 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Agent Coordinated Rename Refactoring
Jan 01, 2026The primary value of AI agents in software development lies in their ability to extend the developer's capacity for reasoning and action, not to supplant human involvement. To showcase how to use agents working in tandem with developers, we designed a novel approach for carrying out coordinated renaming. Coordinated renaming, where a single rename refactoring triggers refactorings in multiple, related identifiers, is a frequent yet challenging task. Developers must manually propagate these rename refactorings across numerous files and contexts, a process that is both tedious and highly error-prone. State-of-the-art heuristic-based approaches produce an overwhelming number of false positives, while vanilla Large Language Models (LLMs) provide incomplete suggestions due to their limited context and inability to interact with refactoring tools. This leaves developers with incomplete refactorings or burdens them with filtering too many false positives. Coordinated renaming is exactly the kind of repetitive task that agents can significantly reduce the developers' burden while keeping them in the driver's seat. We designed, implemented, and evaluated the first multi-agent framework that automates coordinated renaming. It operates on a key insight: a developer's initial refactoring is a clue to infer the scope of related refactorings. Our Scope Inference Agent first transforms this clue into an explicit, natural-language Declared Scope. The Planned Execution Agent then uses this as a strict plan to identify program elements that should undergo refactoring and safely executes the changes by invoking the IDE's own trusted refactoring APIs. Finally, the Replication Agent uses it to guide the project-wide search. We first conducted a formative study on the practice of coordinated renaming in 609K commits in 100 open-source projects and surveyed 205 developers ...
