 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOA-CutMix: Correcting the Label Bias of CutMix
Jun 03, 2026CutMix has become the de facto standard mixing augmentation, yet its label assignment rests on a flawed assumption: The area of the pasted patch faithfully reflects its semantic contribution to the mixed image. In practice, however, patches frequently land on background regions, assigning label credit to classes whose objects are not visible. The mean discrepancy of the CutMix label and the semantic object area is $21.5\%$. In $17\%$ of samples an image contributes zero visible object pixels yet receives nonzero label weight. We propose Object-Aware CutMix (OA-CutMix), which corrects this bias by replacing the area-based CutMix weight with one derived from precomputed segmentation masks, assigning labels in proportion to the visible object area each image contributes to the mix. The image mixing procedure is left entirely unchanged. We evaluate OA-CutMix against 10+ static and dynamic mixing methods across 4 architectures and 6 datasets. OA-CutMix consistently achieves the highest accuracy over all tasks, outperforming even dynamic mixing methods, but at a fraction of the training-time cost. Improvements are largest for small objects, where the label bias from CutMix is greatest. Thus, correcting the label is sufficient to match or exceed the performance of methods modifying the image mixing algorithm.
TextTeacher: What Can Language Teach About Images?
May 21, 2026The platonic representation hypothesis suggests that sufficiently large models converge to a shared representation geometry, even across modalities. Motivated by this, we ask: Can the semantic knowledge of a language model efficiently improve a vision model? As an answer, we introduce TextTeacher, a simple auxiliary objective that injects text embeddings as additional information into image classification training. TextTeacher uses readily available image captions, a pre-trained and frozen text encoder, and a lightweight projection to produce semantic anchors that efficiently guide representations during training while leaving the inference-time model unchanged. On ImageNet with standard ViT backbones, TextTeacher improves accuracy by up to +2.7 percentage points (p.p.) and yields consistent transfer gains (on average +1.0 p.p.) under the same recipe and compute. It outperforms vision knowledge distillation, yielding more accuracy at a constant compute budget or similar accuracy, but 33% faster. Our analysis indicates that TextTeacher acts as a feature-space preconditioner, shaping deeper layers in the first stages of training, and aiding generalization by supplying complementary semantic cues. TextTeacher adds negligible overhead, requires no costly multimodal training of the target model and preserves the simplicity and latency of pure vision models. Project page with code and captions: https://nauen-it.de/publications/text-teacher
* Published at TMLR
When Pretty Isn't Useful: Investigating Why Modern Text-to-Image Models Fail as Reliable Training Data Generators
Feb 24, 2026Recent text-to-image (T2I) diffusion models produce visually stunning images and demonstrate excellent prompt following. But do they perform well as synthetic vision data generators? In this work, we revisit the promise of synthetic data as a scalable substitute for real training sets and uncover a surprising performance regression. We generate large-scale synthetic datasets using state-of-the-art T2I models released between 2022 and 2025, train standard classifiers solely on this synthetic data, and evaluate them on real test data. Despite observable advances in visual fidelity and prompt adherence, classification accuracy on real test data consistently declines with newer T2I models as training data generators. Our analysis reveals a hidden trend: These models collapse to a narrow, aesthetic-centric distribution that undermines diversity and label-image alignment. Overall, our findings challenge a growing assumption in vision research, namely that progress in generative realism implies progress in data realism. We thus highlight an urgent need to rethink the capabilities of modern T2I models as reliable training data generators.
PRISM: Diversifying Dataset Distillation by Decoupling Architectural Priors
Nov 13, 2025Dataset distillation (DD) promises compact yet faithful synthetic data, but existing approaches often inherit the inductive bias of a single teacher model. As dataset size increases, this bias drives generation toward overly smooth, homogeneous samples, reducing intra-class diversity and limiting generalization. We present PRISM (PRIors from diverse Source Models), a framework that disentangles architectural priors during synthesis. PRISM decouples the logit-matching and regularization objectives, supervising them with different teacher architectures: a primary model for logits and a stochastic subset for batch-normalization (BN) alignment. On ImageNet-1K, PRISM consistently and reproducibly outperforms single-teacher methods (e.g., SRe2L) and recent multi-teacher variants (e.g., G-VBSM) at low- and mid-IPC regimes. The generated data also show significantly richer intra-class diversity, as reflected by a notable drop in cosine similarity between features. We further analyze teacher selection strategies (pre- vs. intra-distillation) and introduce a scalable cross-class batch formation scheme for fast parallel synthesis. Code will be released after the review period.
A Coreset Selection of Coreset Selection Literature: Introduction and Recent Advances
May 23, 2025Coreset selection targets the challenge of finding a small, representative subset of a large dataset that preserves essential patterns for effective machine learning. Although several surveys have examined data reduction strategies before, most focus narrowly on either classical geometry-based methods or active learning techniques. In contrast, this survey presents a more comprehensive view by unifying three major lines of coreset research, namely, training-free, training-oriented, and label-free approaches, into a single taxonomy. We present subfields often overlooked by existing work, including submodular formulations, bilevel optimization, and recent progress in pseudo-labeling for unlabeled datasets. Additionally, we examine how pruning strategies influence generalization and neural scaling laws, offering new insights that are absent from prior reviews. Finally, we compare these methods under varying computational, robustness, and performance demands and highlight open challenges, such as robustness, outlier filtering, and adapting coreset selection to foundation models, for future research.
ForAug: Recombining Foregrounds and Backgrounds to Improve Vision Transformer Training with Bias Mitigation
Mar 12, 2025Transformers, particularly Vision Transformers (ViTs), have achieved state-of-the-art performance in large-scale image classification. However, they often require large amounts of data and can exhibit biases that limit their robustness and generalizability. This paper introduces ForAug, a novel data augmentation scheme that addresses these challenges and explicitly includes inductive biases, which commonly are part of the neural network architecture, into the training data. ForAug is constructed by using pretrained foundation models to separate and recombine foreground objects with different backgrounds, enabling fine-grained control over image composition during training. It thus increases the data diversity and effective number of training samples. We demonstrate that training on ForNet, the application of ForAug to ImageNet, significantly improves the accuracy of ViTs and other architectures by up to 4.5 percentage points (p.p.) on ImageNet and 7.3 p.p. on downstream tasks. Importantly, ForAug enables novel ways of analyzing model behavior and quantifying biases. Namely, we introduce metrics for background robustness, foreground focus, center bias, and size bias and show that training on ForNet substantially reduces these biases compared to training on ImageNet. In summary, ForAug provides a valuable tool for analyzing and mitigating biases, enabling the development of more robust and reliable computer vision models. Our code and dataset are publicly available at https://github.com/tobna/ForAug.
A Study in Dataset Distillation for Image Super-Resolution
Feb 05, 2025



