 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKnowledge Augmented Machine Learning with Applications in Autonomous Driving: A Survey
May 10, 2022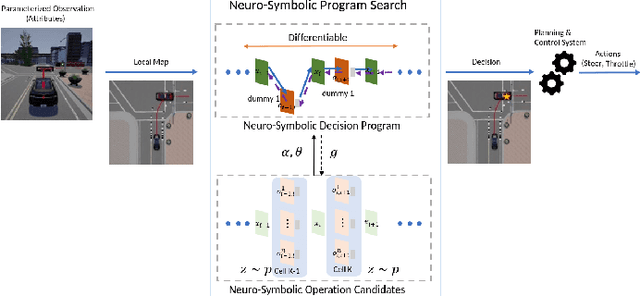
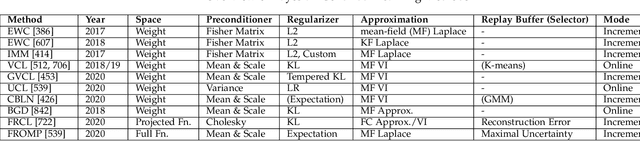
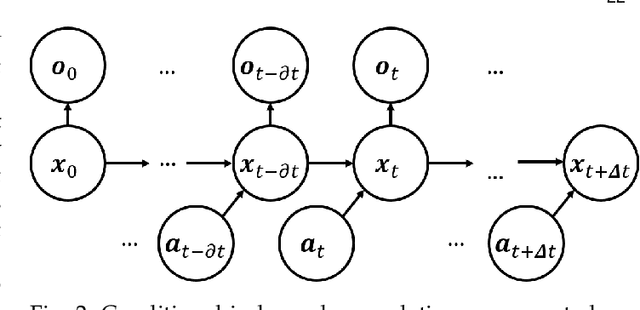
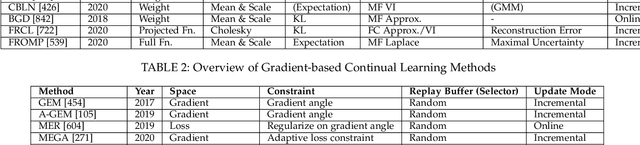
The existence of representative datasets is a prerequisite of many successful artificial intelligence and machine learning models. However, the subsequent application of these models often involves scenarios that are inadequately represented in the data used for training. The reasons for this are manifold and range from time and cost constraints to ethical considerations. As a consequence, the reliable use of these models, especially in safety-critical applications, is a huge challenge. Leveraging additional, already existing sources of knowledge is key to overcome the limitations of purely data-driven approaches, and eventually to increase the generalization capability of these models. Furthermore, predictions that conform with knowledge are crucial for making trustworthy and safe decisions even in underrepresented scenarios. This work provides an overview of existing techniques and methods in the literature that combine data-based models with existing knowledge. The identified approaches are structured according to the categories integration, extraction and conformity. Special attention is given to applications in the field of autonomous driving.
F2DNet: Fast Focal Detection Network for Pedestrian Detection
Mar 04, 2022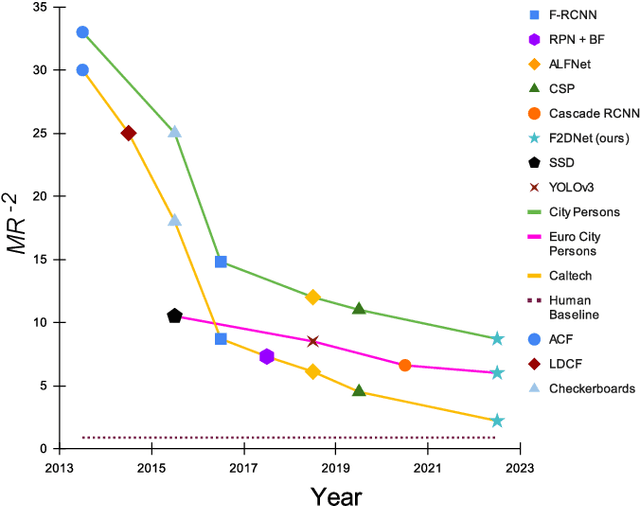
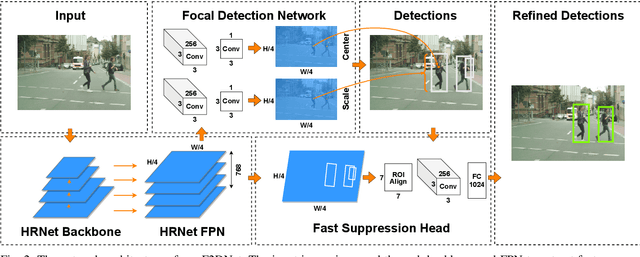

Two-stage detectors are state-of-the-art in object detection as well as pedestrian detection. However, the current two-stage detectors are inefficient as they do bounding box regression in multiple steps i.e. in region proposal networks and bounding box heads. Also, the anchor-based region proposal networks are computationally expensive to train. We propose F2DNet, a novel two-stage detection architecture which eliminates redundancy of current two-stage detectors by replacing the region proposal network with our focal detection network and bounding box head with our fast suppression head. We benchmark F2DNet on top pedestrian detection datasets, thoroughly compare it against the existing state-of-the-art detectors and conduct cross dataset evaluation to test the generalizability of our model to unseen data. Our F2DNet achieves 8.7%, 2.2%, and 6.1% MR-2 on City Persons, Caltech Pedestrian, and Euro City Person datasets respectively when trained on a single dataset and reaches 20.4% and 26.2% MR-2 in heavy occlusion setting of Caltech Pedestrian and City Persons datasets when using progressive fine-tunning. On top of that F2DNet have significantly lesser inference time compared to the current state-of-the-art. Code and trained models will be available at https://github.com/AbdulHannanKhan/F2DNet.
