 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDistill the Best, Ignore the Rest: Improving Dataset Distillation with Loss-Value-Based Pruning
Paper and Code
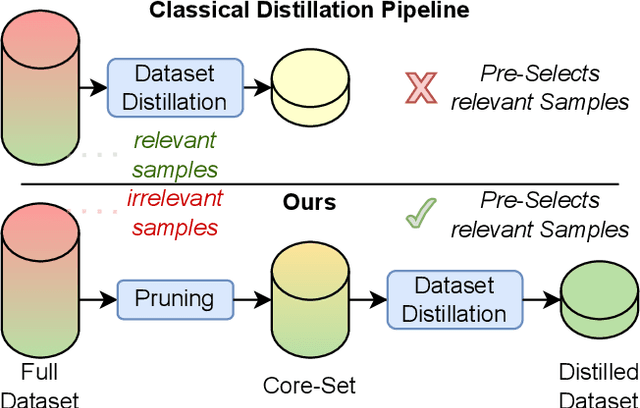

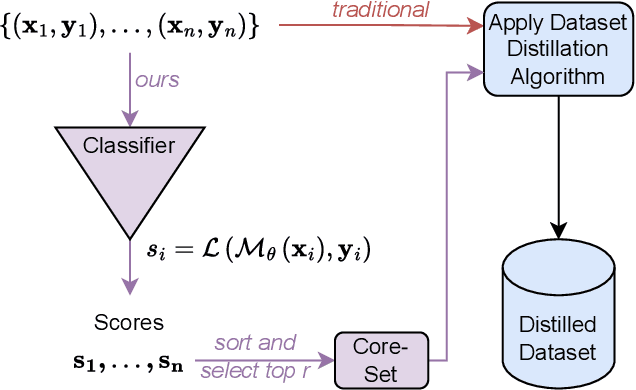
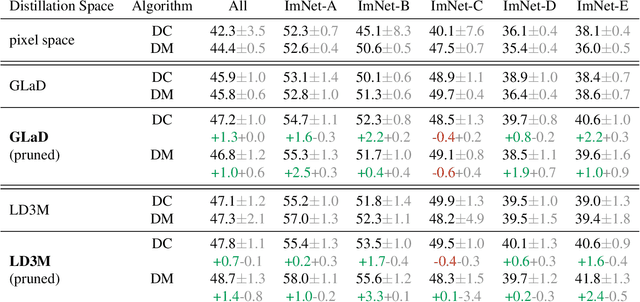
Dataset distillation has gained significant interest in recent years, yet existing approaches typically distill from the entire dataset, potentially including non-beneficial samples. We introduce a novel "Prune First, Distill After" framework that systematically prunes datasets via loss-based sampling prior to distillation. By leveraging pruning before classical distillation techniques and generative priors, we create a representative core-set that leads to enhanced generalization for unseen architectures - a significant challenge of current distillation methods. More specifically, our proposed framework significantly boosts distilled quality, achieving up to a 5.2 percentage points accuracy increase even with substantial dataset pruning, i.e., removing 80% of the original dataset prior to distillation. Overall, our experimental results highlight the advantages of our easy-sample prioritization and cross-architecture robustness, paving the way for more effective and high-quality dataset distillation.