Debug Smarter, Not Harder: AI Agents for Error Resolution in Computational Notebooks
Oct 18, 2024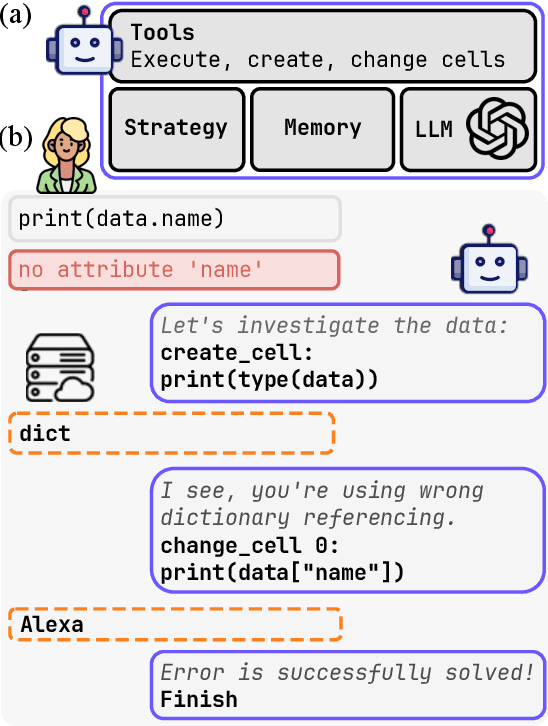
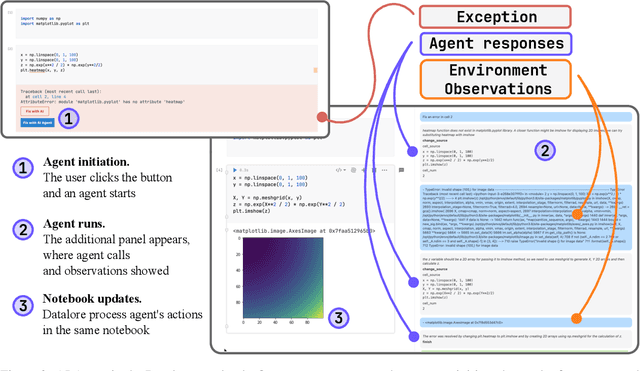
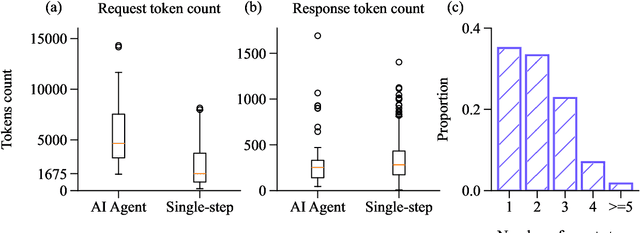
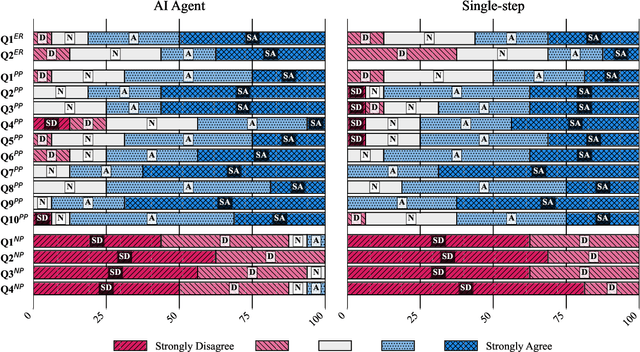
Computational notebooks became indispensable tools for research-related development, offering unprecedented interactivity and flexibility in the development process. However, these benefits come at the cost of reproducibility and an increased potential for bugs. With the rise of code-fluent Large Language Models empowered with agentic techniques, smart bug-fixing tools with a high level of autonomy have emerged. However, those tools are tuned for classical script programming and still struggle with non-linear computational notebooks. In this paper, we present an AI agent designed specifically for error resolution in a computational notebook. We have developed an agentic system capable of exploring a notebook environment by interacting with it -- similar to how a user would -- and integrated the system into the JetBrains service for collaborative data science called Datalore. We evaluate our approach against the pre-existing single-action solution by comparing costs and conducting a user study. Users rate the error resolution capabilities of the agentic system higher but experience difficulties with UI. We share the results of the study and consider them valuable for further improving user-agent collaboration.
Towards Realistic Evaluation of Commit Message Generation by Matching Online and Offline Settings
Oct 15, 2024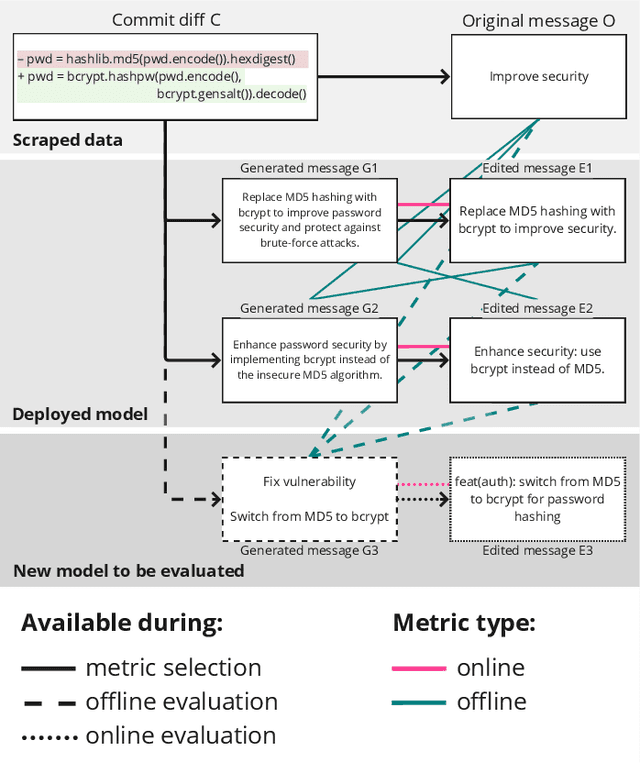
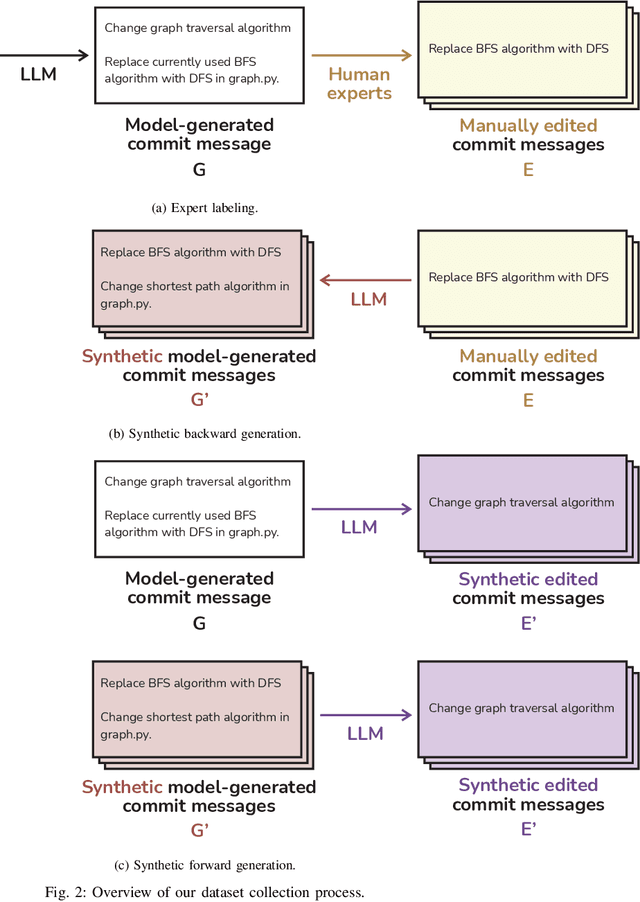
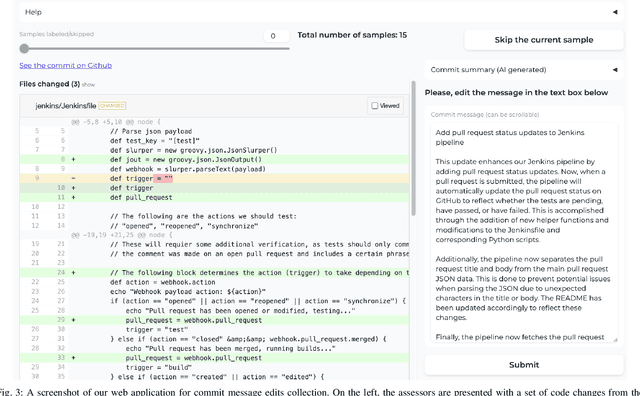
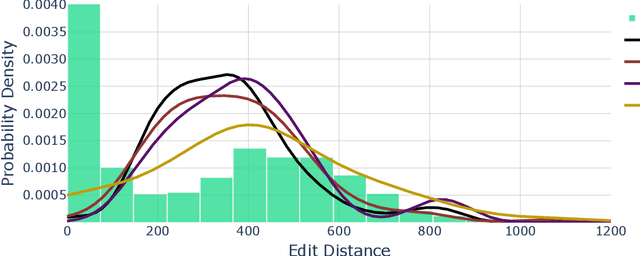
