 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnderstanding Student Interaction with AI-Powered Next-Step Hints: Strategies and Challenges
Nov 09, 2025Automated feedback generation plays a crucial role in enhancing personalized learning experiences in computer science education. Among different types of feedback, next-step hint feedback is particularly important, as it provides students with actionable steps to progress towards solving programming tasks. This study investigates how students interact with an AI-driven next-step hint system in an in-IDE learning environment. We gathered and analyzed a dataset from 34 students solving Kotlin tasks, containing detailed hint interaction logs. We applied process mining techniques and identified 16 common interaction scenarios. Semi-structured interviews with 6 students revealed strategies for managing unhelpful hints, such as adapting partial hints or modifying code to generate variations of the same hint. These findings, combined with our publicly available dataset, offer valuable opportunities for future research and provide key insights into student behavior, helping improve hint design for enhanced learning support.
Diff-XYZ: A Benchmark for Evaluating Diff Understanding
Oct 14, 2025Reliable handling of code diffs is central to agents that edit and refactor repositories at scale. We introduce Diff-XYZ, a compact benchmark for code-diff understanding with three supervised tasks: apply (old code $+$ diff $\rightarrow$ new code), anti-apply (new code $-$ diff $\rightarrow$ old code), and diff generation (new code $-$ old code $\rightarrow$ diff). Instances in the benchmark are triples $\langle \textit{old code}, \textit{new code}, \textit{diff} \rangle$ drawn from real commits in CommitPackFT, paired with automatic metrics and a clear evaluation protocol. We use the benchmark to do a focused empirical study of the unified diff format and run a cross-format comparison of different diff representations. Our findings reveal that different formats should be used depending on the use case and model size. For example, representing diffs in search-replace format is good for larger models in the diff generation scenario, yet not suited well for diff analysis and smaller models. The Diff-XYZ benchmark is a reusable foundation for assessing and improving diff handling in LLMs that can aid future development of diff formats and models editing code. The dataset is published on HuggingFace Hub: https://huggingface.co/datasets/JetBrains-Research/diff-xyz.
Challenge on Optimization of Context Collection for Code Completion
Oct 05, 2025



The rapid advancement of workflows and methods for software engineering using AI emphasizes the need for a systematic evaluation and analysis of their ability to leverage information from entire projects, particularly in large code bases. In this challenge on optimization of context collection for code completion, organized by JetBrains in collaboration with Mistral AI as part of the ASE 2025 conference, participants developed efficient mechanisms for collecting context from source code repositories to improve fill-in-the-middle code completions for Python and Kotlin. We constructed a large dataset of real-world code in these two programming languages using permissively licensed open-source projects. The submissions were evaluated based on their ability to maximize completion quality for multiple state-of-the-art neural models using the chrF metric. During the public phase of the competition, nineteen teams submitted solutions to the Python track and eight teams submitted solutions to the Kotlin track. In the private phase, six teams competed, of which five submitted papers to the workshop.
Stack Trace Deduplication: Faster, More Accurately, and in More Realistic Scenarios
Dec 19, 2024



In large-scale software systems, there are often no fully-fledged bug reports with human-written descriptions when an error occurs. In this case, developers rely on stack traces, i.e., series of function calls that led to the error. Since there can be tens and hundreds of thousands of them describing the same issue from different users, automatic deduplication into categories is necessary to allow for processing. Recent works have proposed powerful deep learning-based approaches for this, but they are evaluated and compared in isolation from real-life workflows, and it is not clear whether they will actually work well at scale. To overcome this gap, this work presents three main contributions: a novel model, an industry-based dataset, and a multi-faceted evaluation. Our model consists of two parts - (1) an embedding model with byte-pair encoding and approximate nearest neighbor search to quickly find the most relevant stack traces to the incoming one, and (2) a reranker that re-ranks the most fitting stack traces, taking into account the repeated frames between them. To complement the existing datasets collected from open-source projects, we share with the community SlowOps - a dataset of stack traces from IntelliJ-based products developed by JetBrains, which has an order of magnitude more stack traces per category. Finally, we carry out an evaluation that strives to be realistic: measuring not only the accuracy of categorization, but also the operation time and the ability to create new categories. The evaluation shows that our model strikes a good balance - it outperforms other models on both open-source datasets and SlowOps, while also being faster on time than most. We release all of our code and data, and hope that our work can pave the way to further practice-oriented research in the area.
