 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluating Generative Models for Tabular Data: Novel Metrics and Benchmarking
Apr 29, 2025Generative models have revolutionized multiple domains, yet their application to tabular data remains underexplored. Evaluating generative models for tabular data presents unique challenges due to structural complexity, large-scale variability, and mixed data types, making it difficult to intuitively capture intricate patterns. Existing evaluation metrics offer only partial insights, lacking a comprehensive measure of generative performance. To address this limitation, we propose three novel evaluation metrics: FAED, FPCAD, and RFIS. Our extensive experimental analysis, conducted on three standard network intrusion detection datasets, compares these metrics with established evaluation methods such as Fidelity, Utility, TSTR, and TRTS. Our results demonstrate that FAED effectively captures generative modeling issues overlooked by existing metrics. While FPCAD exhibits promising performance, further refinements are necessary to enhance its reliability. Our proposed framework provides a robust and practical approach for assessing generative models in tabular data applications.
Tabular Data Adapters: Improving Outlier Detection for Unlabeled Private Data
Apr 29, 2025
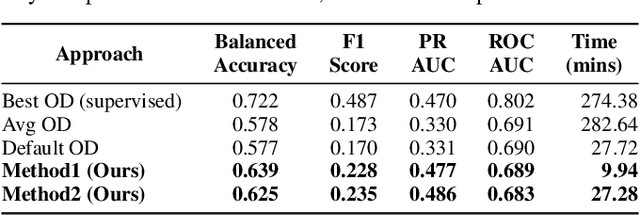


The remarkable success of Deep Learning approaches is often based and demonstrated on large public datasets. However, when applying such approaches to internal, private datasets, one frequently faces challenges arising from structural differences in the datasets, domain shift, and the lack of labels. In this work, we introduce Tabular Data Adapters (TDA), a novel method for generating soft labels for unlabeled tabular data in outlier detection tasks. By identifying statistically similar public datasets and transforming private data (based on a shared autoencoder) into a format compatible with state-of-the-art public models, our approach enables the generation of weak labels. It thereby can help to mitigate the cold start problem of labeling by basing on existing outlier detection models for public datasets. In experiments on 50 tabular datasets across different domains, we demonstrate that our method is able to provide more accurate annotations than baseline approaches while reducing computational time. Our approach offers a scalable, efficient, and cost-effective solution, to bridge the gap between public research models and real-world industrial applications.
FedAD-Bench: A Unified Benchmark for Federated Unsupervised Anomaly Detection in Tabular Data
Aug 08, 2024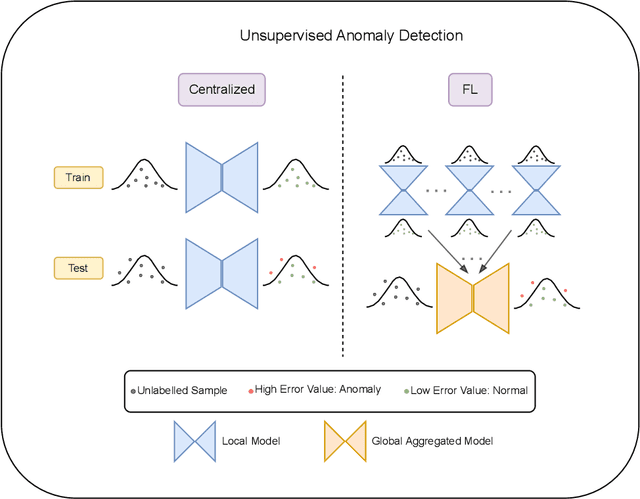



The emergence of federated learning (FL) presents a promising approach to leverage decentralized data while preserving privacy. Furthermore, the combination of FL and anomaly detection is particularly compelling because it allows for detecting rare and critical anomalies (usually also rare in locally gathered data) in sensitive data from multiple sources, such as cybersecurity and healthcare. However, benchmarking the performance of anomaly detection methods in FL environments remains an underexplored area. This paper introduces FedAD-Bench, a unified benchmark for evaluating unsupervised anomaly detection algorithms within the context of FL. We systematically analyze and compare the performance of recent deep learning anomaly detection models under federated settings, which were typically assessed solely in centralized settings. FedAD-Bench encompasses diverse datasets and metrics to provide a holistic evaluation. Through extensive experiments, we identify key challenges such as model aggregation inefficiencies and metric unreliability. We present insights into FL's regularization effects, revealing scenarios in which it outperforms centralized approaches due to its inherent ability to mitigate overfitting. Our work aims to establish a standardized benchmark to guide future research and development in federated anomaly detection, promoting reproducibility and fair comparison across studies.