Commit message generation (CMG) is a crucial task in software engineering that is challenging to evaluate correctly. When a CMG system is integrated into the IDEs and other products at JetBrains, we perform online evaluation based on user acceptance of the generated messages. However, performing online experiments with every change to a CMG system is troublesome, as each iteration affects users and requires time to collect enough statistics. On the other hand, offline evaluation, a prevalent approach in the research literature, facilitates fast experiments but employs automatic metrics that are not guaranteed to represent the preferences of real users. In this work, we describe a novel way we employed to deal with this problem at JetBrains, by leveraging an online metric - the number of edits users introduce before committing the generated messages to the VCS - to select metrics for offline experiments. To support this new type of evaluation, we develop a novel markup collection tool mimicking the real workflow with a CMG system, collect a dataset with 57 pairs consisting of commit messages generated by GPT-4 and their counterparts edited by human experts, and design and verify a way to synthetically extend such a dataset. Then, we use the final dataset of 656 pairs to study how the widely used similarity metrics correlate with the online metric reflecting the real users' experience. Our results indicate that edit distance exhibits the highest correlation, whereas commonly used similarity metrics such as BLEU and METEOR demonstrate low correlation. This contradicts the previous studies on similarity metrics for CMG, suggesting that user interactions with a CMG system in real-world settings differ significantly from the responses by human labelers operating within controlled research environments. We release all the code and the dataset for researchers: https://jb.gg/cmg-evaluation.
