 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUsing the Order of Tomographic Slices as a Prior for Neural Networks Pre-Training
Paper and Code
Mar 17, 2022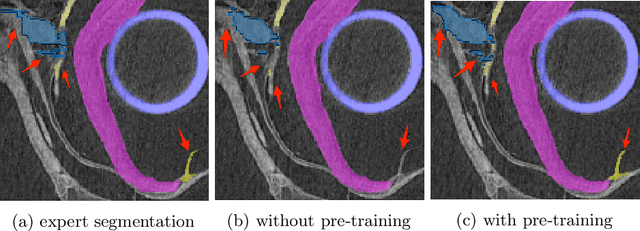
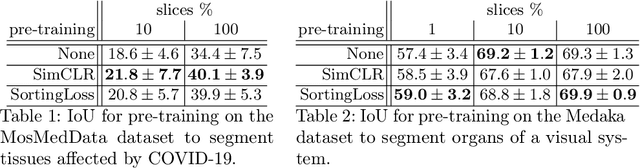


The technical advances in Computed Tomography (CT) allow to obtain immense amounts of 3D data. For such datasets it is very costly and time-consuming to obtain the accurate 3D segmentation markup to train neural networks. The annotation is typically done for a limited number of 2D slices, followed by an interpolation. In this work, we propose a pre-training method SortingLoss. It performs pre-training on slices instead of volumes, so that a model could be fine-tuned on a sparse set of slices, without the interpolation step. Unlike general methods (e.g. SimCLR or Barlow Twins), the task specific methods (e.g. Transferable Visual Words) trade broad applicability for quality benefits by imposing stronger assumptions on the input data. We propose a relatively mild assumption -- if we take several slices along some axis of a volume, structure of the sample presented on those slices, should give a strong clue to reconstruct the correct order of those slices along the axis. Many biomedical datasets fulfill this requirement due to the specific anatomy of a sample and pre-defined alignment of the imaging setup. We examine the proposed method on two datasets: medical CT of lungs affected by COVID-19 disease, and high-resolution synchrotron-based full-body CT of model organisms (Medaka fish). We show that the proposed method performs on par with SimCLR, while working 2x faster and requiring 1.5x less memory. In addition, we present the benefits in terms of practical scenarios, especially the applicability to the pre-training of large models and the ability to localize samples within volumes in an unsupervised setup.