 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Agent Coordinated Rename Refactoring
Jan 01, 2026The primary value of AI agents in software development lies in their ability to extend the developer's capacity for reasoning and action, not to supplant human involvement. To showcase how to use agents working in tandem with developers, we designed a novel approach for carrying out coordinated renaming. Coordinated renaming, where a single rename refactoring triggers refactorings in multiple, related identifiers, is a frequent yet challenging task. Developers must manually propagate these rename refactorings across numerous files and contexts, a process that is both tedious and highly error-prone. State-of-the-art heuristic-based approaches produce an overwhelming number of false positives, while vanilla Large Language Models (LLMs) provide incomplete suggestions due to their limited context and inability to interact with refactoring tools. This leaves developers with incomplete refactorings or burdens them with filtering too many false positives. Coordinated renaming is exactly the kind of repetitive task that agents can significantly reduce the developers' burden while keeping them in the driver's seat. We designed, implemented, and evaluated the first multi-agent framework that automates coordinated renaming. It operates on a key insight: a developer's initial refactoring is a clue to infer the scope of related refactorings. Our Scope Inference Agent first transforms this clue into an explicit, natural-language Declared Scope. The Planned Execution Agent then uses this as a strict plan to identify program elements that should undergo refactoring and safely executes the changes by invoking the IDE's own trusted refactoring APIs. Finally, the Replication Agent uses it to guide the project-wide search. We first conducted a formative study on the practice of coordinated renaming in 609K commits in 100 open-source projects and surveyed 205 developers ...
GitGoodBench: A Novel Benchmark For Evaluating Agentic Performance On Git
May 28, 2025Benchmarks for Software Engineering (SE) AI agents, most notably SWE-bench, have catalyzed progress in programming capabilities of AI agents. However, they overlook critical developer workflows such as Version Control System (VCS) operations. To address this issue, we present GitGoodBench, a novel benchmark for evaluating AI agent performance on VCS tasks. GitGoodBench covers three core Git scenarios extracted from permissive open-source Python, Java, and Kotlin repositories. Our benchmark provides three datasets: a comprehensive evaluation suite (900 samples), a rapid prototyping version (120 samples), and a training corpus (17,469 samples). We establish baseline performance on the prototyping version of our benchmark using GPT-4o equipped with custom tools, achieving a 21.11% solve rate overall. We expect GitGoodBench to serve as a crucial stepping stone toward truly comprehensive SE agents that go beyond mere programming.
EnvBench: A Benchmark for Automated Environment Setup
Mar 18, 2025Recent advances in Large Language Models (LLMs) have enabled researchers to focus on practical repository-level tasks in software engineering domain. In this work, we consider a cornerstone task for automating work with software repositories-environment setup, i.e., a task of configuring a repository-specific development environment on a system. Existing studies on environment setup introduce innovative agentic strategies, but their evaluation is often based on small datasets that may not capture the full range of configuration challenges encountered in practice. To address this gap, we introduce a comprehensive environment setup benchmark EnvBench. It encompasses 329 Python and 665 JVM-based (Java, Kotlin) repositories, with a focus on repositories that present genuine configuration challenges, excluding projects that can be fully configured by simple deterministic scripts. To enable further benchmark extension and usage for model tuning, we implement two automatic metrics: a static analysis check for missing imports in Python and a compilation check for JVM languages. We demonstrate the applicability of our benchmark by evaluating three environment setup approaches, including a simple zero-shot baseline and two agentic workflows, that we test with two powerful LLM backbones, GPT-4o and GPT-4o-mini. The best approach manages to successfully configure 6.69% repositories for Python and 29.47% repositories for JVM, suggesting that EnvBench remains challenging for current approaches. Our benchmark suite is publicly available at https://github.com/JetBrains-Research/EnvBench. The dataset and experiment trajectories are available at https://jb.gg/envbench.
