 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Private to Public: Benchmarking GANs in the Context of Private Time Series Classification
Apr 19, 2023Deep learning has proven to be successful in various domains and for different tasks. However, when it comes to private data several restrictions are making it difficult to use deep learning approaches in these application fields. Recent approaches try to generate data privately instead of applying a privacy-preserving mechanism directly, on top of the classifier. The solution is to create public data from private data in a manner that preserves the privacy of the data. In this work, two very prominent GAN-based architectures were evaluated in the context of private time series classification. In contrast to previous work, mostly limited to the image domain, the scope of this benchmark was the time series domain. The experiments show that especially GSWGAN performs well across a variety of public datasets outperforming the competitor DPWGAN. An analysis of the generated datasets further validates the superiority of GSWGAN in the context of time series generation.
Privacy Meets Explainability: A Comprehensive Impact Benchmark
Nov 08, 2022



Since the mid-10s, the era of Deep Learning (DL) has continued to this day, bringing forth new superlatives and innovations each year. Nevertheless, the speed with which these innovations translate into real applications lags behind this fast pace. Safety-critical applications, in particular, underlie strict regulatory and ethical requirements which need to be taken care of and are still active areas of debate. eXplainable AI (XAI) and privacy-preserving machine learning (PPML) are both crucial research fields, aiming at mitigating some of the drawbacks of prevailing data-hungry black-box models in DL. Despite brisk research activity in the respective fields, no attention has yet been paid to their interaction. This work is the first to investigate the impact of private learning techniques on generated explanations for DL-based models. In an extensive experimental analysis covering various image and time series datasets from multiple domains, as well as varying privacy techniques, XAI methods, and model architectures, the effects of private training on generated explanations are studied. The findings suggest non-negligible changes in explanations through the introduction of privacy. Apart from reporting individual effects of PPML on XAI, the paper gives clear recommendations for the choice of techniques in real applications. By unveiling the interdependencies of these pivotal technologies, this work is a first step towards overcoming the remaining hurdles for practically applicable AI in safety-critical domains.
Utilizing Out-Domain Datasets to Enhance Multi-Task Citation Analysis
Feb 22, 2022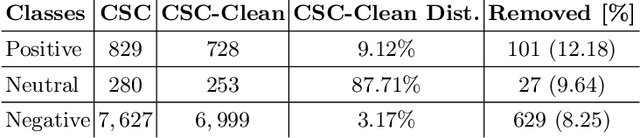

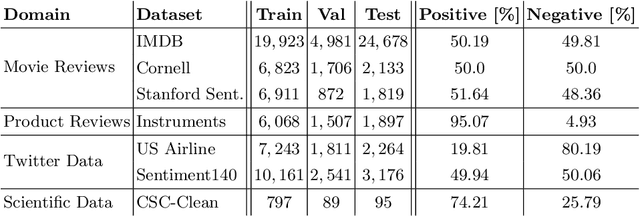
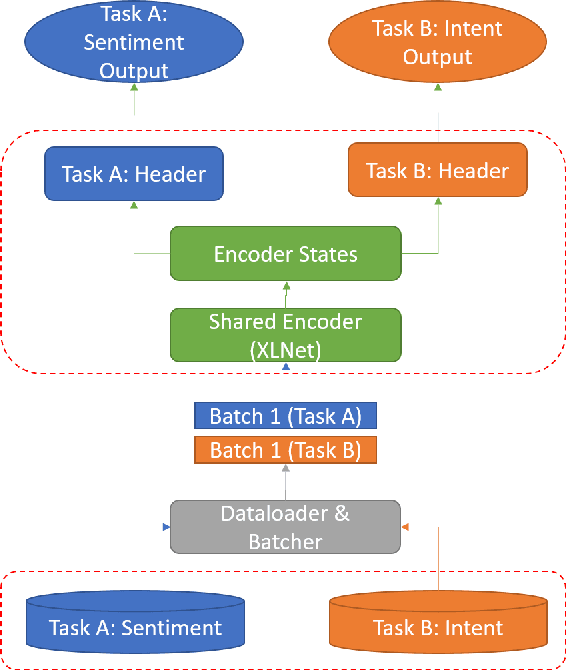
Citations are generally analyzed using only quantitative measures while excluding qualitative aspects such as sentiment and intent. However, qualitative aspects provide deeper insights into the impact of a scientific research artifact and make it possible to focus on relevant literature free from bias associated with quantitative aspects. Therefore, it is possible to rank and categorize papers based on their sentiment and intent. For this purpose, larger citation sentiment datasets are required. However, from a time and cost perspective, curating a large citation sentiment dataset is a challenging task. Particularly, citation sentiment analysis suffers from both data scarcity and tremendous costs for dataset annotation. To overcome the bottleneck of data scarcity in the citation analysis domain we explore the impact of out-domain data during training to enhance the model performance. Our results emphasize the use of different scheduling methods based on the use case. We empirically found that a model trained using sequential data scheduling is more suitable for domain-specific usecases. Conversely, shuffled data feeding achieves better performance on a cross-domain task. Based on our findings, we propose an end-to-end trainable multi-task model that covers the sentiment and intent analysis that utilizes out-domain datasets to overcome the data scarcity.
