 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Knowledge Distillation framework for Multi-Organ Segmentation of Medaka Fish in Tomographic Image
Feb 24, 2023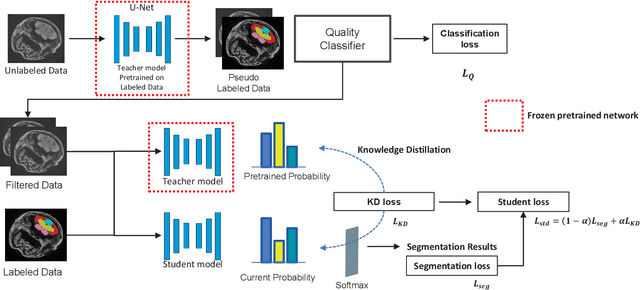



Morphological atlases are an important tool in organismal studies, and modern high-throughput Computed Tomography (CT) facilities can produce hundreds of full-body high-resolution volumetric images of organisms. However, creating an atlas from these volumes requires accurate organ segmentation. In the last decade, machine learning approaches have achieved incredible results in image segmentation tasks, but they require large amounts of annotated data for training. In this paper, we propose a self-training framework for multi-organ segmentation in tomographic images of Medaka fish. We utilize the pseudo-labeled data from a pretrained Teacher model and adopt a Quality Classifier to refine the pseudo-labeled data. Then, we introduce a pixel-wise knowledge distillation method to prevent overfitting to the pseudo-labeled data and improve the segmentation performance. The experimental results demonstrate that our method improves mean Intersection over Union (IoU) by 5.9% on the full dataset and enables keeping the quality while using three times less markup.
Time to Focus: A Comprehensive Benchmark Using Time Series Attribution Methods
Feb 08, 2022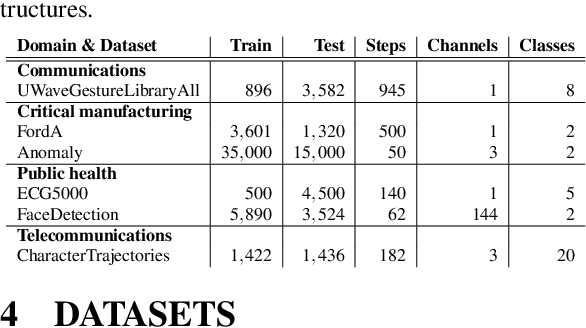

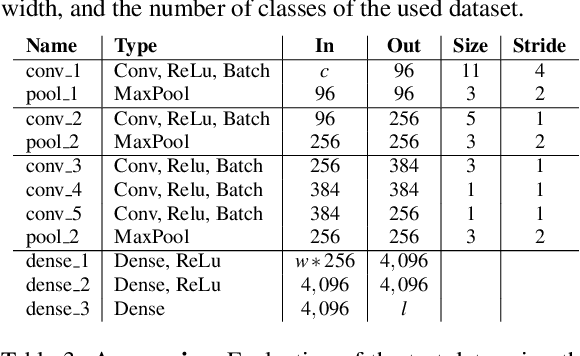
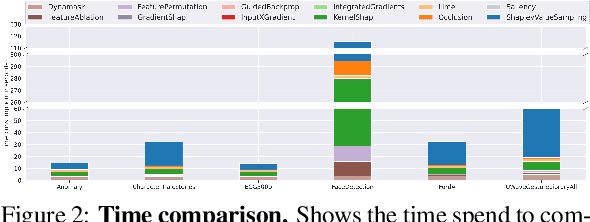
In the last decade neural network have made huge impact both in industry and research due to their ability to extract meaningful features from imprecise or complex data, and by achieving super human performance in several domains. However, due to the lack of transparency the use of these networks is hampered in the areas with safety critical areas. In safety-critical areas, this is necessary by law. Recently several methods have been proposed to uncover this black box by providing interpreation of predictions made by these models. The paper focuses on time series analysis and benchmark several state-of-the-art attribution methods which compute explanations for convolutional classifiers. The presented experiments involve gradient-based and perturbation-based attribution methods. A detailed analysis shows that perturbation-based approaches are superior concerning the Sensitivity and occlusion game. These methods tend to produce explanations with higher continuity. Contrarily, the gradient-based techniques are superb in runtime and Infidelity. In addition, a validation the dependence of the methods on the trained model, feasible application domains, and individual characteristics is attached. The findings accentuate that choosing the best-suited attribution method is strongly correlated with the desired use case. Neither category of attribution methods nor a single approach has shown outstanding performance across all aspects.