 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTaskFusion: Continual Anomaly Detection for Heterogeneous Tabular Data
Jun 10, 2026Continual anomaly detection in tabular data is challenging and remains largely underexplored, particularly in settings with heterogeneous feature schemas, distribution shifts, and severe class imbalance. In many real-world applications, data arrive sequentially from diverse domains, rendering conventional continual learning methods ineffective due to their reliance on a fixed input space. We propose a continual learning (CL) method, which can overcome these challenges and continually learn from different tasks. Our method consists of three main parts: our AGF model, Taskfusion augmentation, and outlier exposure. The AGF-model maps task-specific features into a shared space, then aligns distributions to reduce representation drift, and learns anomaly decision boundaries in the aligned space. To improve stability, we introduce Taskfusion augmentation, combining boundary-aware interpolation within tasks to refine the model anomaly boundaries and cross-task mixing to transfer anomaly structure across datasets. To handle class imbalance and memory constraints, we employ tabular dataset distillation to store compact synthetic replay samples, which are jointly used with augmented data in an outlier exposure objective for robust anomaly detection. We evaluate the approach on 21 heterogeneous datasets across multiple domains. Results show that our approach substantially improves continual anomaly detection performance over sequential fine-tuning and other CL baselines while reducing catastrophic forgetting and maintaining stable detection across heterogeneous datasets.
Tabular Data Adapters: Improving Outlier Detection for Unlabeled Private Data
Apr 29, 2025
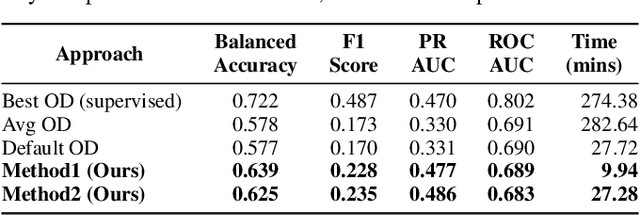


The remarkable success of Deep Learning approaches is often based and demonstrated on large public datasets. However, when applying such approaches to internal, private datasets, one frequently faces challenges arising from structural differences in the datasets, domain shift, and the lack of labels. In this work, we introduce Tabular Data Adapters (TDA), a novel method for generating soft labels for unlabeled tabular data in outlier detection tasks. By identifying statistically similar public datasets and transforming private data (based on a shared autoencoder) into a format compatible with state-of-the-art public models, our approach enables the generation of weak labels. It thereby can help to mitigate the cold start problem of labeling by basing on existing outlier detection models for public datasets. In experiments on 50 tabular datasets across different domains, we demonstrate that our method is able to provide more accurate annotations than baseline approaches while reducing computational time. Our approach offers a scalable, efficient, and cost-effective solution, to bridge the gap between public research models and real-world industrial applications.
Improving Natural Language Inference in Arabic using Transformer Models and Linguistically Informed Pre-Training
Jul 27, 2023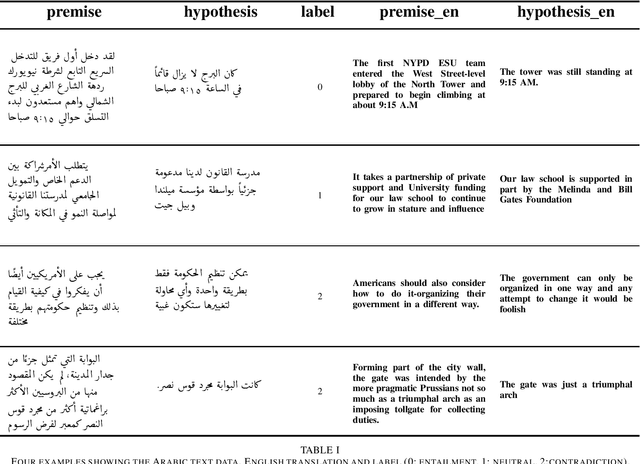


This paper addresses the classification of Arabic text data in the field of Natural Language Processing (NLP), with a particular focus on Natural Language Inference (NLI) and Contradiction Detection (CD). Arabic is considered a resource-poor language, meaning that there are few data sets available, which leads to limited availability of NLP methods. To overcome this limitation, we create a dedicated data set from publicly available resources. Subsequently, transformer-based machine learning models are being trained and evaluated. We find that a language-specific model (AraBERT) performs competitively with state-of-the-art multilingual approaches, when we apply linguistically informed pre-training methods such as Named Entity Recognition (NER). To our knowledge, this is the first large-scale evaluation for this task in Arabic, as well as the first application of multi-task pre-training in this context.