TimeREISE: Time-series Randomized Evolving Input Sample Explanation
Feb 16, 2022

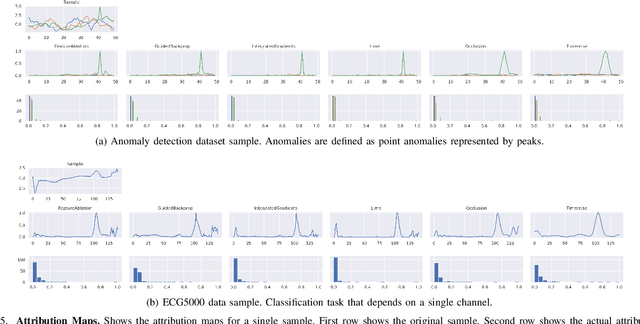
Deep neural networks are one of the most successful classifiers across different domains. However, due to their limitations concerning interpretability their use is limited in safety critical context. The research field of explainable artificial intelligence addresses this problem. However, most of the interpretability methods are aligned to the image modality by design. The paper introduces TimeREISE a model agnostic attribution method specifically aligned to success in the context of time series classification. The method shows superior performance compared to existing approaches concerning different well-established measurements. TimeREISE is applicable to any time series classification network, its runtime does not scale in a linear manner concerning the input shape and it does not rely on prior data knowledge.
Time to Focus: A Comprehensive Benchmark Using Time Series Attribution Methods
Feb 08, 2022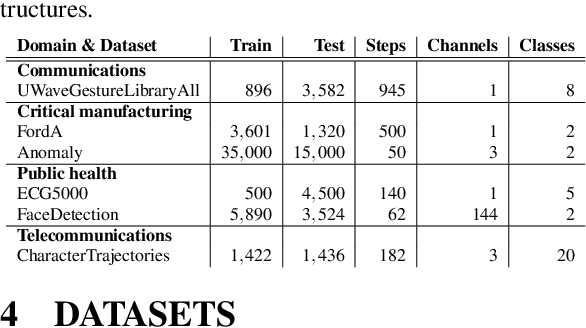

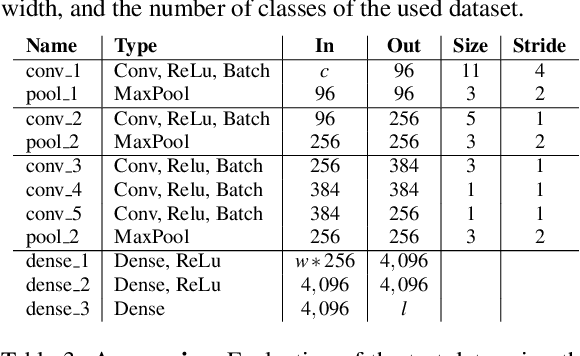
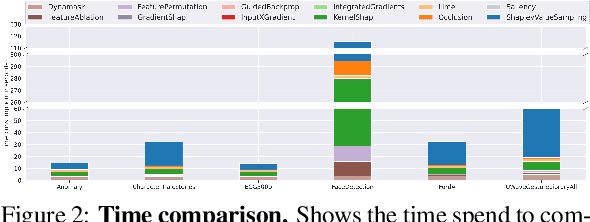
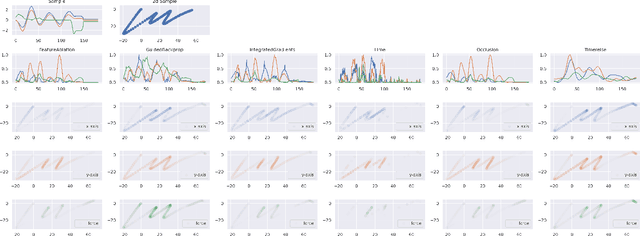
In the last decade neural network have made huge impact both in industry and research due to their ability to extract meaningful features from imprecise or complex data, and by achieving super human performance in several domains. However, due to the lack of transparency the use of these networks is hampered in the areas with safety critical areas. In safety-critical areas, this is necessary by law. Recently several methods have been proposed to uncover this black box by providing interpreation of predictions made by these models. The paper focuses on time series analysis and benchmark several state-of-the-art attribution methods which compute explanations for convolutional classifiers. The presented experiments involve gradient-based