 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiffusion-Scheduled Denoising Autoencoders for Anomaly Detection in Tabular Data
Aug 01, 2025Anomaly detection in tabular data remains challenging due to complex feature interactions and the scarcity of anomalous examples. Denoising autoencoders rely on fixed-magnitude noise, limiting adaptability to diverse data distributions. Diffusion models introduce scheduled noise and iterative denoising, but lack explicit reconstruction mappings. We propose the Diffusion-Scheduled Denoising Autoencoder (DDAE), a framework that integrates diffusion-based noise scheduling and contrastive learning into the encoding process to improve anomaly detection. We evaluated DDAE on 57 datasets from ADBench. Our method outperforms in semi-supervised settings and achieves competitive results in unsupervised settings, improving PR-AUC by up to 65% (9%) and ROC-AUC by 16% (6%) over state-of-the-art autoencoder (diffusion) model baselines. We observed that higher noise levels benefit unsupervised training, while lower noise with linear scheduling is optimal in semi-supervised settings. These findings underscore the importance of principled noise strategies in tabular anomaly detection.
Differentially Private Federated Learning of Diffusion Models for Synthetic Tabular Data Generation
Dec 20, 2024



The increasing demand for privacy-preserving data analytics in finance necessitates solutions for synthetic data generation that rigorously uphold privacy standards. We introduce DP-Fed-FinDiff framework, a novel integration of Differential Privacy, Federated Learning and Denoising Diffusion Probabilistic Models designed to generate high-fidelity synthetic tabular data. This framework ensures compliance with stringent privacy regulations while maintaining data utility. We demonstrate the effectiveness of DP-Fed-FinDiff on multiple real-world financial datasets, achieving significant improvements in privacy guarantees without compromising data quality. Our empirical evaluations reveal the optimal trade-offs between privacy budgets, client configurations, and federated optimization strategies. The results affirm the potential of DP-Fed-FinDiff to enable secure data sharing and robust analytics in highly regulated domains, paving the way for further advances in federated learning and privacy-preserving data synthesis.
FedTabDiff: Federated Learning of Diffusion Probabilistic Models for Synthetic Mixed-Type Tabular Data Generation
Jan 11, 2024Realistic synthetic tabular data generation encounters significant challenges in preserving privacy, especially when dealing with sensitive information in domains like finance and healthcare. In this paper, we introduce \textit{Federated Tabular Diffusion} (FedTabDiff) for generating high-fidelity mixed-type tabular data without centralized access to the original tabular datasets. Leveraging the strengths of \textit{Denoising Diffusion Probabilistic Models} (DDPMs), our approach addresses the inherent complexities in tabular data, such as mixed attribute types and implicit relationships. More critically, FedTabDiff realizes a decentralized learning scheme that permits multiple entities to collaboratively train a generative model while respecting data privacy and locality. We extend DDPMs into the federated setting for tabular data generation, which includes a synchronous update scheme and weighted averaging for effective model aggregation. Experimental evaluations on real-world financial and medical datasets attest to the framework's capability to produce synthetic data that maintains high fidelity, utility, privacy, and coverage.
FinDiff: Diffusion Models for Financial Tabular Data Generation
Sep 04, 2023The sharing of microdata, such as fund holdings and derivative instruments, by regulatory institutions presents a unique challenge due to strict data confidentiality and privacy regulations. These challenges often hinder the ability of both academics and practitioners to conduct collaborative research effectively. The emergence of generative models, particularly diffusion models, capable of synthesizing data mimicking the underlying distributions of real-world data presents a compelling solution. This work introduces 'FinDiff', a diffusion model designed to generate real-world financial tabular data for a variety of regulatory downstream tasks, for example economic scenario modeling, stress tests, and fraud detection. The model uses embedding encodings to model mixed modality financial data, comprising both categorical and numeric attributes. The performance of FinDiff in generating synthetic tabular financial data is evaluated against state-of-the-art baseline models using three real-world financial datasets (including two publicly available datasets and one proprietary dataset). Empirical results demonstrate that FinDiff excels in generating synthetic tabular financial data with high fidelity, privacy, and utility.