One Step at a Time: Combining LLMs and Static Analysis to Generate Next-Step Hints for Programming Tasks
Oct 11, 2024



Students often struggle with solving programming problems when learning to code, especially when they have to do it online, with one of the most common disadvantages of working online being the lack of personalized help. This help can be provided as next-step hint generation, i.e., showing a student what specific small step they need to do next to get to the correct solution. There are many ways to generate such hints, with large language models (LLMs) being among the most actively studied right now. While LLMs constitute a promising technology for providing personalized help, combining them with other techniques, such as static analysis, can significantly improve the output quality. In this work, we utilize this idea and propose a novel system to provide both textual and code hints for programming tasks. The pipeline of the proposed approach uses a chain-of-thought prompting technique and consists of three distinct steps: (1) generating subgoals - a list of actions to proceed with the task from the current student's solution, (2) generating the code to achieve the next subgoal, and (3) generating the text to describe this needed action. During the second step, we apply static analysis to the generated code to control its size and quality. The tool is implemented as a modification to the open-source JetBrains Academy plugin, supporting students in their in-IDE courses. To evaluate our approach, we propose a list of criteria for all steps in our pipeline and conduct two rounds of expert validation. Finally, we evaluate the next-step hints in a classroom with 14 students from two universities. Our results show that both forms of the hints - textual and code - were helpful for the students, and the proposed system helped them to proceed with the coding tasks.
Long Code Arena: a Set of Benchmarks for Long-Context Code Models
Jun 17, 2024



Nowadays, the fields of code and natural language processing are evolving rapidly. In particular, models become better at processing long context windows - supported context sizes have increased by orders of magnitude over the last few years. However, there is a shortage of benchmarks for code processing that go beyond a single file of context, while the most popular ones are limited to a single method. With this work, we aim to close this gap by introducing Long Code Arena, a suite of six benchmarks for code processing tasks that require project-wide context. These tasks cover different aspects of code processing: library-based code generation, CI builds repair, project-level code completion, commit message generation, bug localization, and module summarization. For each task, we provide a manually verified dataset for testing, an evaluation suite, and open-source baseline solutions based on popular LLMs to showcase the usage of the dataset and to simplify adoption by other researchers. We publish the benchmark page on HuggingFace Spaces with the leaderboard, links to HuggingFace Hub for all the datasets, and link to the GitHub repository with baselines: https://huggingface.co/spaces/JetBrains-Research/long-code-arena.
Using AI-Based Coding Assistants in Practice: State of Affairs, Perceptions, and Ways Forward
Jun 11, 2024The last several years saw the emergence of AI assistants for code -- multi-purpose AI-based helpers in software engineering. Their quick development makes it necessary to better understand how specifically developers are using them, why they are not using them in certain parts of their development workflow, and what needs to be improved. In this work, we carried out a large-scale survey aimed at how AI assistants are used, focusing on specific software development activities and stages. We collected opinions of 481 programmers on five broad activities: (a) implementing new features, (b) writing tests, (c) bug triaging, (d) refactoring, and (e) writing natural-language artifacts, as well as their individual stages. Our results show that usage of AI assistants varies depending on activity and stage. For instance, developers find writing tests and natural-language artifacts to be the least enjoyable activities and want to delegate them the most, currently using AI assistants to generate tests and test data, as well as generating comments and docstrings most of all. This can be a good focus for features aimed to help developers right now. As for why developers do not use assistants, in addition to general things like trust and company policies, there are fixable issues that can serve as a guide for further research, e.g., the lack of project-size context, and lack of awareness about assistants. We believe that our comprehensive and specific results are especially needed now to steer active research toward where users actually need AI assistants.