DartsReNet: Exploring new RNN cells in ReNet architectures
Apr 11, 2023We present new Recurrent Neural Network (RNN) cells for image classification using a Neural Architecture Search (NAS) approach called DARTS. We are interested in the ReNet architecture, which is a RNN based approach presented as an alternative for convolutional and pooling steps. ReNet can be defined using any standard RNN cells, such as LSTM and GRU. One limitation is that standard RNN cells were designed for one dimensional sequential data and not for two dimensions like it is the case for image classification. We overcome this limitation by using DARTS to find new cell designs. We compare our results with ReNet that uses GRU and LSTM cells. Our found cells outperform the standard RNN cells on CIFAR-10 and SVHN. The improvements on SVHN indicate generalizability, as we derived the RNN cell designs from CIFAR-10 without performing a new cell search for SVHN.
Explaining Anomalies using Denoising Autoencoders for Financial Tabular Data
Oct 03, 2022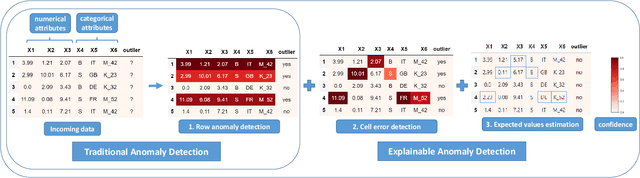
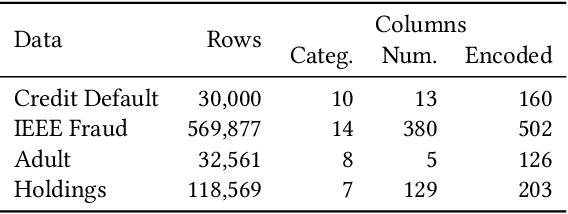
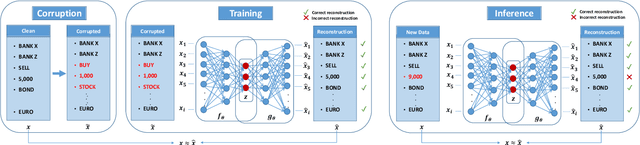
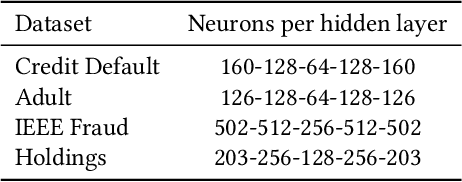
Recent advances in Explainable AI (XAI) increased the demand for deployment of safe and interpretable AI models in various industry sectors. Despite the latest success of deep neural networks in a variety of domains, understanding the decision-making process of such complex models still remains a challenging task for domain experts. Especially in the financial domain, merely pointing to an anomaly composed of often hundreds of mixed type columns, has limited value for experts. Hence, in this paper, we propose a framework for explaining anomalies using denoising autoencoders designed for mixed type tabular data. We specifically focus our technique on anomalies that are erroneous observations. This is achieved by localizing individual sample columns (cells) with potential errors and assigning corresponding confidence scores. In addition, the model provides the expected cell value estimates to fix the errors. We evaluate our approach based on three standard public tabular datasets (Credit Default, Adult, IEEE Fraud) and one proprietary dataset (Holdings). We find that denoising autoencoders applied to this task already outperform other approaches in the cell error detection rates as well as in the expected value rates. Additionally, we analyze how a specialized loss designed for cell error detection can further improve these metrics. Our framework is designed for a domain expert to understand abnormal characteristics of an anomaly, as well as to improve in-house data quality management processes.
