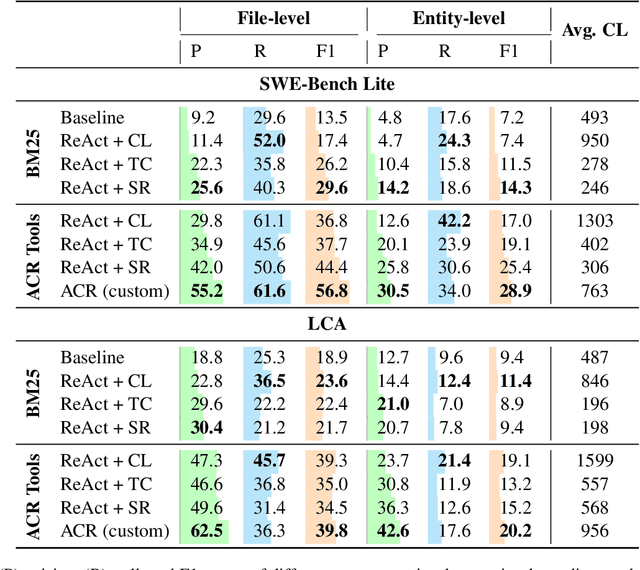
Recent advancements in code-fluent Large Language Models (LLMs) enabled the research on repository-level code editing. In such tasks, the model navigates and modifies the entire codebase of a project according to request. Hence, such tasks require efficient context retrieval, i.e., navigating vast codebases to gather relevant context. Despite the recognized importance of context retrieval, existing studies tend to approach repository-level coding tasks in an end-to-end manner, rendering the impact of individual components within these complicated systems unclear. In this work, we decouple the task of context retrieval from the other components of the repository-level code editing pipelines. We lay the groundwork to define the strengths and weaknesses of this component and the role that reasoning plays in it by conducting experiments that focus solely on context retrieval. We conclude that while the reasoning helps to improve the precision of the gathered context, it still lacks the ability to identify its sufficiency. We also outline the ultimate role of the specialized tools in the process of context gathering. The code supplementing this paper is available at https://github.com/JetBrains-Research/ai-agents-code-editing.