and perturbation-based attribution methods. A detailed analysis shows that perturbation-based approaches are superior concerning the Sensitivity and occlusion game. These methods tend to produce explanations with higher continuity. Contrarily, the gradient-based techniques are superb in runtime and Infidelity. In addition, a validation the dependence of the methods on the trained model, feasible application domains, and individual characteristics is attached. The findings accentuate that choosing the best-suited attribution method is strongly correlated with the desired use case. Neither category of attribution methods nor a single approach has shown outstanding performance across all aspects.
Evaluating Privacy-Preserving Machine Learning in Critical Infrastructures: A Case Study on Time-Series Classification
Nov 29, 2021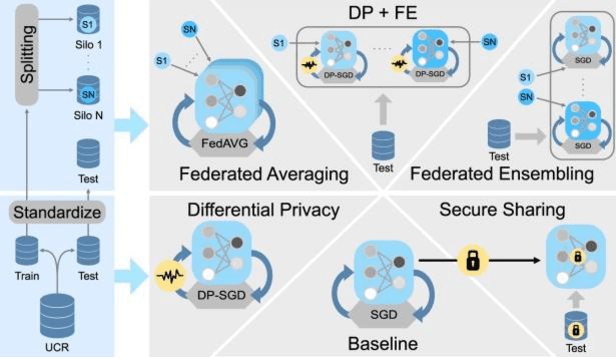
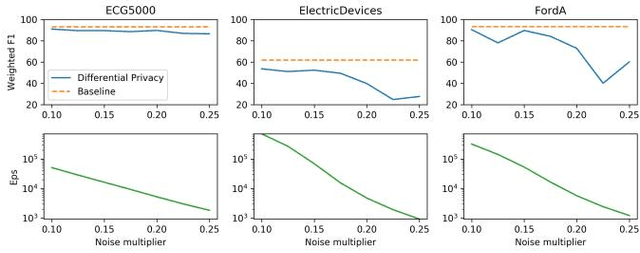
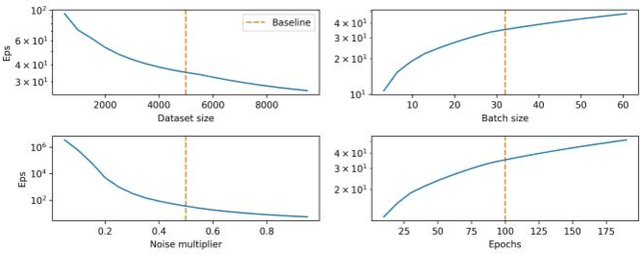
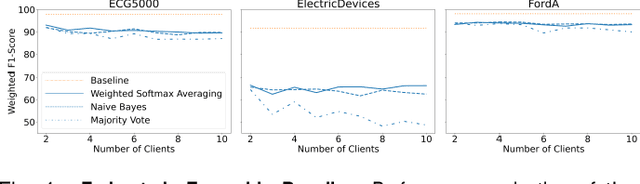
With the advent of machine learning in applications of critical infrastructure such as healthcare and energy, privacy is a growing concern in the minds of stakeholders. It is pivotal to ensure that neither the model nor the data can be used to extract sensitive information used by attackers against individuals or to harm whole societies through the exploitation of critical infrastructure. The applicability of machine learning in these domains is mostly limited due to a lack of trust regarding the transparency and the privacy constraints. Various safety-critical use cases (mostly relying on time-series data) are currently underrepresented in privacy-related considerations. By evaluating several privacy-preserving methods regarding their applicability on time-series data, we validated the inefficacy of encryption for deep learning, the strong dataset dependence of differential privacy, and the broad applicability of federated methods.