Hitchhiker's Guide to Super-Resolution: Introduction and Recent Advances
Sep 27, 2022
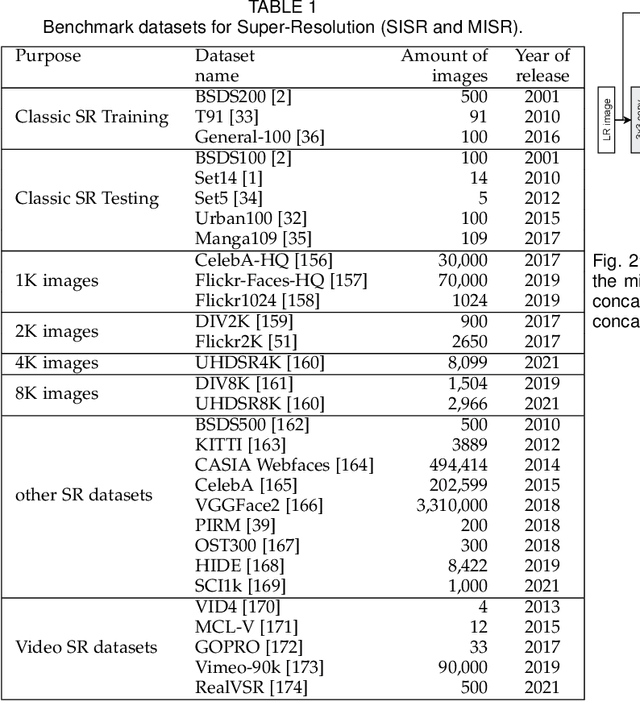
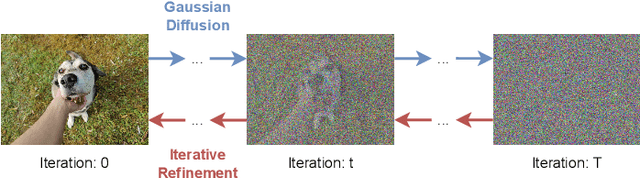
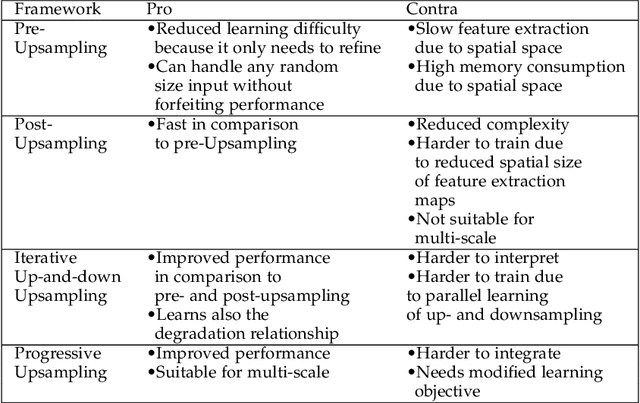
With the advent of Deep Learning (DL), Super-Resolution (SR) has also become a thriving research area. However, despite promising results, the field still faces challenges that require further research e.g., allowing flexible upsampling, more effective loss functions, and better evaluation metrics. We review the domain of SR in light of recent advances, and examine state-of-the-art models such as diffusion (DDPM) and transformer-based SR models. We present a critical discussion on contemporary strategies used in SR, and identify promising yet unexplored research directions. We complement previous surveys by incorporating the latest developments in the field such as uncertainty-driven losses, wavelet networks, neural architecture search, novel normalization methods, and the latests evaluation techniques. We also include several visualizations for the models and methods throughout each chapter in order to facilitate a global understanding of the trends in the field. This review is ultimately aimed at helping researchers to push the boundaries of DL applied to SR.
