 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePRISM: Diversifying Dataset Distillation by Decoupling Architectural Priors
Nov 13, 2025Dataset distillation (DD) promises compact yet faithful synthetic data, but existing approaches often inherit the inductive bias of a single teacher model. As dataset size increases, this bias drives generation toward overly smooth, homogeneous samples, reducing intra-class diversity and limiting generalization. We present PRISM (PRIors from diverse Source Models), a framework that disentangles architectural priors during synthesis. PRISM decouples the logit-matching and regularization objectives, supervising them with different teacher architectures: a primary model for logits and a stochastic subset for batch-normalization (BN) alignment. On ImageNet-1K, PRISM consistently and reproducibly outperforms single-teacher methods (e.g., SRe2L) and recent multi-teacher variants (e.g., G-VBSM) at low- and mid-IPC regimes. The generated data also show significantly richer intra-class diversity, as reflected by a notable drop in cosine similarity between features. We further analyze teacher selection strategies (pre- vs. intra-distillation) and introduce a scalable cross-class batch formation scheme for fast parallel synthesis. Code will be released after the review period.
A Coreset Selection of Coreset Selection Literature: Introduction and Recent Advances
May 23, 2025Coreset selection targets the challenge of finding a small, representative subset of a large dataset that preserves essential patterns for effective machine learning. Although several surveys have examined data reduction strategies before, most focus narrowly on either classical geometry-based methods or active learning techniques. In contrast, this survey presents a more comprehensive view by unifying three major lines of coreset research, namely, training-free, training-oriented, and label-free approaches, into a single taxonomy. We present subfields often overlooked by existing work, including submodular formulations, bilevel optimization, and recent progress in pseudo-labeling for unlabeled datasets. Additionally, we examine how pruning strategies influence generalization and neural scaling laws, offering new insights that are absent from prior reviews. Finally, we compare these methods under varying computational, robustness, and performance demands and highlight open challenges, such as robustness, outlier filtering, and adapting coreset selection to foundation models, for future research.
A Study in Dataset Distillation for Image Super-Resolution
Feb 05, 2025



Dataset distillation is the concept of condensing large datasets into smaller but highly representative synthetic samples. While previous research has primarily focused on image classification, its application to image Super-Resolution (SR) remains underexplored. This exploratory work studies multiple dataset distillation techniques applied to SR, including pixel- and latent-space approaches under different aspects. Our experiments demonstrate that a 91.12% dataset size reduction can be achieved while maintaining comparable SR performance to the full dataset. We further analyze initialization strategies and distillation methods to optimize memory efficiency and computational costs. Our findings provide new insights into dataset distillation for SR and set the stage for future advancements.
Multi-Label Scene Classification in Remote Sensing Benefits from Image Super-Resolution
Jan 12, 2025



Satellite imagery is a cornerstone for numerous Remote Sensing (RS) applications; however, limited spatial resolution frequently hinders the precision of such systems, especially in multi-label scene classification tasks as it requires a higher level of detail and feature differentiation. In this study, we explore the efficacy of image Super-Resolution (SR) as a pre-processing step to enhance the quality of satellite images and thus improve downstream classification performance. We investigate four SR models - SRResNet, HAT, SeeSR, and RealESRGAN - and evaluate their impact on multi-label scene classification across various CNN architectures, including ResNet-50, ResNet-101, ResNet-152, and Inception-v4. Our results show that applying SR significantly improves downstream classification performance across various metrics, demonstrating its ability to preserve spatial details critical for multi-label tasks. Overall, this work offers valuable insights into the selection of SR techniques for multi-label prediction in remote sensing and presents an easy-to-integrate framework to improve existing RS systems.
Distill the Best, Ignore the Rest: Improving Dataset Distillation with Loss-Value-Based Pruning
Nov 18, 2024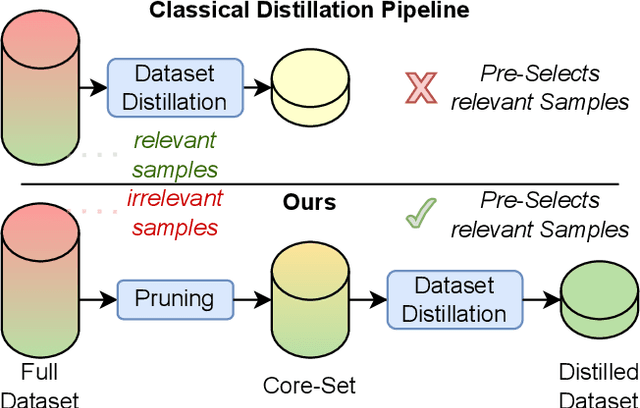

