 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Knowledge Distillation framework for Multi-Organ Segmentation of Medaka Fish in Tomographic Image
Paper and Code
Feb 24, 2023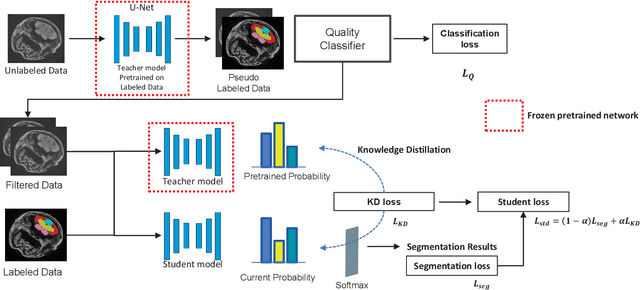



Morphological atlases are an important tool in organismal studies, and modern high-throughput Computed Tomography (CT) facilities can produce hundreds of full-body high-resolution volumetric images of organisms. However, creating an atlas from these volumes requires accurate organ segmentation. In the last decade, machine learning approaches have achieved incredible results in image segmentation tasks, but they require large amounts of annotated data for training. In this paper, we propose a self-training framework for multi-organ segmentation in tomographic images of Medaka fish. We utilize the pseudo-labeled data from a pretrained Teacher model and adopt a Quality Classifier to refine the pseudo-labeled data. Then, we introduce a pixel-wise knowledge distillation method to prevent overfitting to the pseudo-labeled data and improve the segmentation performance. The experimental results demonstrate that our method improves mean Intersection over Union (IoU) by 5.9% on the full dataset and enables keeping the quality while using three times less markup.