DT2I: Dense Text-to-Image Generation from Region Descriptions
Apr 05, 2022
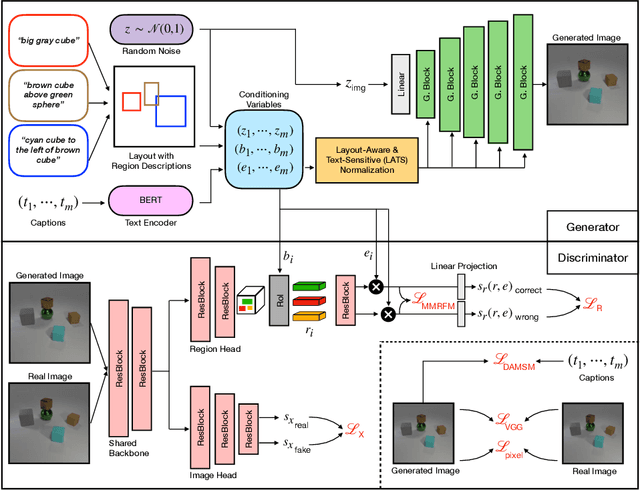
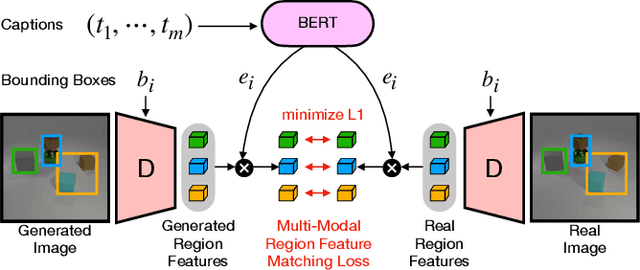
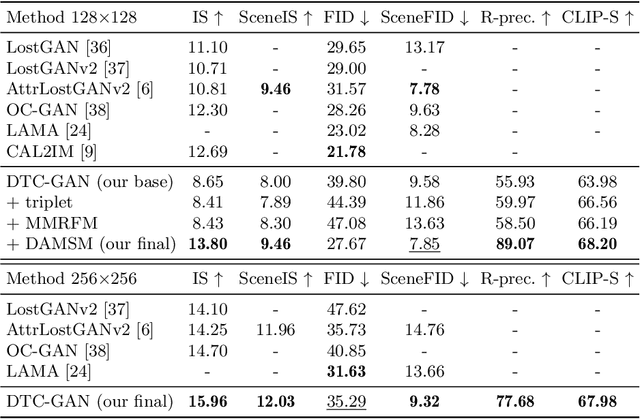
Despite astonishing progress, generating realistic images of complex scenes remains a challenging problem. Recently, layout-to-image synthesis approaches have attracted much interest by conditioning the generator on a list of bounding boxes and corresponding class labels. However, previous approaches are very restrictive because the set of labels is fixed a priori. Meanwhile, text-to-image synthesis methods have substantially improved and provide a flexible way for conditional image generation. In this work, we introduce dense text-to-image (DT2I) synthesis as a new task to pave the way toward more intuitive image generation. Furthermore, we propose DTC-GAN, a novel method to generate images from semantically rich region descriptions, and a multi-modal region feature matching loss to encourage semantic image-text matching. Our results demonstrate the capability of our approach to generate plausible images of complex scenes using region captions.