Explaining Anomalies using Denoising Autoencoders for Financial Tabular Data
Oct 03, 2022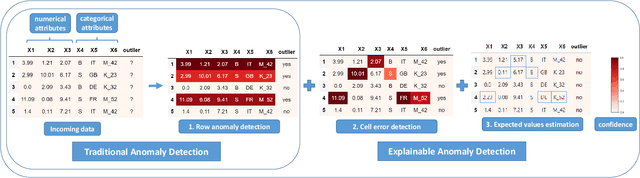
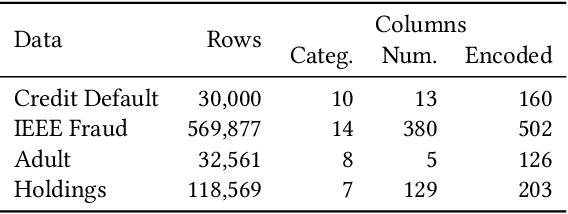
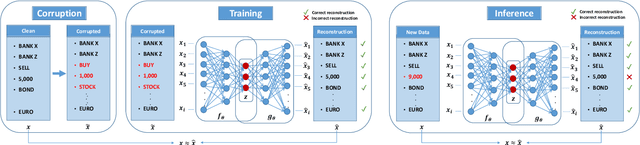
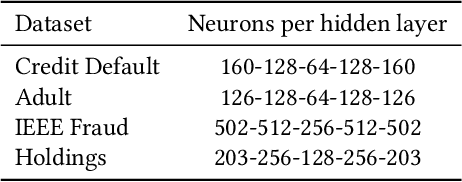
Recent advances in Explainable AI (XAI) increased the demand for deployment of safe and interpretable AI models in various industry sectors. Despite the latest success of deep neural networks in a variety of domains, understanding the decision-making process of such complex models still remains a challenging task for domain experts. Especially in the financial domain, merely pointing to an anomaly composed of often hundreds of mixed type columns, has limited value for experts. Hence, in this paper, we propose a framework for explaining anomalies using denoising autoencoders designed for mixed type tabular data. We specifically focus our technique on anomalies that are erroneous observations. This is achieved by localizing individual sample columns (cells) with potential errors and assigning corresponding confidence scores. In addition, the model provides the expected cell value estimates to fix the errors. We evaluate our approach based on three standard public tabular datasets (Credit Default, Adult, IEEE Fraud) and one proprietary dataset (Holdings). We find that denoising autoencoders applied to this task already outperform other approaches in the cell error detection rates as well as in the expected value rates. Additionally, we analyze how a specialized loss designed for cell error detection can further improve these metrics. Our framework is designed for a domain expert to understand abnormal characteristics of an anomaly, as well as to improve in-house data quality management processes.
RESHAPE: Explaining Accounting Anomalies in Financial Statement Audits by enhancing SHapley Additive exPlanations
Sep 19, 2022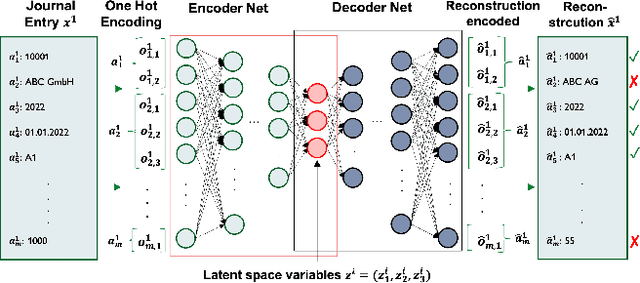


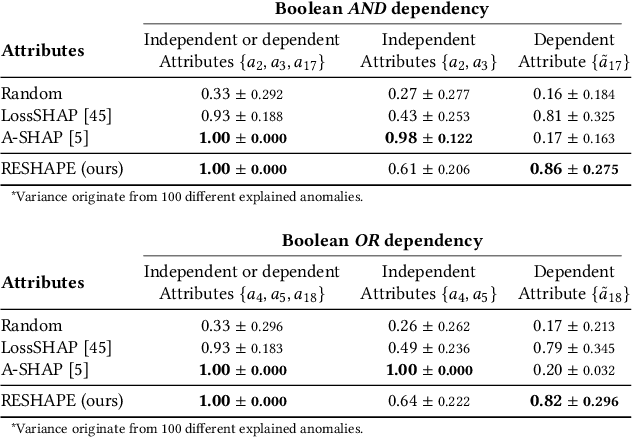
Detecting accounting anomalies is a recurrent challenge in financial statement audits. Recently, novel methods derived from Deep-Learning (DL) have been proposed to audit the large volumes of a statement's underlying accounting records. However, due to their vast number of parameters, such models exhibit the drawback of being inherently opaque. At the same time, the concealing of a model's inner workings often hinders its real-world application. This observation holds particularly true in financial audits since auditors must reasonably explain and justify their audit