PatchX: Explaining Deep Models by Intelligible Pattern Patches for Time-series Classification
Feb 11, 2021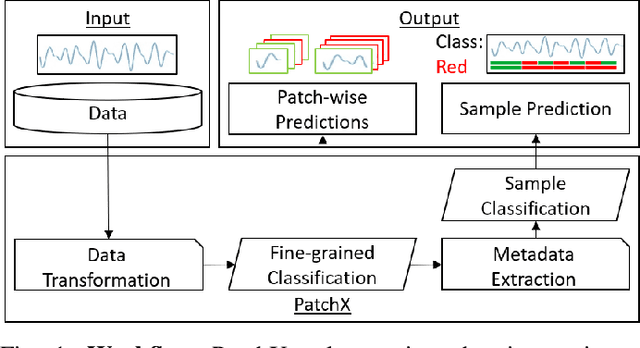
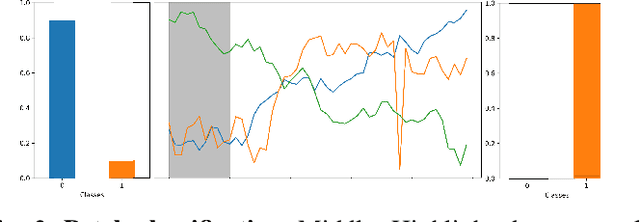
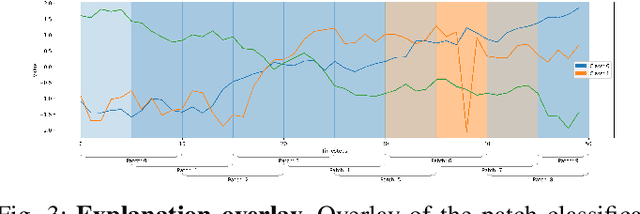
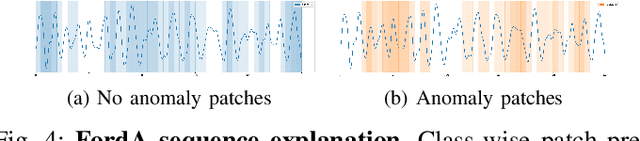
The classification of time-series data is pivotal for streaming data and comes with many challenges. Although the amount of publicly available datasets increases rapidly, deep neural models are only exploited in a few areas. Traditional methods are still used very often compared to deep neural models. These methods get preferred in safety-critical, financial, or medical fields because of their interpretable results. However, their performance and scale-ability are limited, and finding suitable explanations for time-series classification tasks is challenging due to the concepts hidden in the numerical time-series data. Visualizing complete time-series results in a cognitive overload concerning our perception and leads to confusion. Therefore, we believe that patch-wise processing of the data results in a more interpretable representation. We propose a novel hybrid approach that utilizes deep neural networks and traditional machine learning algorithms to introduce an interpretable and scale-able time-series classification approach. Our method first performs a fine-grained classification for the patches followed by sample level classification.