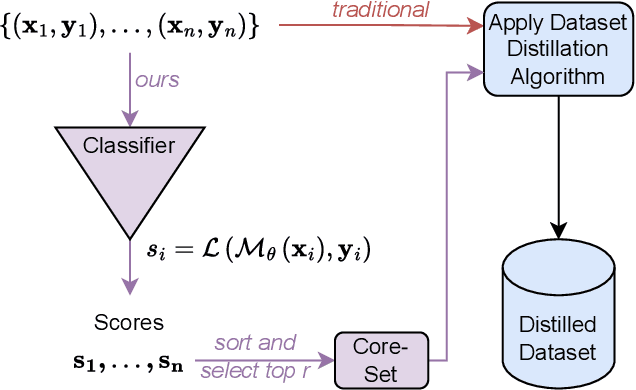
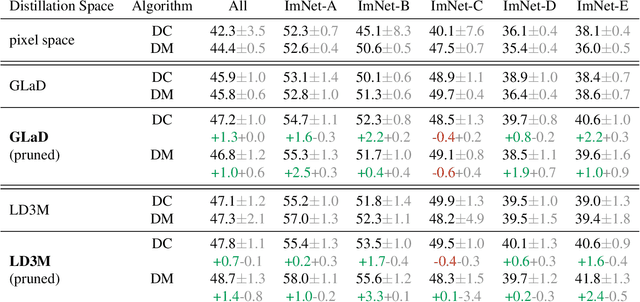
Dataset distillation has gained significant interest in recent years, yet existing approaches typically distill from the entire dataset, potentially including non-beneficial samples. We introduce a novel "Prune First, Distill After" framework that systematically prunes datasets via loss-based sampling prior to distillation. By leveraging pruning before classical distillation techniques and generative priors, we create a representative core-set that leads to enhanced generalization for unseen architectures - a significant challenge of current distillation methods. More specifically, our proposed framework significantly boosts distilled quality, achieving up to a 5.2 percentage points accuracy increase even with substantial dataset pruning, i.e., removing 80% of the original dataset prior to distillation. Overall, our experimental results highlight the advantages of our easy-sample prioritization and cross-architecture robustness, paving the way for more effective and high-quality dataset distillation.
Zoomed In, Diffused Out: Towards Local Degradation-Aware Multi-Diffusion for Extreme Image Super-Resolution
Nov 18, 2024



Large-scale, pre-trained Text-to-Image (T2I) diffusion models have gained significant popularity in image generation tasks and have shown unexpected potential in image Super-Resolution (SR). However, most existing T2I diffusion models are trained with a resolution limit of 512x512, making scaling beyond this resolution an unresolved but necessary challenge for image SR. In this work, we introduce a novel approach that, for the first time, enables these models to generate 2K, 4K, and even 8K images without any additional training. Our method leverages MultiDiffusion, which distributes the generation across multiple diffusion paths to ensure global coherence at larger scales, and local degradation-aware prompt extraction, which guides the T2I model to reconstruct fine local structures according to its low-resolution input. These innovations unlock higher resolutions, allowing T2I diffusion models to be applied to image SR tasks without limitation on resolution.
Just Leaf It: Accelerating Diffusion Classifiers with Hierarchical Class Pruning
Nov 18, 2024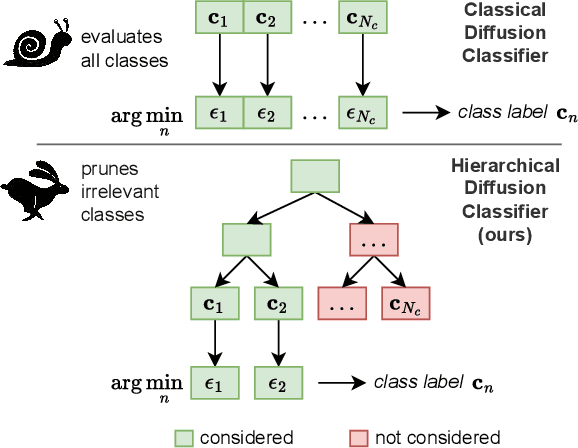