Drawing Pandas: A Benchmark for LLMs in Generating Plotting Code
Dec 03, 2024This paper introduces the human-curated PandasPlotBench dataset, designed to evaluate language models' effectiveness as assistants in visual data exploration. Our benchmark focuses on generating code for visualizing tabular data - such as a Pandas DataFrame - based on natural language instructions, complementing current evaluation tools and expanding their scope. The dataset includes 175 unique tasks. Our experiments assess several leading Large Language Models (LLMs) across three visualization libraries: Matplotlib, Seaborn, and Plotly. We show that the shortening of tasks has a minimal effect on plotting capabilities, allowing for the user interface that accommodates concise user input without sacrificing functionality or accuracy. Another of our findings reveals that while LLMs perform well with popular libraries like Matplotlib and Seaborn, challenges persist with Plotly, highlighting areas for improvement. We hope that the modular design of our benchmark will broaden the current studies on generating visualizations. Our benchmark is available online: https://huggingface.co/datasets/JetBrains-Research/plot_bench. The code for running the benchmark is also available: https://github.com/JetBrains-Research/PandasPlotBench.
Towards Realistic Evaluation of Commit Message Generation by Matching Online and Offline Settings
Oct 15, 2024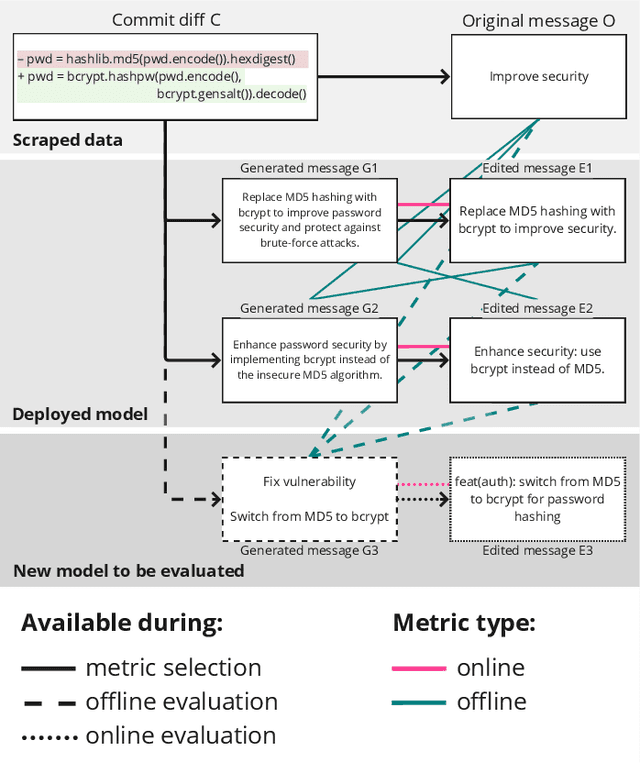
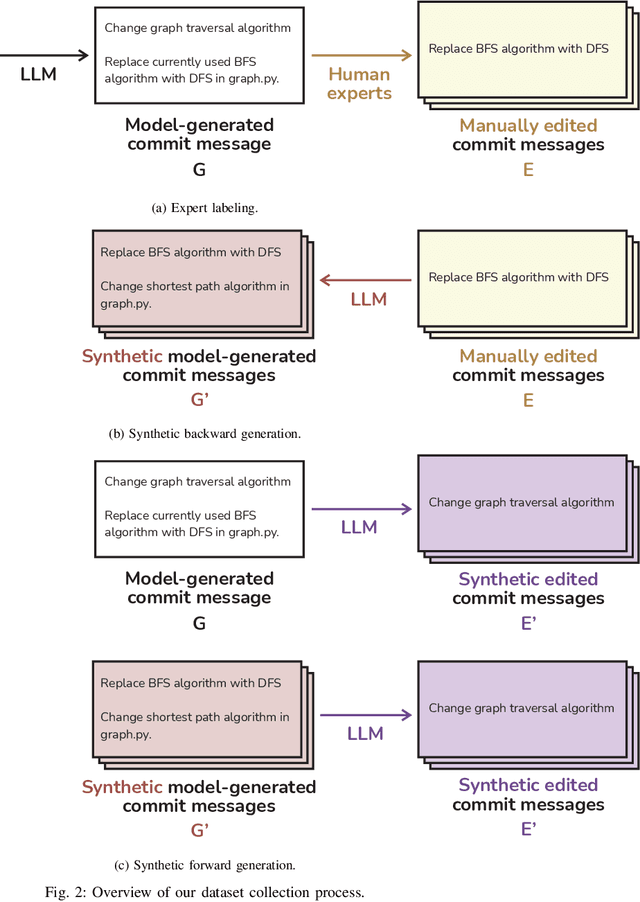
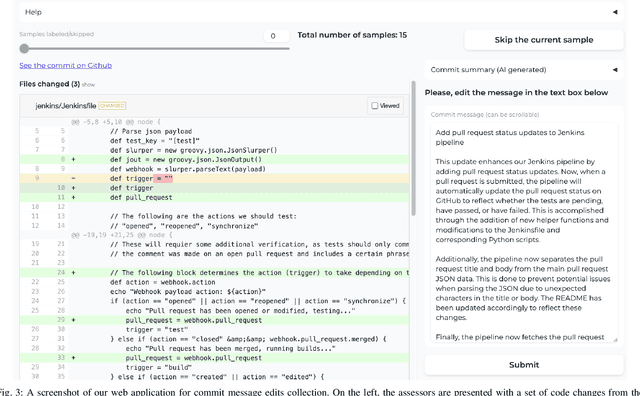
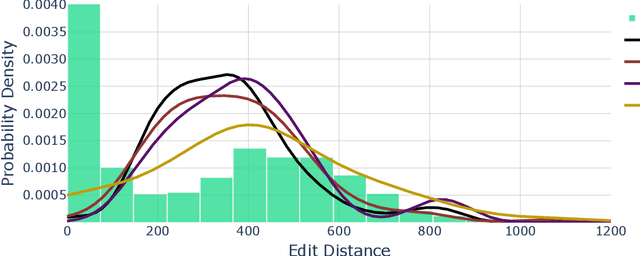