Debug Smarter, Not Harder: AI Agents for Error Resolution in Computational Notebooks
Oct 18, 2024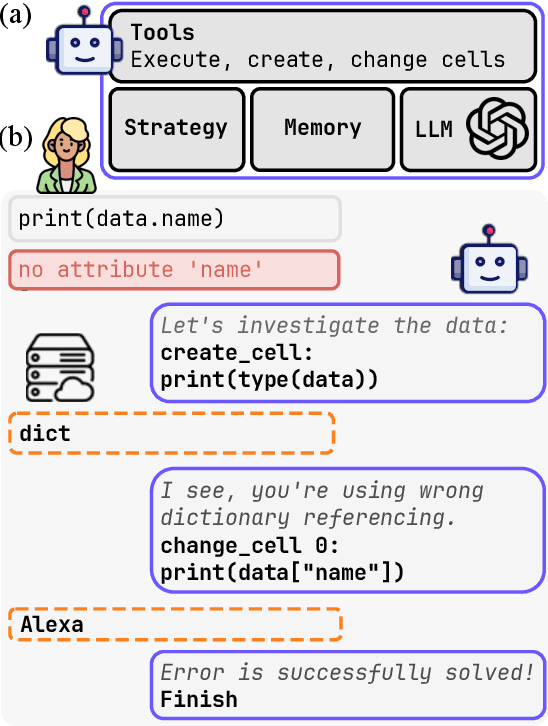
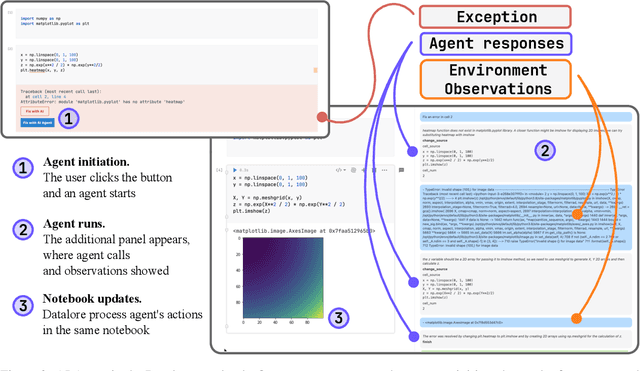
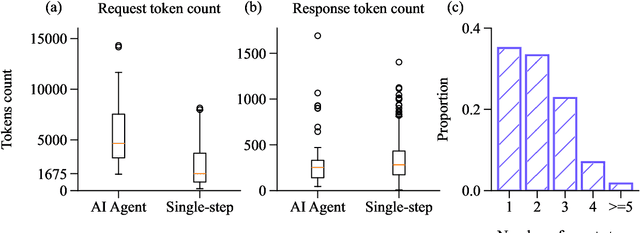
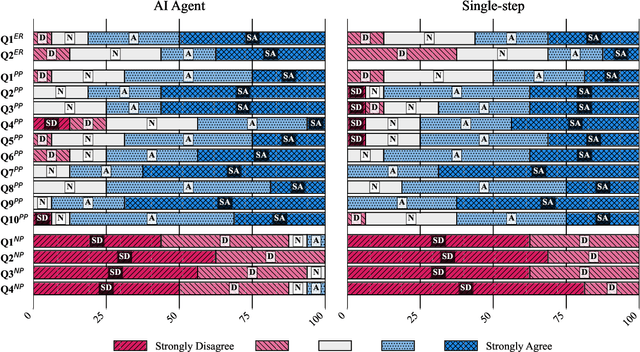
Computational notebooks became indispensable tools for research-related development, offering unprecedented interactivity and flexibility in the development process. However, these benefits come at the cost of reproducibility and an increased potential for bugs. With the rise of code-fluent Large Language Models empowered with agentic techniques, smart bug-fixing tools with a high level of autonomy have emerged. However, those tools are tuned for classical script programming and still struggle with non-linear computational notebooks. In this paper, we present an AI agent designed specifically for error resolution in a computational notebook. We have developed an agentic system capable of exploring a notebook environment by interacting with it -- similar to how a user would -- and integrated the system into the JetBrains service for collaborative data science called Datalore. We evaluate our approach against the pre-existing single-action solution by comparing costs and conducting a user study. Users rate the error resolution capabilities of the agentic system higher but experience difficulties with UI. We share the results of the study and consider them valuable for further improving user-agent collaboration.