decisions. Nowadays, various Explainable AI (XAI) techniques have been proposed to address this challenge, e.g., SHapley Additive exPlanations (SHAP). However, in unsupervised DL as often applied in financial audits, these methods explain the model output at the level of encoded variables. As a result, the explanations of Autoencoder Neural Networks (AENNs) are often hard to comprehend by human auditors. To mitigate this drawback, we propose (RESHAPE), which explains the model output on an aggregated attribute-level. In addition, we introduce an evaluation framework to compare the versatility of XAI methods in auditing. Our experimental results show empirical evidence that RESHAPE results in versatile explanations compared to state-of-the-art baselines. We envision such attribute-level explanations as a necessary next step in the adoption of unsupervised DL techniques in financial auditing.
Federated and Privacy-Preserving Learning of Accounting Data in Financial Statement Audits
Aug 26, 2022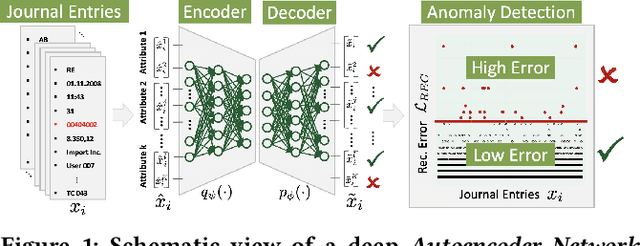
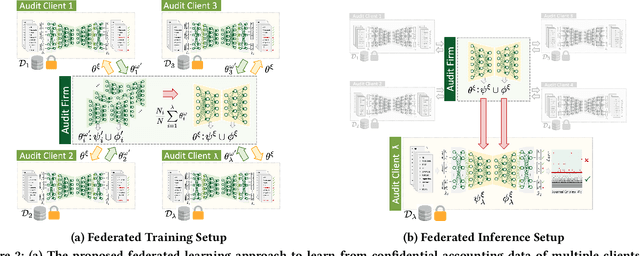
The ongoing 'digital transformation' fundamentally changes audit evidence's nature, recording, and volume. Nowadays, the International Standards on Auditing (ISA) requires auditors to examine vast volumes of a financial statement's underlying digital accounting records. As a result, audit firms also 'digitize' their analytical capabilities and invest in Deep Learning (DL), a successful sub-discipline of Machine Learning. The application of DL offers the ability to learn specialized audit models from data of multiple clients, e.g., organizations operating in the same industry or jurisdiction. In general, regulations require auditors to adhere to strict data confidentiality measures. At the same time, recent intriguing discoveries showed that large-scale DL models are vulnerable to leaking sensitive training data information. Today, it often remains unclear how audit firms can apply DL models while complying with data protection regulations. In this work, we propose a Federated Learning framework to train DL models on auditing relevant accounting data of multiple clients. The framework encompasses Differential Privacy and Split Learning capabilities to mitigate data confidentiality risks at model inference. We evaluate our approach to detect accounting anomalies in three real-world datasets of city payments. Our results provide empirical evidence that auditors can benefit from DL models that accumulate knowledge from multiple sources of proprietary client data.
