 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeShot Noise Reduction in Radiographic and Tomographic Multi-Channel Imaging with Self-Supervised Deep Learning
Mar 25, 2023Noise is an important issue for radiographic and tomographic imaging techniques. It becomes particularly critical in applications where additional constraints force a strong reduction of the Signal-to-Noise Ratio (SNR) per image. These constraints may result from limitations on the maximum available flux or permissible dose and the associated restriction on exposure time. Often, a high SNR per image is traded for the ability to distribute a given total exposure capacity per pixel over multiple channels, thus obtaining additional information about the object by the same total exposure time. These can be energy channels in the case of spectroscopic imaging or time channels in the case of time-resolved imaging. In this paper, we report on a method for improving the quality of noisy multi-channel (time or energy-resolved) imaging datasets. The method relies on the recent Noise2Noise (N2N) self-supervised denoising approach that learns to predict a noise-free signal without access to noise-free data. N2N in turn requires drawing pairs of samples from a data distribution sharing identical signals while being exposed to different samples of random noise. The method is applicable if adjacent channels share enough information to provide images with similar enough information but independent noise. We demonstrate several representative case studies, namely spectroscopic (k-edge) X-ray tomography, in vivo X-ray cine-radiography, and energy-dispersive (Bragg edge) neutron tomography. In all cases, the N2N method shows dramatic improvement and outperforms conventional denoising methods. For such imaging techniques, the method can therefore significantly improve image quality, or maintain image quality with further reduced exposure time per image.
Optimizing the Procedure of CT Segmentation Labeling
Mar 24, 2023In Computed Tomography, machine learning is often used for automated data processing. However, increasing model complexity is accompanied by increasingly large volume datasets, which in turn increases the cost of model training. Unlike most work that mitigates this by advancing model architectures and training algorithms, we consider the annotation procedure and its effect on the model performance. We assume three main virtues of a good dataset collected for a model training to be label quality, diversity, and completeness. We compare the effects of those virtues on the model performance using open medical CT datasets and conclude, that quality is more important than diversity early during labeling; the diversity, in turn, is more important than completeness. Based on this conclusion and additional experiments, we propose a labeling procedure for the segmentation of tomographic images to minimize efforts spent on labeling while maximizing the model performance.
A Knowledge Distillation framework for Multi-Organ Segmentation of Medaka Fish in Tomographic Image
Feb 24, 2023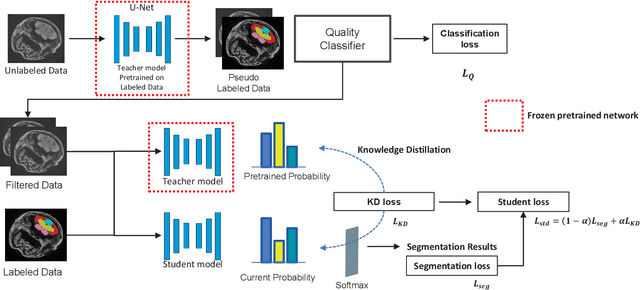



Morphological atlases are an important tool in organismal studies, and modern high-throughput Computed Tomography (CT) facilities can produce hundreds of full-body high-resolution volumetric images of organisms. However, creating an atlas from these volumes requires accurate organ segmentation. In the last decade, machine learning approaches have achieved incredible results in image segmentation tasks, but they require large amounts of annotated data for training. In this paper, we propose a self-training framework for multi-organ segmentation in tomographic images of Medaka fish. We utilize the pseudo-labeled data from a pretrained Teacher model and adopt a Quality Classifier to refine the pseudo-labeled data. Then, we introduce a pixel-wise knowledge distillation method to prevent overfitting to the pseudo-labeled data and improve the segmentation performance. The experimental results demonstrate that our method improves mean Intersection over Union (IoU) by 5.9% on the full dataset and enables keeping the quality while using three times less markup.
Using the Order of Tomographic Slices as a Prior for Neural Networks Pre-Training
Mar 17, 2022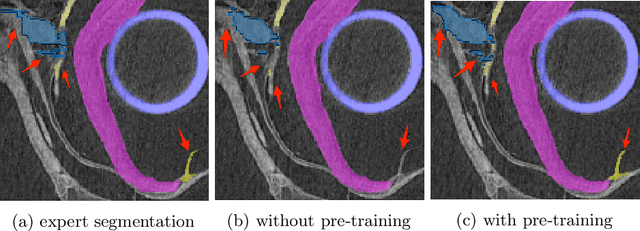
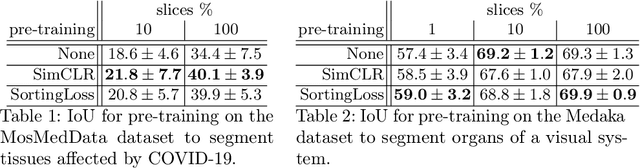


The technical advances in Computed Tomography (CT) allow to obtain immense amounts of 3D data. For such datasets it is very costly and time-consuming to obtain the accurate 3D segmentation markup to train neural networks. The annotation is typically done for a limited number of 2D slices, followed by an interpolation. In this work, we propose a pre-training method SortingLoss. It performs pre-training on slices instead of volumes, so that a model could be fine-tuned on a sparse set of slices, without the interpolation step. Unlike general methods (e.g. SimCLR or Barlow Twins), the task specific methods (e.g. Transferable Visual Words) trade broad applicability for quality benefits by imposing stronger assumptions on the input data. We propose a relatively mild assumption -- if we take several slices along some axis of a volume, structure of the sample presented on those slices, should give a strong clue to reconstruct the correct order of those slices along the axis. Many biomedical datasets fulfill this requirement due to the specific anatomy of a sample and pre-defined alignment of the imaging setup. We examine the proposed method on two datasets: medical CT of lungs affected by COVID-19 disease, and high-resolution synchrotron-based full-body CT of model organisms (Medaka fish). We show that the proposed method performs on par with SimCLR, while working 2x faster and requiring 1.5x less memory. In addition, we present the benefits in terms of practical scenarios, especially the applicability to the pre-training of large models and the ability to localize samples within volumes in an unsupervised setup.
Self Supervised Learning for Object Localisation in 3D Tomographic Images
Nov 06, 2020

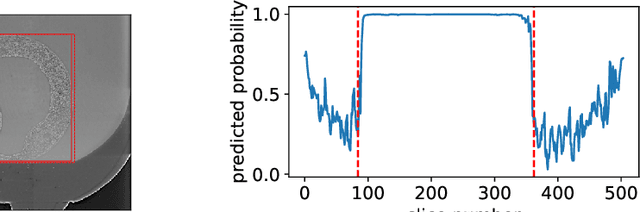
While a lot of work is dedicated to self-supervised learning, most of it is dealing with 2D images of natural scenes and objects. In this paper, we focus on \textit{volumetric} images obtained by means of the X-Ray Computed Tomography (CT). We describe two pretext training tasks which are designed taking into account the specific properties of volumetric data. We propose two ways to transfer a trained network to the downstream task of object localization with a zero amount of manual markup. Despite its simplicity, the proposed method shows its applicability to practical tasks of object localization and data reduction.