Less is More: Proxy Datasets in NAS approaches
Mar 14, 2022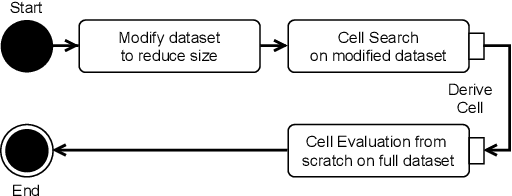
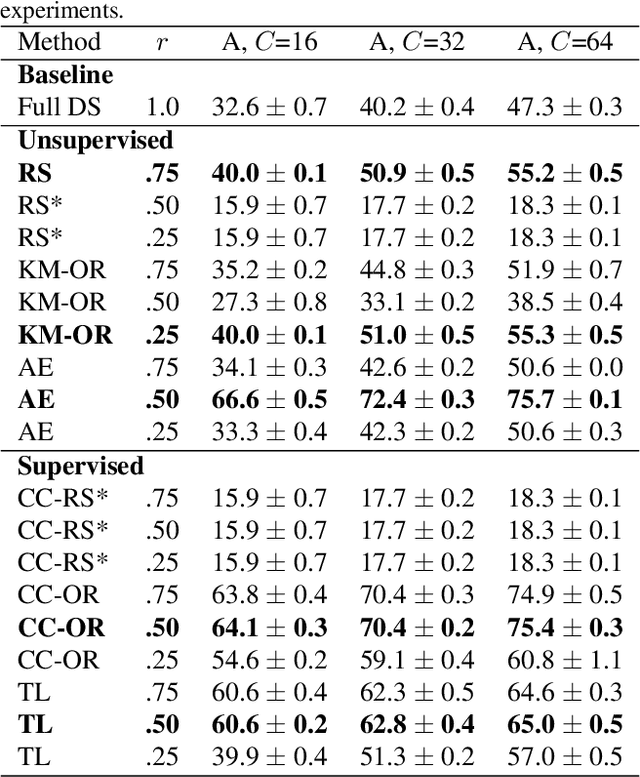
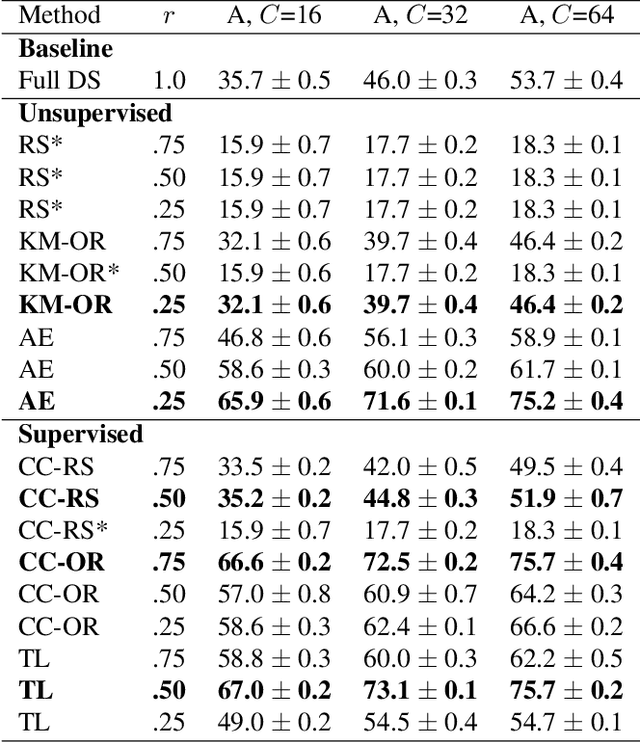
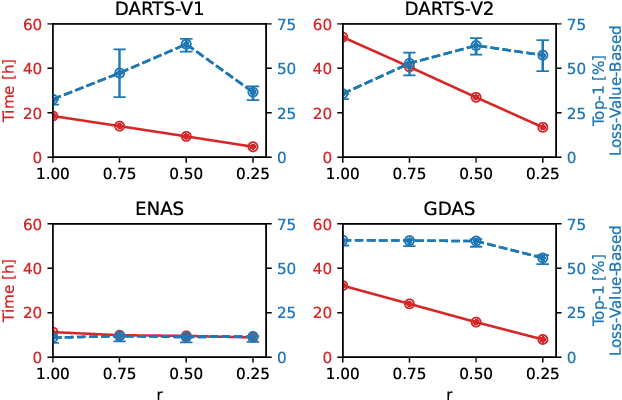
Neural Architecture Search (NAS) defines the design of Neural Networks as a search problem. Unfortunately, NAS is computationally intensive because of various possibilities depending on the number of elements in the design and the possible connections between them. In this work, we extensively analyze the role of the dataset size based on several sampling approaches for reducing the dataset size (unsupervised and supervised cases) as an agnostic approach to reduce search time. We compared these techniques with four common NAS approaches in NAS-Bench-201 in roughly 1,400 experiments on CIFAR-100. One of our surprising findings is that in most cases we can reduce the amount of training data to 25\%, consequently reducing search time to 25\%, while at the same time maintaining the same accuracy as if training on the full dataset. Additionally, some designs derived from subsets out-perform designs derived from the full dataset by up to 22 p.p. accuracy.