Towards Realistic Evaluation of Commit Message Generation by Matching Online and Offline Settings
Oct 15, 2024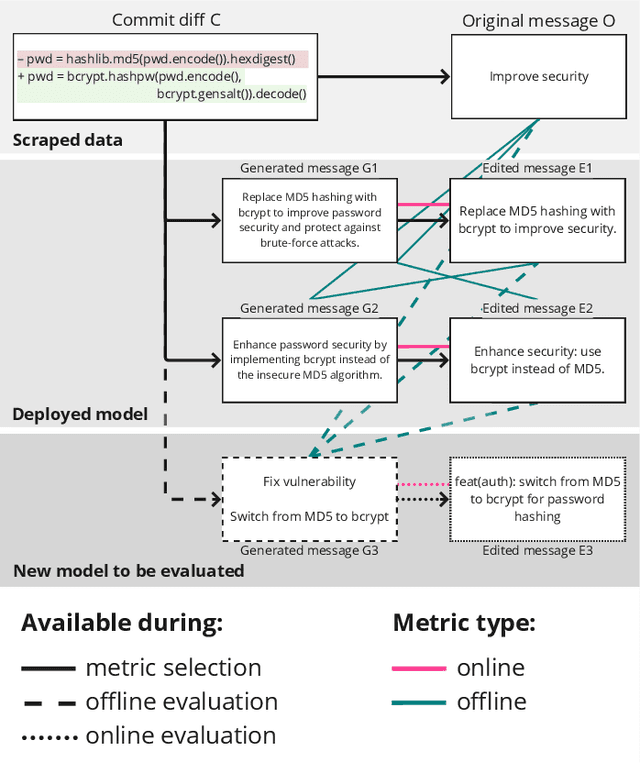
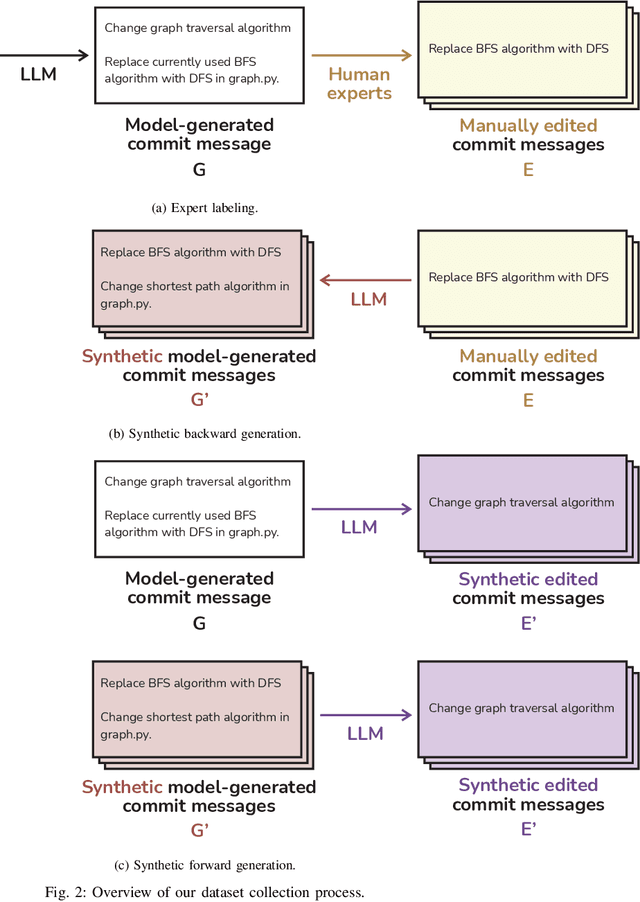
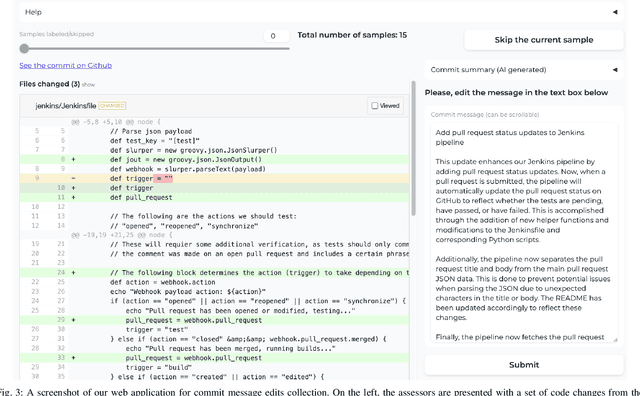
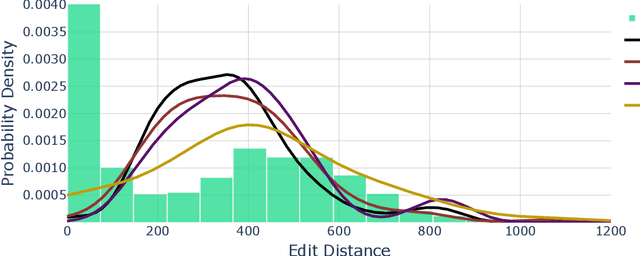
Commit message generation (CMG) is a crucial task in software engineering that is challenging to evaluate correctly. When a CMG system is integrated into the IDEs and other products at JetBrains, we perform online evaluation based on user acceptance of the generated messages. However, performing online experiments with every change to a CMG system is troublesome, as each iteration affects users and requires time to collect enough statistics. On the other hand, offline evaluation, a prevalent approach in the research literature, facilitates fast experiments but employs automatic metrics that are not guaranteed to represent the preferences of real users. In this work, we describe a novel way we employed to deal with this problem at JetBrains, by leveraging an online metric - the number of edits users introduce before committing the generated messages to the VCS - to select metrics for offline experiments. To support this new type of evaluation, we develop a novel markup collection tool mimicking the real workflow with a CMG system, collect a dataset with 57 pairs consisting of commit messages generated by GPT-4 and their counterparts edited by human experts, and design and verify a way to synthetically extend such a dataset. Then, we use the final dataset of 656 pairs to study how the widely used similarity metrics correlate with the online metric reflecting the real users' experience. Our results indicate that edit distance exhibits the highest correlation, whereas commonly used similarity metrics such as BLEU and METEOR demonstrate low correlation. This contradicts the previous studies on similarity metrics for CMG, suggesting that user interactions with a CMG system in real-world settings differ significantly from the responses by human labelers operating within controlled research environments. We release all the code and the dataset for researchers: https://jb.gg/cmg-evaluation.