Dataset distillation is the concept of condensing large datasets into smaller but highly representative synthetic samples. While previous research has primarily focused on image classification, its application to image Super-Resolution (SR) remains underexplored. This exploratory work studies multiple dataset distillation techniques applied to SR, including pixel- and latent-space approaches under different aspects. Our experiments demonstrate that a 91.12% dataset size reduction can be achieved while maintaining comparable SR performance to the full dataset. We further analyze initialization strategies and distillation methods to optimize memory efficiency and computational costs. Our findings provide new insights into dataset distillation for SR and set the stage for future advancements.
Zoomed In, Diffused Out: Towards Local Degradation-Aware Multi-Diffusion for Extreme Image Super-Resolution
Nov 18, 2024



Large-scale, pre-trained Text-to-Image (T2I) diffusion models have gained significant popularity in image generation tasks and have shown unexpected potential in image Super-Resolution (SR). However, most existing T2I diffusion models are trained with a resolution limit of 512x512, making scaling beyond this resolution an unresolved but necessary challenge for image SR. In this work, we introduce a novel approach that, for the first time, enables these models to generate 2K, 4K, and even 8K images without any additional training. Our method leverages MultiDiffusion, which distributes the generation across multiple diffusion paths to ensure global coherence at larger scales, and local degradation-aware prompt extraction, which guides the T2I model to reconstruct fine local structures according to its low-resolution input. These innovations unlock higher resolutions, allowing T2I diffusion models to be applied to image SR tasks without limitation on resolution.
Just Leaf It: Accelerating Diffusion Classifiers with Hierarchical Class Pruning
Nov 18, 2024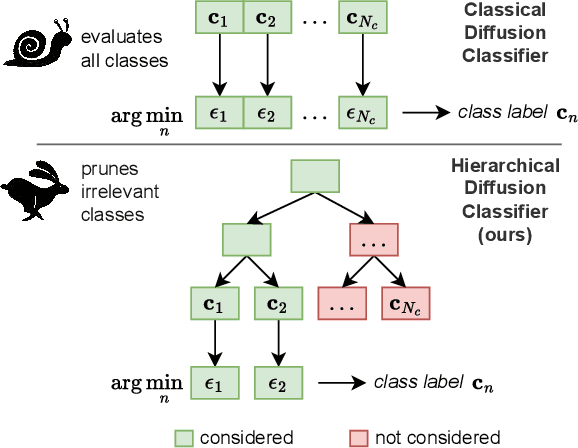