On The Importance of Reasoning for Context Retrieval in Repository-Level Code Editing
Jun 06, 2024
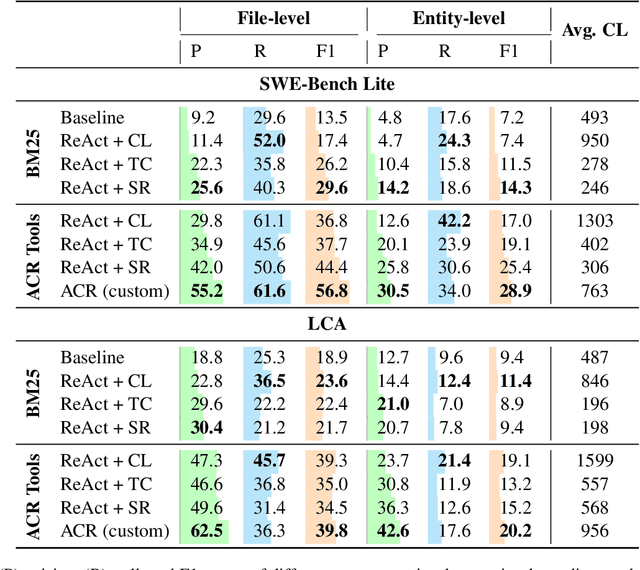
Recent advancements in code-fluent Large Language Models (LLMs) enabled the research on repository-level code editing. In such tasks, the model navigates and modifies the entire codebase of a project according to request. Hence, such tasks require efficient context retrieval, i.e., navigating vast codebases to gather relevant context. Despite the recognized importance of context retrieval, existing studies tend to approach repository-level coding tasks in an end-to-end manner, rendering the impact of individual components within these complicated systems unclear. In this work, we decouple the task of context retrieval from the other components of the repository-level code editing pipelines. We lay the groundwork to define the strengths and weaknesses of this component and the role that reasoning plays in it by conducting experiments that focus solely on context retrieval. We conclude that while the reasoning helps to improve the precision of the gathered context, it still lacks the ability to identify its sufficiency. We also outline the ultimate role of the specialized tools in the process of context gathering. The code supplementing this paper is available at https://github.com/JetBrains-Research/ai-agents-code-editing.
EM-Assist: Safe Automated ExtractMethod Refactoring with LLMs
May 31, 2024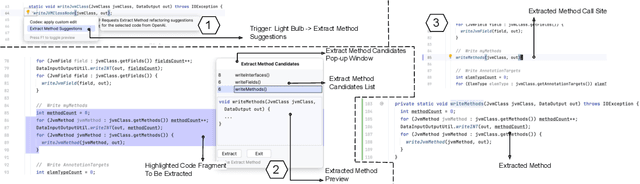
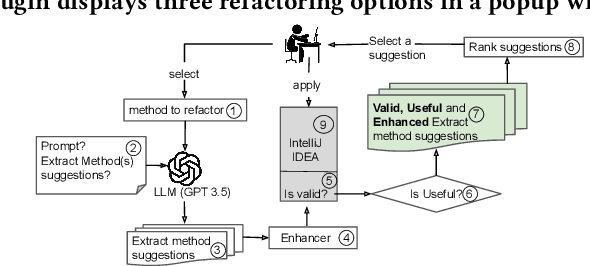

Excessively long methods, loaded with multiple responsibilities, are challenging to understand, debug, reuse, and maintain. The solution lies in the widely recognized Extract Method refactoring. While the application of this refactoring is supported in modern IDEs, recommending which code fragments to extract has been the topic of many research tools. However, they often struggle to replicate real-world developer practices, resulting in recommendations that do not align with what a human developer would do in real life. To address this issue, we introduce EM-Assist, an IntelliJ IDEA plugin that uses LLMs to generate refactoring suggestions and subsequently validates, enhances, and ranks them. Finally, EM-Assist uses the IntelliJ IDE to apply the user-selected recommendation. In our extensive evaluation of 1,752 real-world refactorings that actually took place in open-source projects, EM-Assist's recall rate was 53.4% among its top-5 recommendations, compared to 39.4% for the previous best-in-class tool that relies solely on static analysis. Moreover, we conducted a usability survey with 18 industrial developers and 94.4% gave a positive rating.