On The Importance of Reasoning for Context Retrieval in Repository-Level Code Editing
Jun 06, 2024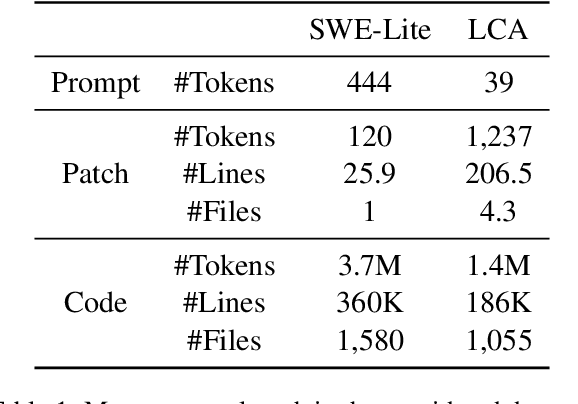
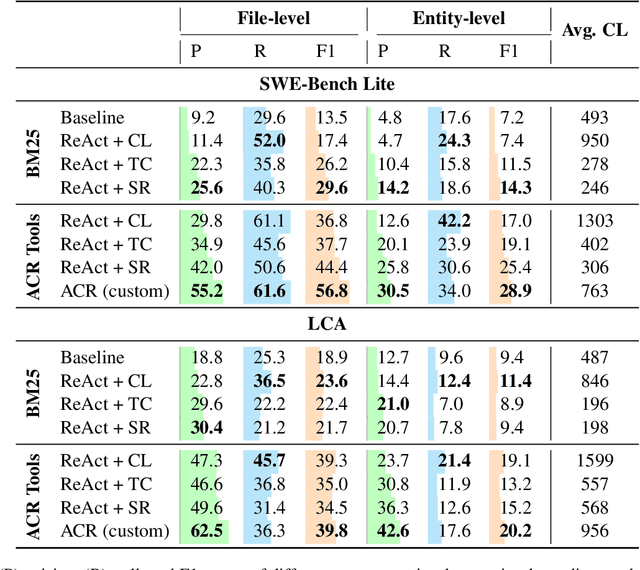
Recent advancements in code-fluent Large Language Models (LLMs) enabled the research on repository-level code editing. In such tasks, the model navigates and modifies the entire codebase of a project according to request. Hence, such tasks require efficient context retrieval, i.e., navigating vast codebases to gather relevant context. Despite the recognized importance of context retrieval, existing studies tend to approach repository-level coding tasks in an end-to-end manner, rendering the impact of individual components within these complicated systems unclear. In this work, we decouple the task of context retrieval from the other components of the repository-level code editing pipelines. We lay the groundwork to define the strengths and weaknesses of this component and the role that reasoning plays in it by conducting experiments that focus solely on context retrieval. We conclude that while the reasoning helps to improve the precision of the gathered context, it still lacks the ability to identify its sufficiency. We also outline the ultimate role of the specialized tools in the process of context gathering. The code supplementing this paper is available at https://github.com/JetBrains-Research/ai-agents-code-editing.
Shot Noise Reduction in Radiographic and Tomographic Multi-Channel Imaging with Self-Supervised Deep Learning
Mar 25, 2023Noise is an important issue for radiographic and tomographic imaging techniques. It becomes particularly critical in applications where additional constraints force a strong reduction of the Signal-to-Noise Ratio (SNR) per image. These constraints may result from limitations on the maximum available flux or permissible dose and the associated restriction on exposure time. Often, a high SNR per image is traded for the ability to distribute a given total exposure capacity per pixel over multiple channels, thus obtaining additional information about the object by the same total exposure time. These can be energy channels