Evaluating Privacy-Preserving Machine Learning in Critical Infrastructures: A Case Study on Time-Series Classification
Nov 29, 2021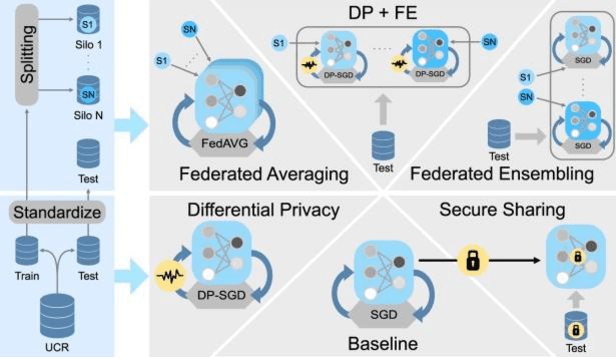
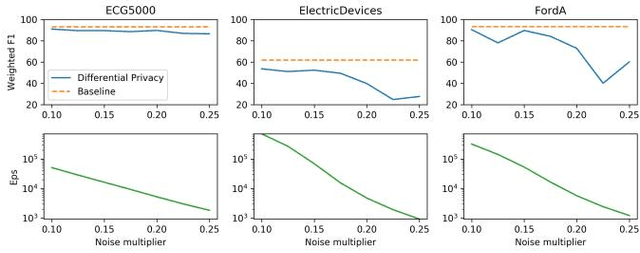
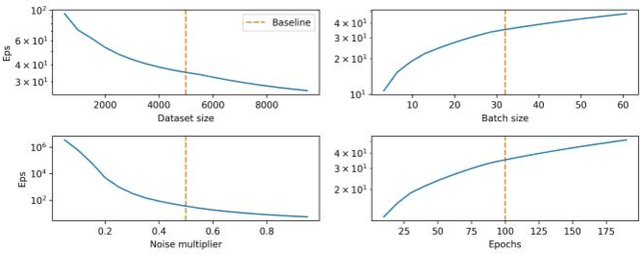
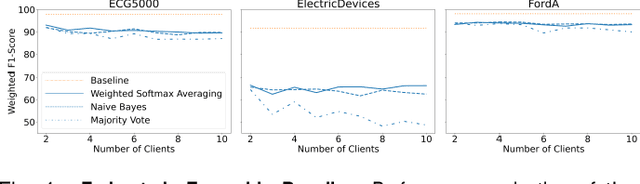
With the advent of machine learning in applications of critical infrastructure such as healthcare and energy, privacy is a growing concern in the minds of stakeholders. It is pivotal to ensure that neither the model nor the data can be used to extract sensitive information used by attackers against individuals or to harm whole societies through the exploitation of critical infrastructure. The applicability of machine learning in these domains is mostly limited due to a lack of trust regarding the transparency and the privacy constraints. Various safety-critical use cases (mostly relying on time-series data) are currently underrepresented in privacy-related considerations. By evaluating several privacy-preserving methods regarding their applicability on time-series data, we validated the inefficacy of encryption for deep learning, the strong dataset dependence of differential privacy, and the broad applicability of federated methods.