Interpreting Deep Models through the Lens of Data
May 19, 2020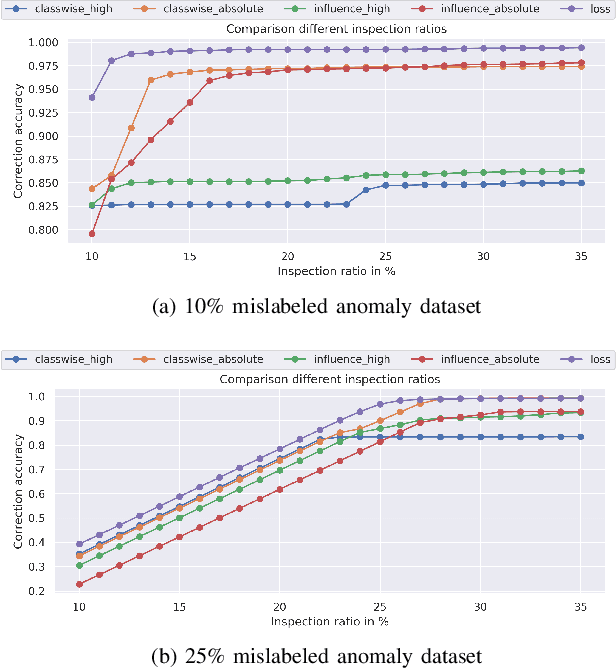
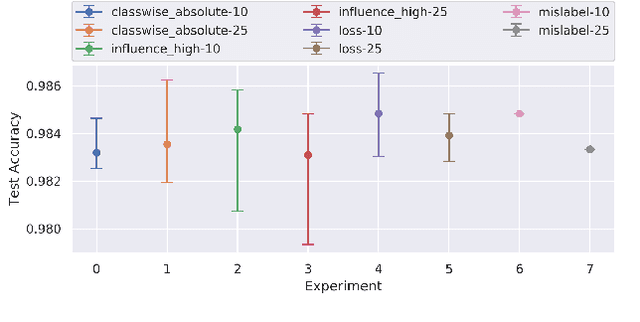
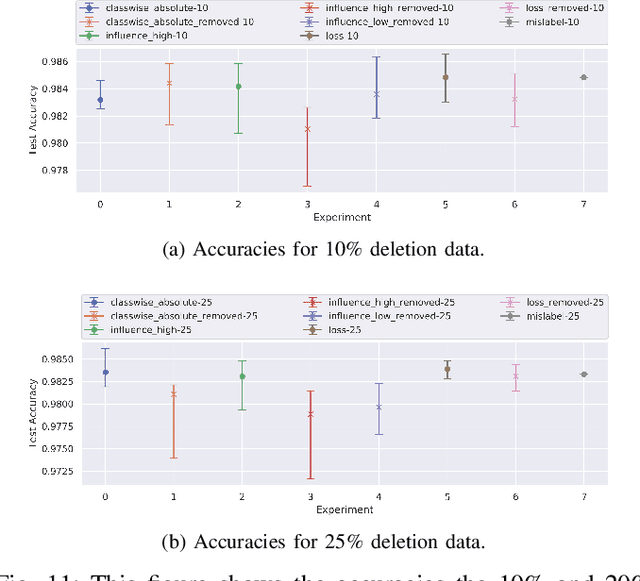
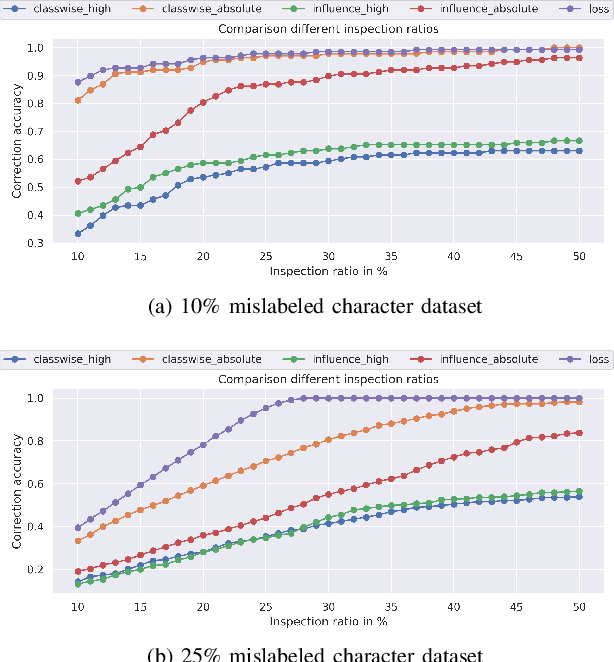
Identification of input data points relevant for the classifier (i.e. serve as the support vector) has recently spurred the interest of researchers for both interpretability as well as dataset debugging. This paper presents an in-depth analysis of the methods which attempt to identify the influence of these data points on the resulting classifier. To quantify the quality of the influence, we curated a set of experiments where we debugged and pruned the dataset based on the influence information obtained from different methods. To do so, we provided the classifier with mislabeled examples that hampered the overall performance. Since the classifier is a combination of both the data and the model, therefore, it is essential to also analyze these influences for the interpretability of deep learning models. Analysis of the results shows that some interpretability methods can detect mislabels better than using a random approach, however, contrary to the claim of these methods, the sample selection based on the training loss showed a superior performance.
