Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf Supervised Learning for Object Localisation in 3D Tomographic Images
Paper and Code
Nov 06, 2020

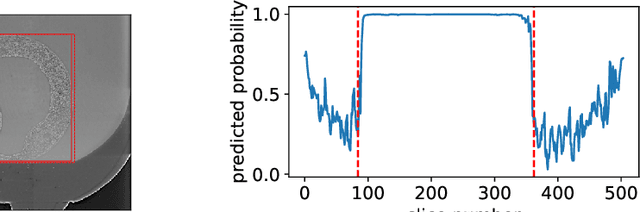
While a lot of work is dedicated to self-supervised learning, most of it is dealing with 2D images of natural scenes and objects. In this paper, we focus on \textit{volumetric} images obtained by means of the X-Ray Computed Tomography (CT). We describe two pretext training tasks which are designed taking into account the specific properties of volumetric data. We propose two ways to transfer a trained network to the downstream task of object localization with a zero amount of manual markup. Despite its simplicity, the proposed method shows its applicability to practical tasks of object localization and data reduction.
View paper on