Commit message generation (CMG) is a crucial task in software engineering that is challenging to evaluate correctly. When a CMG system is integrated into the IDEs and other products at JetBrains, we perform online evaluation based on user acceptance of the generated messages. However, performing online experiments with every change to a CMG system is troublesome, as each iteration affects users and requires time to collect enough statistics. On the other hand, offline evaluation, a prevalent approach in the research literature, facilitates fast experiments but employs automatic metrics that are not guaranteed to represent the preferences of real users. In this work, we describe a novel way we employed to deal with this problem at JetBrains, by leveraging an online metric - the number of edits users introduce before committing the generated messages to the VCS - to select metrics for offline experiments. To support this new type of evaluation, we develop a novel markup collection tool mimicking the real workflow with a CMG system, collect a dataset with 57 pairs consisting of commit messages generated by GPT-4 and their counterparts edited by human experts, and design and verify a way to synthetically extend such a dataset. Then, we use the final dataset of 656 pairs to study how the widely used similarity metrics correlate with the online metric reflecting the real users' experience. Our results indicate that edit distance exhibits the highest correlation, whereas commonly used similarity metrics such as BLEU and METEOR demonstrate low correlation. This contradicts the previous studies on similarity metrics for CMG, suggesting that user interactions with a CMG system in real-world settings differ significantly from the responses by human labelers operating within controlled research environments. We release all the code and the dataset for researchers: https://jb.gg/cmg-evaluation.