in the case of spectroscopic imaging or time channels in the case of time-resolved imaging. In this paper, we report on a method for improving the quality of noisy multi-channel (time or energy-resolved) imaging datasets. The method relies on the recent Noise2Noise (N2N) self-supervised denoising approach that learns to predict a noise-free signal without access to noise-free data. N2N in turn requires drawing pairs of samples from a data distribution sharing identical signals while being exposed to different samples of random noise. The method is applicable if adjacent channels share enough information to provide images with similar enough information but independent noise. We demonstrate several representative case studies, namely spectroscopic (k-edge) X-ray tomography, in vivo X-ray cine-radiography, and energy-dispersive (Bragg edge) neutron tomography. In all cases, the N2N method shows dramatic improvement and outperforms conventional denoising methods. For such imaging techniques, the method can therefore significantly improve image quality, or maintain image quality with further reduced exposure time per image.
Optimizing the Procedure of CT Segmentation Labeling
Mar 24, 2023In Computed Tomography, machine learning is often used for automated data processing. However, increasing model complexity is accompanied by increasingly large volume datasets, which in turn increases the cost of model training. Unlike most work that mitigates this by advancing model architectures and training algorithms, we consider the annotation procedure and its effect on the model performance. We assume three main virtues of a good dataset collected for a model training to be label quality, diversity, and completeness. We compare the effects of those virtues on the model performance using open medical CT datasets and conclude, that quality is more important than diversity early during labeling; the diversity, in turn, is more important than completeness. Based on this conclusion and additional experiments, we propose a labeling procedure for the segmentation of tomographic images to minimize efforts spent on labeling while maximizing the model performance.
