 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiffusion-Based Electromagnetic Inverse Design of Scattering Structured Media
Nov 07, 2025We present a conditional diffusion model for electromagnetic inverse design that generates structured media geometries directly from target differential scattering cross-section profiles, bypassing expensive iterative optimization. Our 1D U-Net architecture with Feature-wise Linear Modulation learns to map desired angular scattering patterns to 2x2 dielectric sphere structure, naturally handling the non-uniqueness of inverse problems by sampling diverse valid designs. Trained on 11,000 simulated metasurfaces, the model achieves median MPE below 19% on unseen targets (best: 1.39%), outperforming CMA-ES evolutionary optimization while reducing design time from hours to seconds. These results demonstrate that employing diffusion models is promising for advancing electromagnetic inverse design research, potentially enabling rapid exploration of complex metasurface architectures and accelerating the development of next-generation photonic and wireless communication systems. The code is publicly available at https://github.com/mikzuker/inverse_design_metasurface_generation.
Themisto: Jupyter-Based Runtime Benchmark
Apr 16, 2025In this work, we present a benchmark that consists of Jupyter notebooks development trajectories and allows measuring how large language models (LLMs) can leverage runtime information for predicting code output and code generation. We demonstrate that the current generation of LLMs performs poorly on these tasks and argue that there exists a significantly understudied domain in the development of code-based models, which involves incorporating the runtime context.
Debug Smarter, Not Harder: AI Agents for Error Resolution in Computational Notebooks
Oct 18, 2024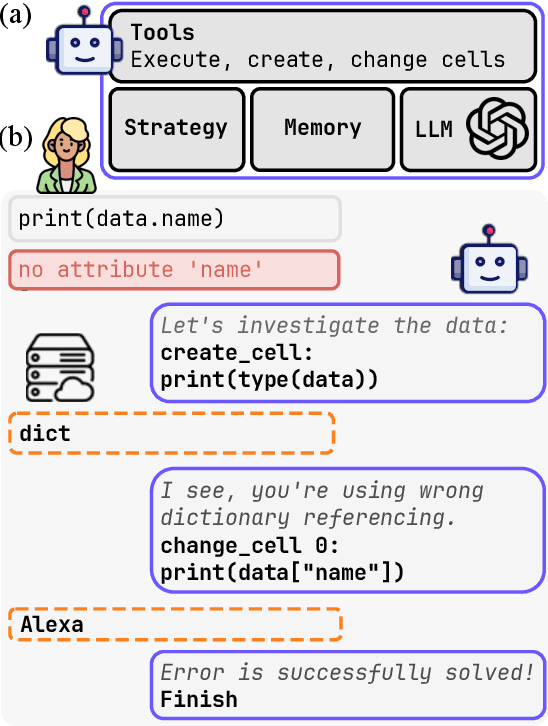
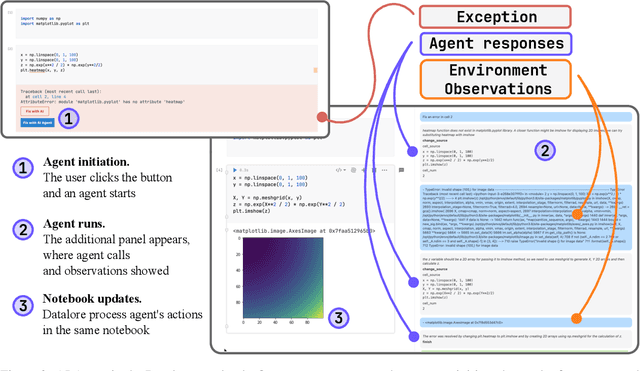
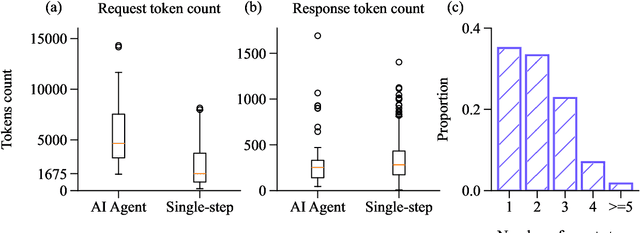
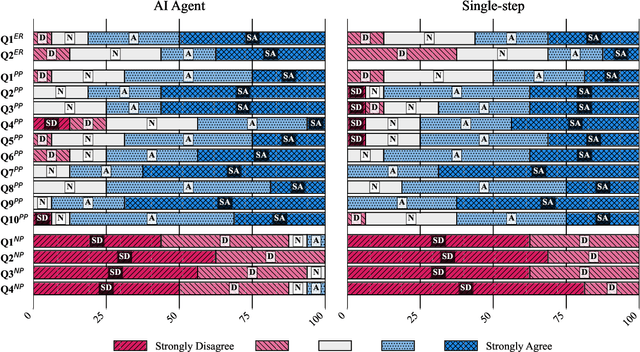
Computational notebooks became indispensable tools for research-related development, offering unprecedented interactivity and flexibility in the development process. However, these benefits come at the cost of reproducibility and an increased potential for bugs. With the rise of code-fluent Large Language Models empowered with agentic techniques, smart bug-fixing tools with a high level of autonomy have emerged. However, those tools are tuned for classical script programming and still struggle with non-linear computational notebooks. In this paper, we present an AI agent designed specifically for error resolution in a computational notebook. We have developed an agentic system capable of exploring a notebook environment by interacting with it -- similar to how a user would -- and integrated the system into the JetBrains service for collaborative data science called Datalore. We evaluate our approach against the pre-existing single-action solution by comparing costs and conducting a user study. Users rate the error resolution capabilities of the agentic system higher but experience difficulties with UI. We share the results of the study and consider them valuable for further improving user-agent collaboration.