Multi-view Contrastive Self-Supervised Learning of Accounting Data Representations for Downstream Audit Tasks
Sep 23, 2021

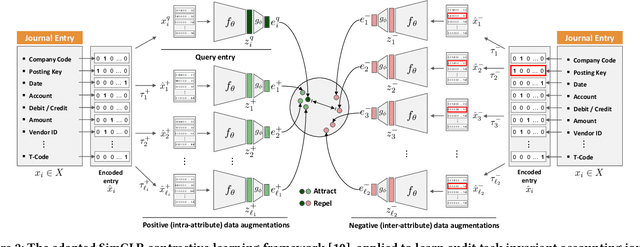

International audit standards require the direct assessment of a financial statement's underlying accounting transactions, referred to as journal entries. Recently, driven by the advances in artificial intelligence, deep learning inspired audit techniques have emerged in the field of auditing vast quantities of journal entry data. Nowadays, the majority of such methods rely on a set of specialized models, each trained for a particular audit task. At the same time, when conducting a financial statement audit, audit teams are confronted with (i) challenging time-budget constraints, (ii) extensive documentation obligations, and (iii) strict model interpretability requirements. As a result, auditors prefer to harness only a single preferably `multi-purpose' model throughout an audit engagement. We propose a contrastive self-supervised learning framework designed to learn audit task invariant accounting data representations to meet this requirement. The framework encompasses deliberate interacting data augmentation policies that utilize the attribute characteristics of journal entry data. We evaluate the framework on two real-world datasets of city payments and transfer the learned representations to three downstream audit tasks: anomaly detection, audit sampling, and audit documentation. Our experimental results provide empirical evidence that the proposed framework offers the ability to increase the efficiency of audits by learning rich and interpretable `multi-task' representations.
Learning Sampling in Financial Statement Audits using Vector Quantised Autoencoder Neural Networks
Aug 06, 2020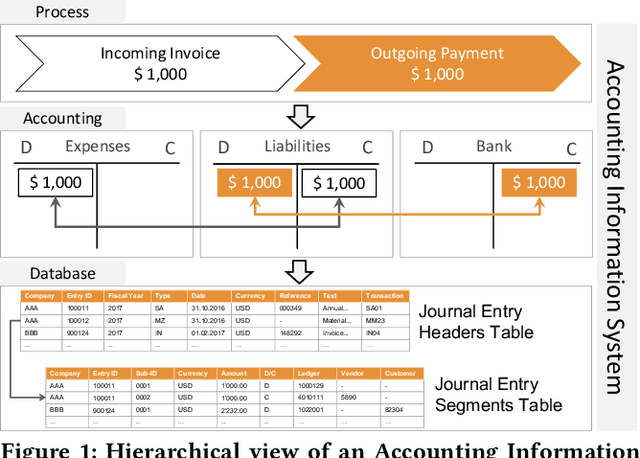

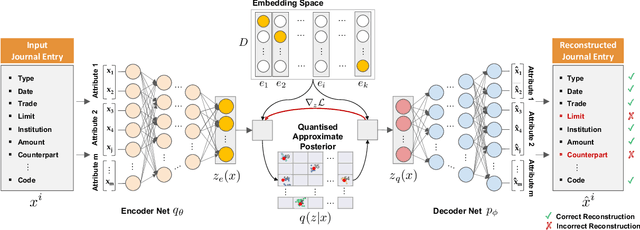
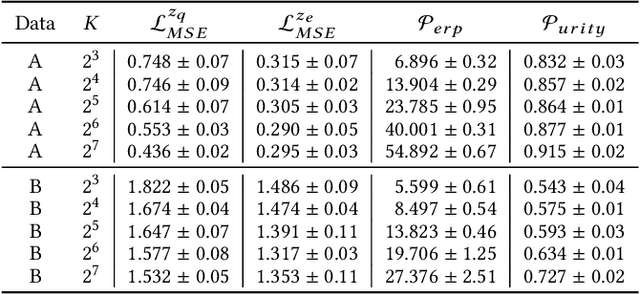
The audit of financial statements is designed to collect reasonable assurance that an issued statement is free from material misstatement 'true and fair presentation'. International audit standards require the assessment of a statements' underlying accounting relevant transactions referred to as 'journal entries' to detect potential misstatements. To efficiently audit the increasing quantities of such entries, auditors regularly conduct a sample-based assessment referred to as 'audit sampling'. However, the task of audit sampling is often conducted early in the overall audit process. Often at a stage, in which an auditor might be unaware of all generative factors and their dynamics that resulted in the journal entries in-scope of the audit. To overcome this challenge, we propose the application of Vector Quantised-Variational Autoencoder (VQ-VAE) neural networks. We demonstrate, based on two real-world city payment datasets, that such artificial neural networks are capable of learning a quantised representation of accounting data. We show that the learned quantisation uncovers (i) the latent factors of variation and (ii) can be utilised as a highly representative audit sample in financial statement audits.