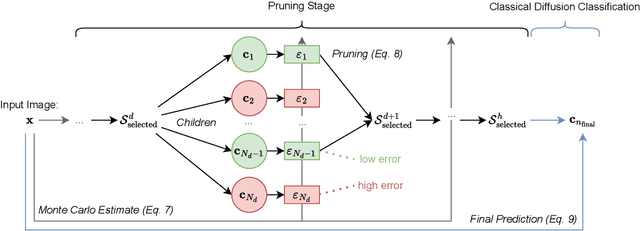

Diffusion models, known for their generative capabilities, have recently shown unexpected potential in image classification tasks by using Bayes' theorem. However, most diffusion classifiers require evaluating all class labels for a single classification, leading to significant computational costs that can hinder their application in large-scale scenarios. To address this, we present a Hierarchical Diffusion Classifier (HDC) that exploits the inherent hierarchical label structure of a dataset. By progressively pruning irrelevant high-level categories and refining predictions only within relevant subcategories, i.e., leaf nodes, HDC reduces the total number of class evaluations. As a result, HDC can accelerate inference by up to 60% while maintaining and, in some cases, improving classification accuracy. Our work enables a new control mechanism of the trade-off between speed and precision, making diffusion-based classification more viable for real-world applications, particularly in large-scale image classification tasks.
Distill the Best, Ignore the Rest: Improving Dataset Distillation with Loss-Value-Based Pruning
Nov 18, 2024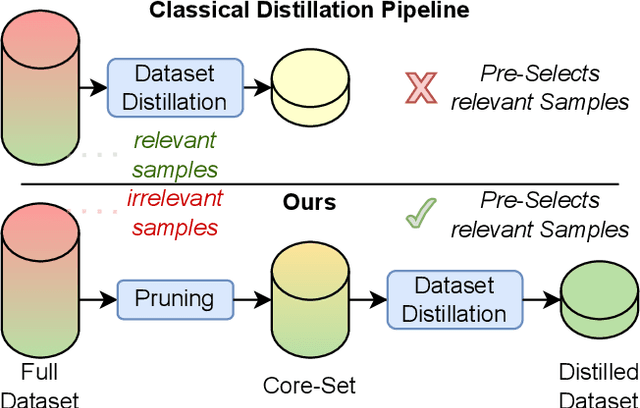

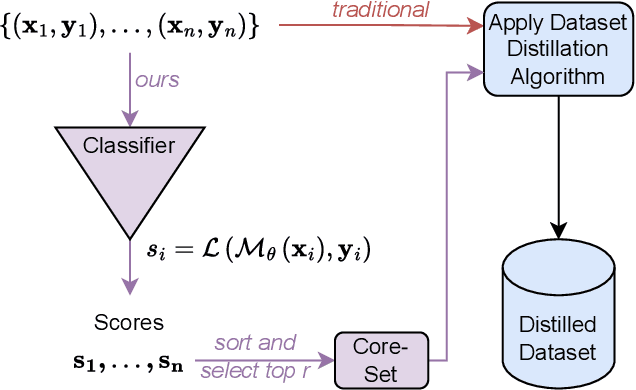
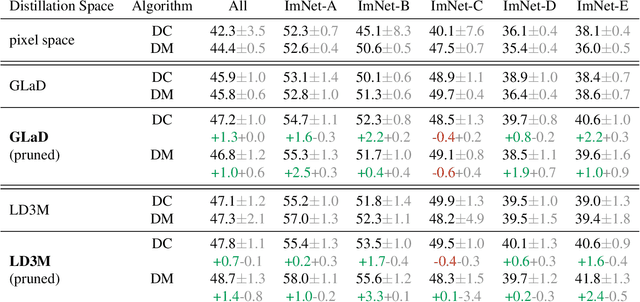
Dataset distillation has gained significant interest in recent years, yet existing approaches typically distill from the entire dataset, potentially including non-beneficial samples. We introduce a novel "Prune First, Distill After" framework that systematically prunes datasets via loss-based sampling prior to distillation. By leveraging pruning before classical distillation techniques and generative priors, we create a representative core-set that leads to enhanced generalization for unseen architectures - a significant challenge of current distillation methods. More specifically, our proposed framework significantly boosts distilled quality, achieving up to a 5.2 percentage points accuracy increase even with substantial dataset pruning, i.e., removing 80% of the original dataset prior to distillation. Overall, our experimental results highlight the advantages of our easy-sample prioritization and cross-architecture robustness, paving the way for more effective and high-quality dataset distillation.