One Step at a Time: Combining LLMs and Static Analysis to Generate Next-Step Hints for Programming Tasks
Oct 11, 2024



Students often struggle with solving programming problems when learning to code, especially when they have to do it online, with one of the most common disadvantages of working online being the lack of personalized help. This help can be provided as next-step hint generation, i.e., showing a student what specific small step they need to do next to get to the correct solution. There are many ways to generate such hints, with large language models (LLMs) being among the most actively studied right now. While LLMs constitute a promising technology for providing personalized help, combining them with other techniques, such as static analysis, can significantly improve the output quality. In this work, we utilize this idea and propose a novel system to provide both textual and code hints for programming tasks. The pipeline of the proposed approach uses a chain-of-thought prompting technique and consists of three distinct steps: (1) generating subgoals - a list of actions to proceed with the task from the current student's solution, (2) generating the code to achieve the next subgoal, and (3) generating the text to describe this needed action. During the second step, we apply static analysis to the generated code to control its size and quality. The tool is implemented as a modification to the open-source JetBrains Academy plugin, supporting students in their in-IDE courses. To evaluate our approach, we propose a list of criteria for all steps in our pipeline and conduct two rounds of expert validation. Finally, we evaluate the next-step hints in a classroom with 14 students from two universities. Our results show that both forms of the hints - textual and code - were helpful for the students, and the proposed system helped them to proceed with the coding tasks.
Long Code Arena: a Set of Benchmarks for Long-Context Code Models
Jun 17, 2024



Nowadays, the fields of code and natural language processing are evolving rapidly. In particular, models become better at processing long context windows - supported context sizes have increased by orders of magnitude over the last few years. However, there is a shortage of benchmarks for code processing that go beyond a single file of context, while the most popular ones are limited to a single method. With this work, we aim to close this gap by introducing Long Code Arena, a suite of six benchmarks for code processing tasks that require project-wide context. These tasks cover different aspects of code processing: library-based code generation, CI builds repair, project-level code completion, commit message generation, bug localization, and module summarization. For each task, we provide a manually verified dataset for testing, an evaluation suite, and open-source baseline solutions based on popular LLMs to showcase the usage of the dataset and to simplify adoption by other researchers. We publish the benchmark page on HuggingFace Spaces with the leaderboard, links to HuggingFace Hub for all the datasets, and link to the GitHub repository with baselines: https://huggingface.co/spaces/JetBrains-Research/long-code-arena.
Using AI-Based Coding Assistants in Practice: State of Affairs, Perceptions, and Ways Forward
Jun 11, 2024The last several years saw the emergence of AI assistants for code -- multi-purpose AI-based helpers in software engineering. Their quick development makes it necessary to better understand how specifically developers are using them, why they are not using them in certain parts of their development workflow, and what needs to be improved. In this work, we carried out a large-scale survey aimed at how AI assistants are used, focusing on specific software development activities and stages. We collected opinions of 481 programmers on five broad activities: (a) implementing new features, (b) writing tests, (c) bug triaging, (d) refactoring, and (e) writing natural-language artifacts, as well as their individual stages. Our results show that usage of AI assistants varies depending on activity and stage. For instance, developers find writing tests and natural-language artifacts to be the least enjoyable activities and want to delegate them the most, currently using AI assistants to generate tests and test data, as well as generating comments and docstrings most of all. This can be a good focus for features aimed to help developers right now. As for why developers do not use assistants, in addition to general things like trust and company policies, there are fixable issues that can serve as a guide for further research, e.g., the lack of project-size context, and lack of awareness about assistants. We believe that our comprehensive and specific results are especially needed now to steer active research toward where users actually need AI assistants.
Full Line Code Completion: Bringing AI to Desktop
May 14, 2024



In recent years, several industrial solutions for the problem of multi-token code completion have appeared, each making a great advance in the area but mostly focusing on cloud-based runtime and avoiding working on the end user's device. In this work, we describe our approach for building a multi-token code completion feature for the JetBrains' IntelliJ Platform, which we call Full Line Code Completion. The feature suggests only syntactically correct code and works fully locally, i.e., data querying and the generation of suggestions happens on the end user's machine. We share important time and memory-consumption restrictions, as well as design principles that a code completion engine should satisfy. Working entirely on the end user's device, our code completion engine enriches user experience while being not only fast and compact but also secure. We share a number of useful techniques to meet the stated development constraints and also describe offline and online evaluation pipelines that allowed us to make better decisions. Our online evaluation shows that the usage of the tool leads to 1.5 times more code in the IDE being produced by code completion. The described solution was initially started with the help of researchers and was bundled into two JetBrains' IDEs - PyCharm Pro and DataSpell - at the end of 2023, so we believe that this work is useful for bridging academia and industry, providing researchers with the knowledge of what happens when complex research-based solutions are integrated into real products.