Fin-Fed-OD: Federated Outlier Detection on Financial Tabular Data
Apr 23, 2024



Anomaly detection in real-world scenarios poses challenges due to dynamic and often unknown anomaly distributions, requiring robust methods that operate under an open-world assumption. This challenge is exacerbated in practical settings, where models are employed by private organizations, precluding data sharing due to privacy and competitive concerns. Despite potential benefits, the sharing of anomaly information across organizations is restricted. This paper addresses the question of enhancing outlier detection within individual organizations without compromising data confidentiality. We propose a novel method leveraging representation learning and federated learning techniques to improve the detection of unknown anomalies. Specifically, our approach utilizes latent representations obtained from client-owned autoencoders to refine the decision boundary of inliers. Notably, only model parameters are shared between organizations, preserving data privacy. The efficacy of our proposed method is evaluated on two standard financial tabular datasets and an image dataset for anomaly detection in a distributed setting. The results demonstrate a strong improvement in the classification of unknown outliers during the inference phase for each organization's model.
Explaining Anomalies using Denoising Autoencoders for Financial Tabular Data
Oct 03, 2022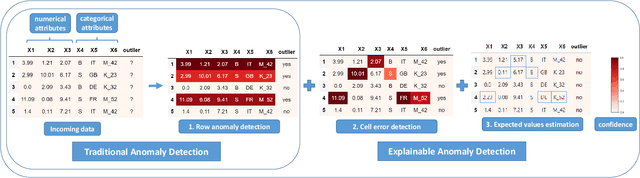
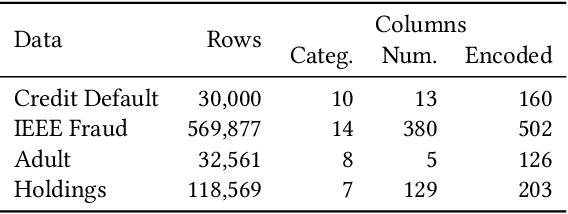
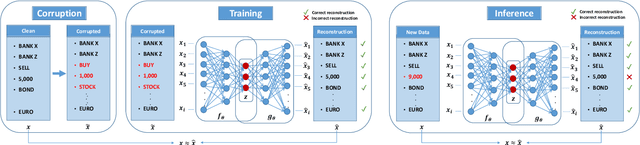
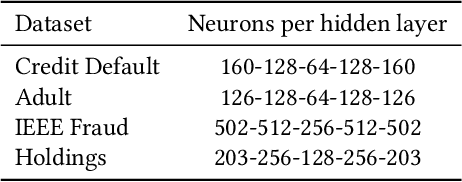
Recent advances in Explainable AI (XAI) increased the demand for deployment of safe and interpretable AI models in various industry sectors. Despite the latest success of deep neural networks in a variety of domains, understanding the decision-making process of such complex models still remains a challenging task for domain experts. Especially in the financial domain, merely pointing to an anomaly composed of often hundreds of mixed type columns, has limited value for experts. Hence, in this paper, we propose a framework for explaining anomalies using denoising autoencoders designed for mixed type tabular data. We specifically focus our technique on anomalies that are erroneous observations. This is achieved by localizing individual sample columns (cells) with potential errors and assigning corresponding confidence scores. In addition, the model provides the expected cell value estimates to fix the errors. We evaluate our approach based on three standard public tabular datasets (Credit Default, Adult, IEEE Fraud) and one proprietary dataset (Holdings). We find that denoising autoencoders applied to this task already outperform other approaches in the cell error detection rates as well as in the expected value rates. Additionally, we analyze how a specialized loss designed for cell error detection can further improve these metrics. Our framework is designed for a domain expert to understand abnormal characteristics of an anomaly, as well as to improve in-house data quality management processes.