Spatial Transformer Networks for Curriculum Learning
Aug 22, 2021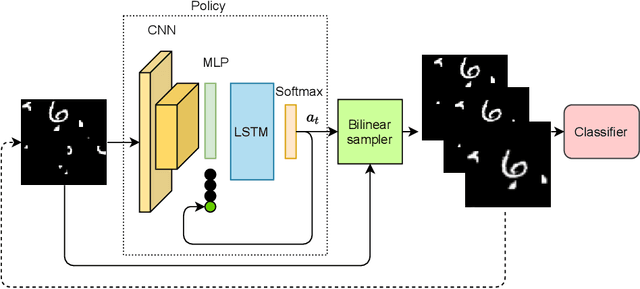



Curriculum learning is a bio-inspired training technique that is widely adopted to machine learning for improved optimization and better training of neural networks regarding the convergence rate or obtained accuracy. The main concept in curriculum learning is to start the training with simpler tasks and gradually increase the level of difficulty. Therefore, a natural question is how to determine or generate these simpler tasks. In this work, we take inspiration from Spatial Transformer Networks (STNs) in order to form an easy-to-hard curriculum. As STNs have been proven to be capable of removing the clutter from the input images and obtaining higher accuracy in image classification tasks, we hypothesize that images processed by STNs can be seen as easier tasks and utilized in the interest of curriculum learning. To this end, we study multiple strategies developed for shaping the training curriculum, using the data generated by STNs. We perform various experiments on cluttered MNIST and Fashion-MNIST datasets, where on the former, we obtain an improvement of $3.8$pp in classification accuracy compared to the baseline.
AudioCLIP: Extending CLIP to Image, Text and Audio
Jun 24, 2021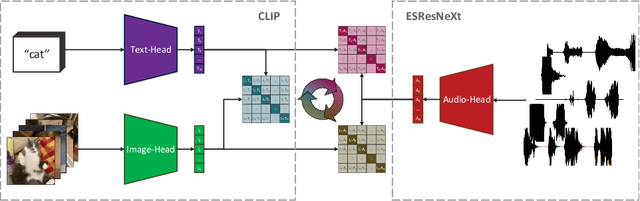

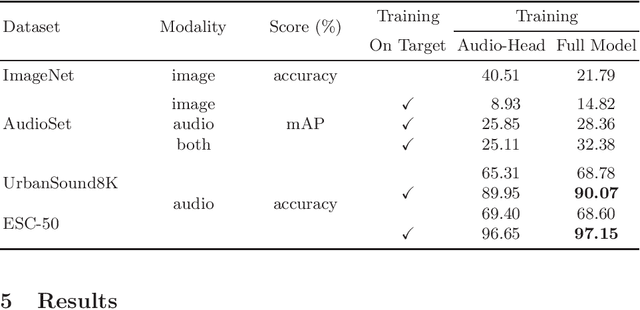

In the past, the rapidly evolving field of sound classification greatly benefited from the application of methods from other domains. Today, we observe the trend to fuse domain-specific tasks and approaches together, which provides the community with new outstanding models. In this work, we present an extension of the CLIP model that handles audio in addition to text and images. Our proposed model incorporates the ESResNeXt audio-model into the CLIP framework using the AudioSet dataset. Such a combination enables the proposed model to perform bimodal and unimodal classification and querying, while keeping CLIP's ability to generalize to unseen datasets in a zero-shot inference fashion. AudioCLIP achieves new state-of-the-art results in the Environmental Sound Classification (ESC) task, out-performing other approaches by reaching accuracies of 90.07% on the UrbanSound8K and 97.15% on the ESC-50 datasets. Further it sets new baselines in the zero-shot ESC-task on the same datasets 68.78% and 69.40%, respectively). Finally, we also assess the cross-modal querying performance of the proposed model as well as the influence of full and partial training on the results. For the sake of reproducibility, our code is published.