Kotlin ML Pack: Technical Report
May 29, 2024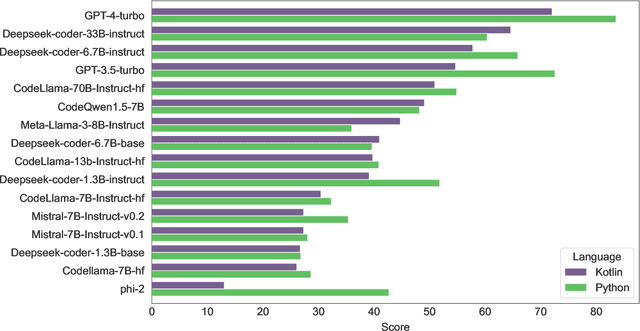
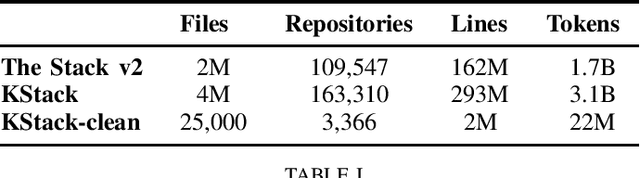
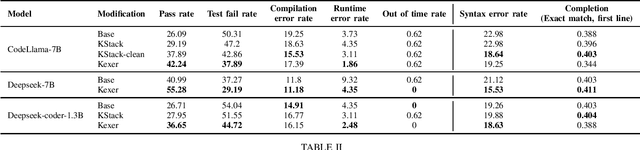
In this technical report, we present three novel datasets of Kotlin code: KStack, KStack-clean, and KExercises. We also describe the results of fine-tuning CodeLlama and DeepSeek models on this data. Additionally, we present a version of the HumanEval benchmark rewritten by human experts into Kotlin - both the solutions and the tests. Our results demonstrate that small, high-quality datasets (KStack-clean and KExercises) can significantly improve model performance on code generation tasks, achieving up to a 16-point increase in pass rate on the HumanEval benchmark. Lastly, we discuss potential future work in the field of improving language modeling for Kotlin, including the use of static analysis tools in the learning process and the introduction of more intricate and realistic benchmarks.
Full Line Code Completion: Bringing AI to Desktop
May 14, 2024



In recent years, several industrial solutions for the problem of multi-token code completion have appeared, each making a great advance in the area but mostly focusing on cloud-based runtime and avoiding working on the end user's device. In this work, we describe our approach for building a multi-token code completion feature for the JetBrains' IntelliJ Platform, which we call Full Line Code Completion. The feature suggests only syntactically correct code and works fully locally, i.e., data querying and the generation of suggestions happens on the end user's machine. We share important time and memory-consumption restrictions, as well as design principles that a code completion engine should satisfy. Working entirely on the end user's device, our code completion engine enriches user experience while being not only fast and compact but also secure. We share a number of useful techniques to meet the stated development constraints and also describe offline and online evaluation pipelines that allowed us to make better decisions. Our online evaluation shows that the usage of the tool leads to 1.5 times more code in the IDE being produced by code completion. The described solution was initially started with the help of researchers and was bundled into two JetBrains' IDEs - PyCharm Pro and DataSpell - at the end of 2023, so we believe that this work is useful for bridging academia and industry, providing researchers with the knowledge of what happens when complex research-based solutions are integrated into real products.