RECol: Reconstruction Error Columns for Outlier Detection
Feb 04, 2021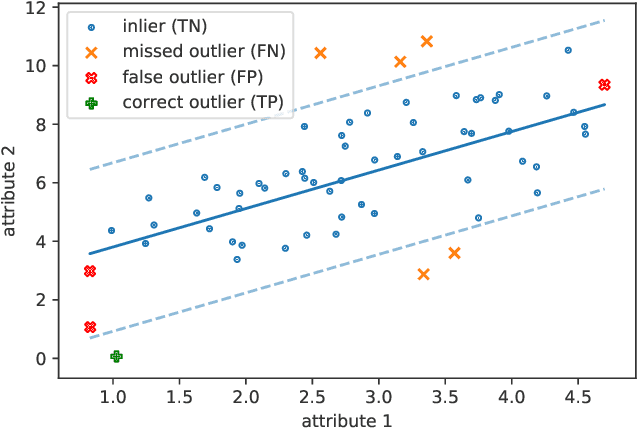
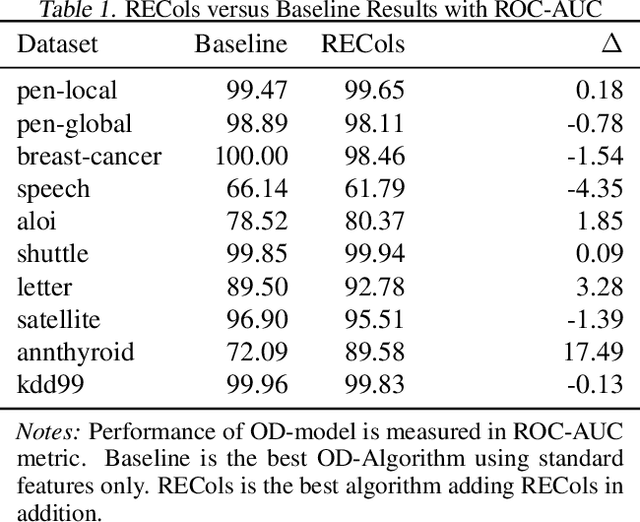
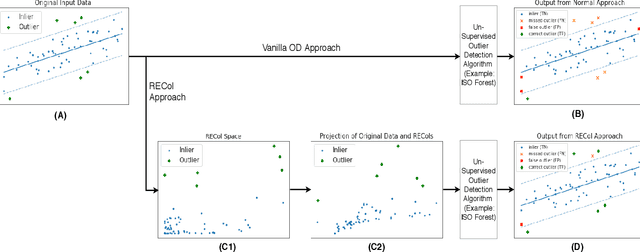
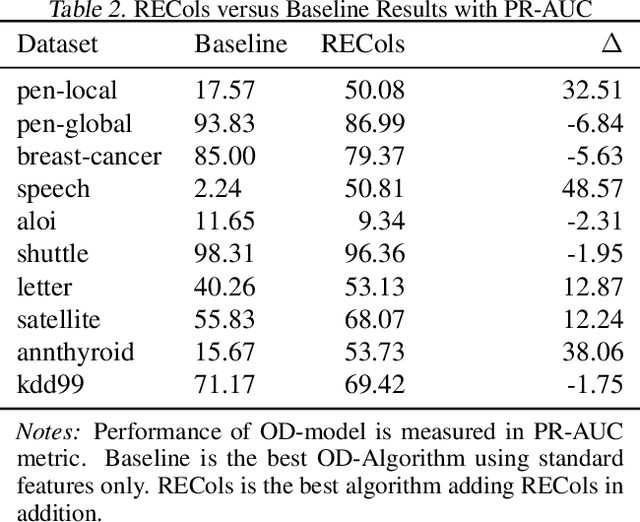
Detecting outliers or anomalies is a common data analysis task. As a sub-field of unsupervised machine learning, a large variety of approaches exist, but the vast majority treats the input features as independent and often fails to recognize even simple (linear) relationships in the input feature space. Hence, we introduce RECol, a generic data pre-processing approach to generate additional columns in a leave-one-out-fashion: For each column, we try to predict its values based on the other columns, generating reconstruction error columns. We run experiments across a large variety of common baseline approaches and benchmark datasets with and without our RECol pre-processing method and show that the generated reconstruction error feature space generally seems to support common outlier detection methods and often considerably improves their ROC-AUC and PR-AUC values.