XAI Handbook: Towards a Unified Framework for Explainable AI
May 14, 2021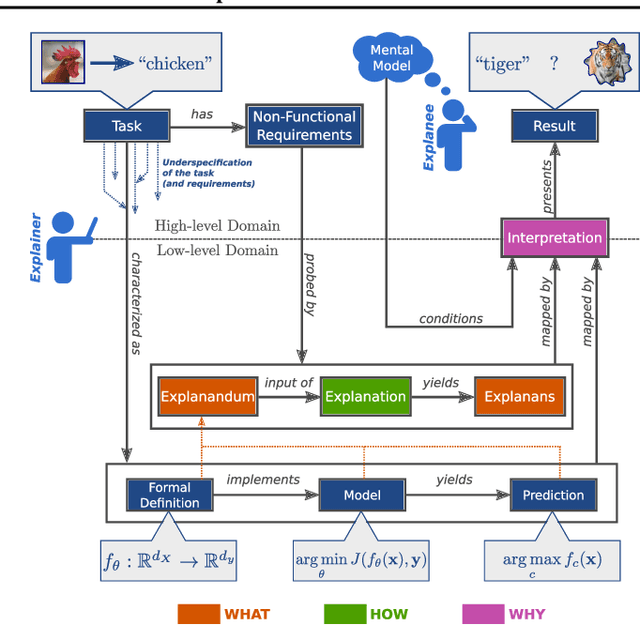
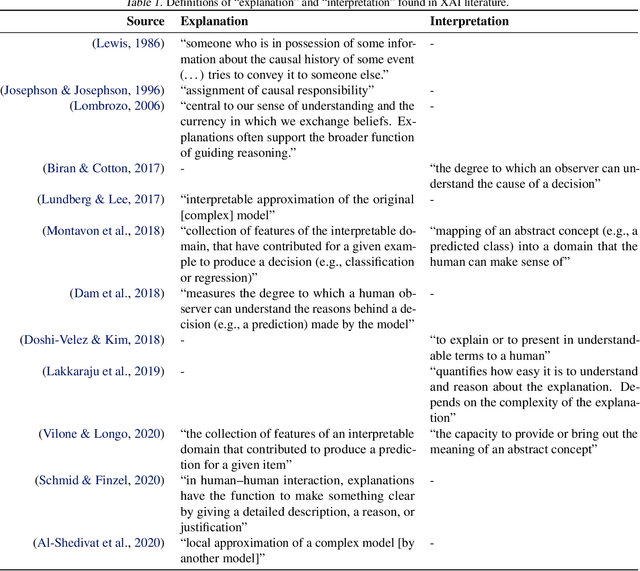

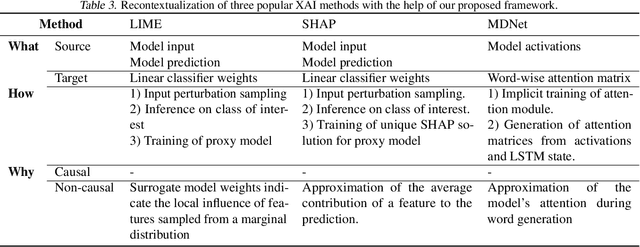
The field of explainable AI (XAI) has quickly become a thriving and prolific community. However, a silent, recurrent and acknowledged issue in this area is the lack of consensus regarding its terminology. In particular, each new contribution seems to rely on its own (and often intuitive) version of terms like "explanation" and "interpretation". Such disarray encumbers the consolidation of advances in the field towards the fulfillment of scientific and regulatory demands e.g., when comparing methods or establishing their compliance with respect to biases and fairness constraints. We propose a theoretical framework that not only provides concrete definitions for these terms, but it also outlines all steps necessary to produce explanations and interpretations. The framework also allows for existing contributions to be re-contextualized such that their scope can be measured, thus making them comparable to other methods. We show that this framework is compliant with desiderata on explanations, on interpretability and on evaluation metrics. We present a use-case showing how the framework can be used to compare LIME, SHAP and MDNet, establishing their advantages and shortcomings. Finally, we discuss relevant trends in XAI as well as recommendations for future work, all from the standpoint of our framework.