P2ExNet: Patch-based Prototype Explanation Network
May 05, 2020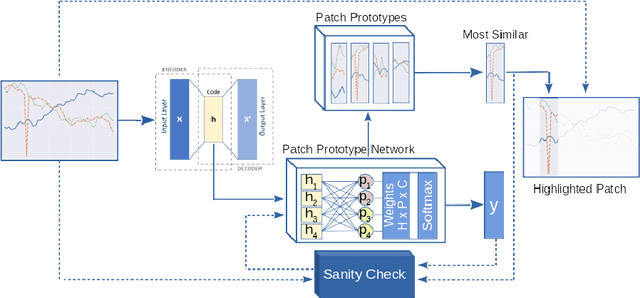
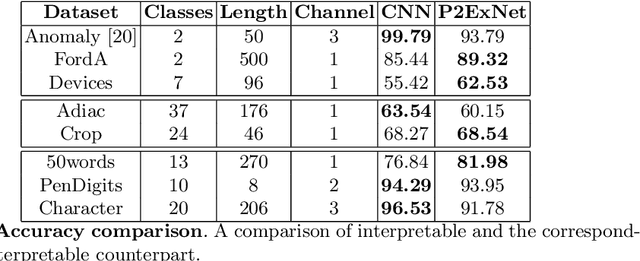


Deep learning methods have shown great success in several domains as they process a large amount of data efficiently, capable of solving complex classification, forecast, segmentation, and other tasks. However, they come with the inherent drawback of inexplicability limiting their applicability and trustworthiness. Although there exists work addressing this perspective, most of the existing approaches are limited to the image modality due to the intuitive and prominent concepts. Conversely, the concepts in the time-series domain are more complex and non-comprehensive but these and an explanation for the network decision are pivotal in critical domains like medical, financial, or industry. Addressing the need for an explainable approach, we propose a novel interpretable network scheme, designed to inherently use an explainable reasoning process inspired by the human cognition without the need of additional post-hoc explainability methods. Therefore, class-specific patches are used as they cover local concepts relevant to the classification to reveal similarities with samples of the same class. In addition, we introduce a novel loss concerning interpretability and accuracy that constraints P2ExNet to provide viable explanations of the data including relevant patches, their position, class similarities, and comparison methods without compromising accuracy. Analysis of the results on eight publicly available time-series datasets reveals that P2ExNet reaches comparable performance when compared to its counterparts while inherently providing understandable and traceable decisions.
ImpactCite: An XLNet-based method for Citation Impact Analysis
May 05, 2020

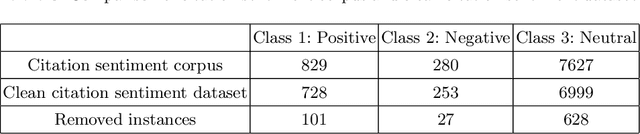
Citations play a vital role in understanding the impact of scientific literature. Generally, citations are analyzed quantitatively whereas qualitative analysis of citations can reveal deeper insights into the impact of a scientific artifact in the community. Therefore, citation impact analysis (which includes sentiment and intent classification) enables us to quantify the quality of the citations which can eventually assist us in the estimation of ranking and impact. The contribution of this paper is two-fold. First, we benchmark the well-known language models like BERT and ALBERT along with several popular networks for both tasks of sentiment and intent classification. Second, we provide ImpactCite, which is XLNet-based method for citation impact analysis. All evaluations are performed on a set of publicly available citation analysis datasets. Evaluation results reveal that ImpactCite achieves a new state-of-the-art performance for both citation intent and sentiment classification by outperforming the existing approaches by 3.44% and 1.33% in F1-score. Therefore, we emphasize ImpactCite (XLNet-based solution) for both tasks to better understand the impact of a citation. Additional efforts have been performed to come up with CSC-Clean corpus, which is a clean and reliable dataset for citation sentiment classification.