A Knowledge Distillation framework for Multi-Organ Segmentation of Medaka Fish in Tomographic Image
Feb 24, 2023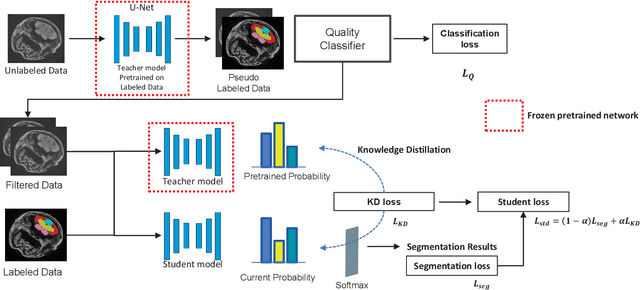



Morphological atlases are an important tool in organismal studies, and modern high-throughput Computed Tomography (CT) facilities can produce hundreds of full-body high-resolution volumetric images of organisms. However, creating an atlas from these volumes requires accurate organ segmentation. In the last decade, machine learning approaches have achieved incredible results in image segmentation tasks, but they require large amounts of annotated data for training. In this paper, we propose a self-training framework for multi-organ segmentation in tomographic images of Medaka fish. We utilize the pseudo-labeled data from a pretrained Teacher model and adopt a Quality Classifier to refine the pseudo-labeled data. Then, we introduce a pixel-wise knowledge distillation method to prevent overfitting to the pseudo-labeled data and improve the segmentation performance. The experimental results demonstrate that our method improves mean Intersection over Union (IoU) by 5.9% on the full dataset and enables keeping the quality while using three times less markup.
Using the Order of Tomographic Slices as a Prior for Neural Networks Pre-Training
Mar 17, 2022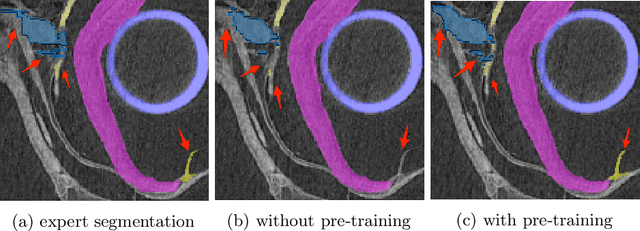
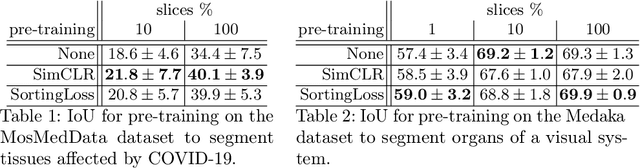


The technical advances in Computed Tomography (CT) allow to obtain immense amounts of 3D data. For such datasets it is very costly and time-consuming to obtain the accurate 3D segmentation markup to train neural networks. The annotation is typically done for a limited number of 2D slices, followed by an interpolation. In this work, we propose a pre-training method SortingLoss. It performs pre-training on slices instead of volumes, so that a model could be fine-tuned on a sparse set of slices, without the interpolation step. Unlike general methods (e.g. SimCLR or Barlow Twins), the task specific methods (e.g. Transferable Visual Words) trade broad applicability for quality benefits by imposing stronger assumptions on the input data. We propose a relatively mild assumption -- if we take several slices along some axis of a volume, structure of the sample presented on those slices, should give a strong clue to reconstruct the correct order of those slices along the axis. Many biomedical datasets fulfill this requirement due to the specific anatomy of a sample and pre-defined alignment of the imaging setup. We examine the proposed method on two datasets: medical CT of lungs affected by COVID-19 disease, and high-resolution synchrotron-based full-body CT of model organisms (Medaka fish). We show that the proposed method performs on par with SimCLR, while working 2x faster and requiring 1.5x less memory. In addition, we present the benefits in terms of practical scenarios, especially the applicability to the pre-training of large models and the ability to localize samples within volumes in an unsupervised setup.