TSXplain: Demystification of DNN Decisions for Time-Series using Natural Language and Statistical Features
May 15, 2019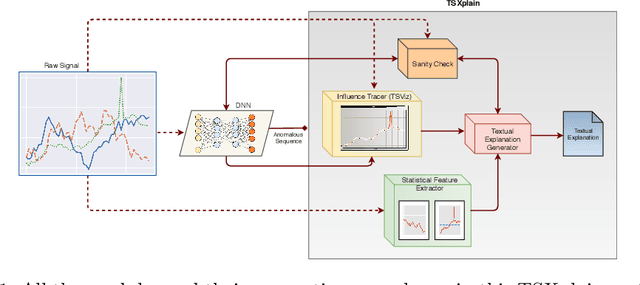


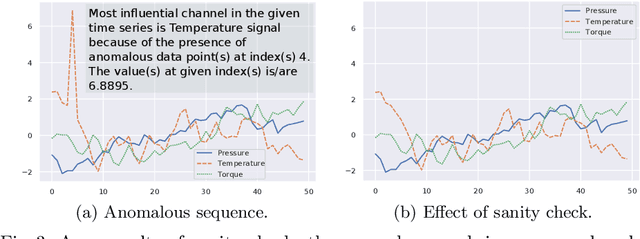
Neural networks (NN) are considered as black-boxes due to the lack of explainability and transparency of their decisions. This significantly hampers their deployment in environments where explainability is essential along with the accuracy of the system. Recently, significant efforts have been made for the interpretability of these deep networks with the aim to open up the black-box. However, most of these approaches are specifically developed for visual modalities. In addition, the interpretations provided by these systems require expert knowledge and understanding for intelligibility. This indicates a vital gap between the explainability provided by the systems and the novice user. To bridge this gap, we present a novel framework i.e. Time-Series eXplanation (TSXplain) system which produces a natural language based explanation of the decision taken by a NN. It uses the extracted statistical features to describe the decision of a NN, merging the deep learning world with that of statistics. The two-level explanation provides ample description of the decision made by the network to aid an expert as well as a novice user alike. Our survey and reliability assessment test confirm that the generated explanations are meaningful and correct. We believe that generating natural language based descriptions of the network's decisions is a big step towards opening up the black-box.
TSViz: Demystification of Deep Learning Models for Time-Series Analysis
Feb 08, 2018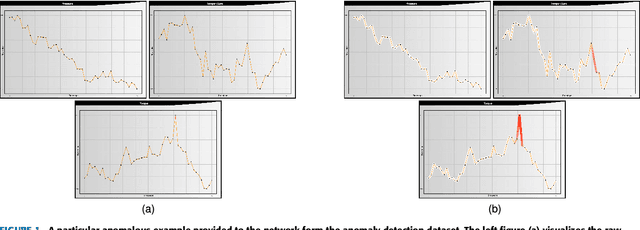


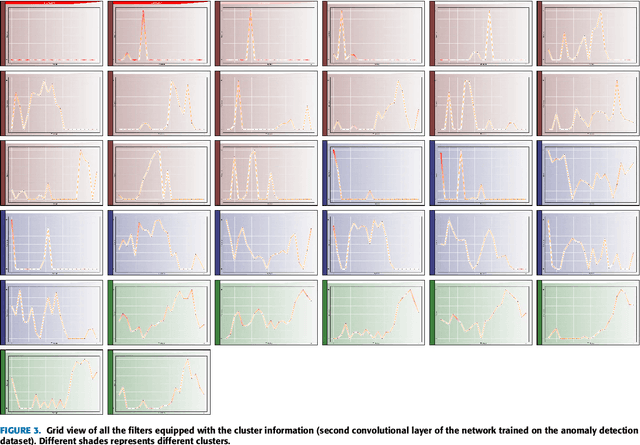
This paper presents a novel framework for demystification of convolutional deep learning models for time series analysis. This is a step towards making informed/explainable decisions in the domain of time series, powered by deep learning. There have been numerous efforts to increase the interpretability of image-centric deep neural network models, where the learned features are more intuitive to visualize. Visualization in time-series is much more complicated as there is no direct interpretation of the filters and inputs as compared to image modality. In addition, little or no concentration has been devoted for the development of such tools in the domain of time-series in the past. The visualization engine of the presented framework provides possibilities to explore and analyze a network from different dimensions at four different levels of abstraction. This enables the user to uncover different aspects of the model which includes important filters, filter clusters, and input saliency maps. These representations allow to understand the network features so that the acceptability of deep networks for time-series data can be enhanced. This is extremely important in domains like finance, industry 4.0, self-driving cars, health-care, counter-terrorism etc., where reasons for reaching a particular prediction are equally important as the prediction itself. The framework \footnote{Framework download link: https://hidden.for.blind.review} can also aid in discovery of the filters which are contributing nothing to the final prediction, hence, can be pruned without any significant loss in performance.