Adversarial Learning of Deepfakes in Accounting
Oct 09, 2019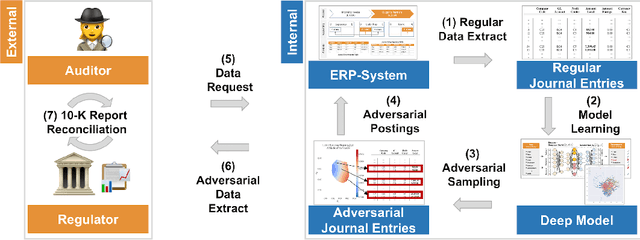
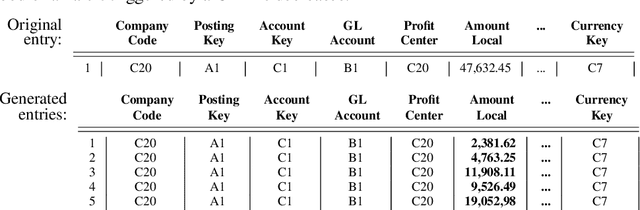
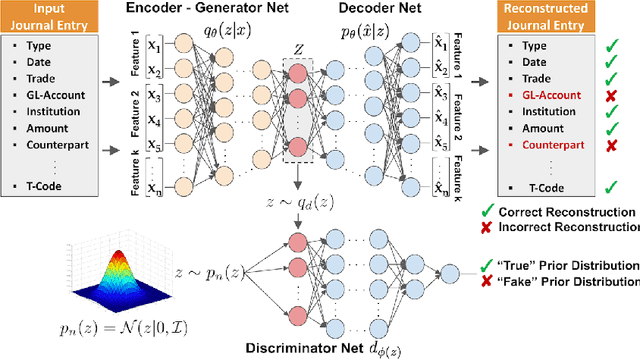
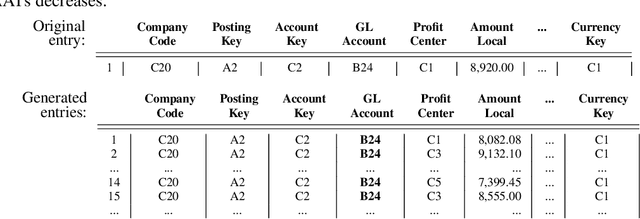
Nowadays, organizations collect vast quantities of accounting relevant transactions, referred to as 'journal entries', in 'Enterprise Resource Planning' (ERP) systems. The aggregation of those entries ultimately defines an organization's financial statement. To detect potential misstatements and fraud, international audit standards demand auditors to directly assess journal entries using 'Computer Assisted AuditTechniques' (CAATs). At the same time, discoveries in deep learning research revealed that machine learning models are vulnerable to 'adversarial attacks'. It also became evident that such attack techniques can be misused to generate 'Deepfakes' designed to directly attack the perception of humans by creating convincingly altered media content. The research of such developments and their potential impact on the finance and accounting domain is still in its early stage. We believe that it is of vital relevance to investigate how such techniques could be maliciously misused in this sphere. In this work, we show an adversarial attack against CAATs using deep neural networks. We first introduce a real-world 'thread model' designed to camouflage accounting anomalies such as fraudulent journal entries. Second, we show that adversarial autoencoder neural networks are capable of learning a human interpretable model of journal entries that disentangles the entries latent generative factors. Finally, we demonstrate how such a model can be maliciously misused by a perpetrator to generate robust 'adversarial' journal entries that mislead CAATs.