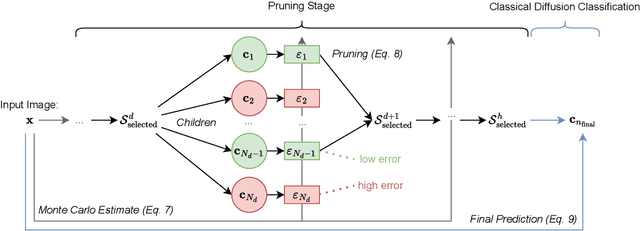

Diffusion models, known for their generative capabilities, have recently shown unexpected potential in image classification tasks by using Bayes' theorem. However, most diffusion classifiers require evaluating all class labels for a single classification, leading to significant computational costs that can hinder their application in large-scale scenarios. To address this, we present a Hierarchical Diffusion Classifier (HDC) that exploits the inherent hierarchical label structure of a dataset. By progressively pruning irrelevant high-level categories and refining predictions only within relevant subcategories, i.e., leaf nodes, HDC reduces the total number of class evaluations. As a result, HDC can accelerate inference by up to 60% while maintaining and, in some cases, improving classification accuracy. Our work enables a new control mechanism of the trade-off between speed and precision, making diffusion-based classification more viable for real-world applications, particularly in large-scale image classification tasks.
Webcam-based Pupil Diameter Prediction Benefits from Upscaling
Aug 19, 2024
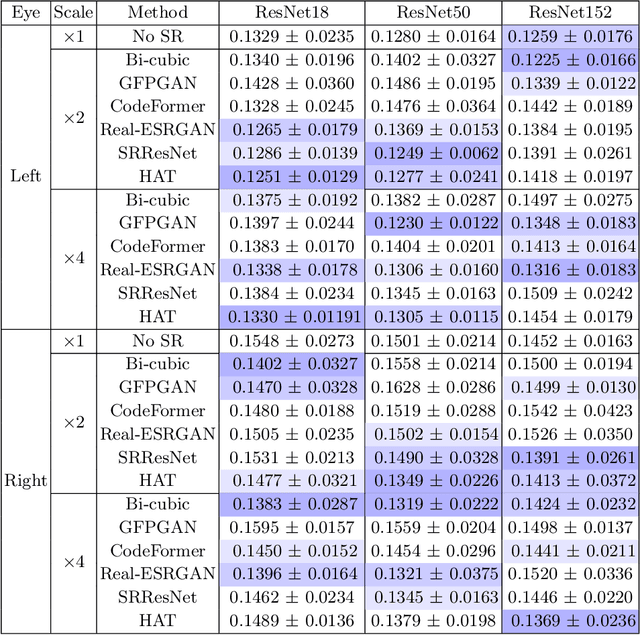


Capturing pupil diameter is essential for assessing psychological and physiological states such as stress levels and cognitive load. However, the low resolution of images in eye datasets often hampers precise measurement. This study evaluates the impact of various upscaling methods, ranging from bicubic interpolation to advanced super-resolution, on pupil diameter predictions. We compare several pre-trained methods, including CodeFormer, GFPGAN, Real-ESRGAN, HAT, and SRResNet. Our findings suggest that pupil diameter prediction models trained on upscaled datasets are highly sensitive to the selected upscaling method and scale. Our results demonstrate that upscaling methods consistently enhance the accuracy of pupil diameter prediction models, highlighting the importance of upscaling in pupilometry. Overall, our work provides valuable insights for selecting upscaling techniques, paving the way for more accurate assessments in psychological and physiological research.
SpotDiffusion: A Fast Approach For Seamless Panorama Generation Over Time
Jul 22, 2024



Generating high-resolution images with generative models has recently been made widely accessible by leveraging diffusion models pre-trained on large-scale datasets. Various techniques, such as MultiDiffusion and SyncDiffusion, have further pushed image generation beyond training resolutions, i.e., from square images to panorama, by merging multiple overlapping diffusion paths or employing gradient descent to maintain perceptual coherence. However, these methods suffer from significant computational inefficiencies due to generating and averaging numerous predictions, which is required in practice to produce high-quality and seamless images. This work addresses this limitation and presents a novel approach that eliminates the need to generate and average numerous overlapping denoising predictions. Our method shifts non-overlapping denoising windows over time, ensuring that seams in one timestep are corrected in the next. This results in coherent, high-resolution images with fewer overall steps. We demonstrate the effectiveness of our approach through qualitative and quantitative evaluations, comparing it with MultiDiffusion, SyncDiffusion, and StitchDiffusion. Our method offers several key benefits, including improved computational efficiency and faster inference times while producing comparable or better image quality.
EyeDentify: A Dataset for Pupil Diameter Estimation based on Webcam Images
Jul 15, 2024



In this work, we introduce EyeDentify, a dataset specifically designed for pupil diameter estimation based on webcam images. EyeDentify addresses the lack of available datasets for pupil diameter estimation, a crucial domain for understanding physiological and psychological states traditionally dominated by highly specialized sensor systems such as Tobii. Unlike these advanced sensor systems and associated costs, webcam images are more commonly found in practice. Yet, deep learning models that can estimate pupil diameters using standard webcam data are scarce. By providing a dataset of cropped eye images alongside corresponding pupil diameter information, EyeDentify enables the development and refinement of models designed specifically for less-equipped environments, democratizing pupil diameter estimation by making it more accessible and broadly applicable, which in turn contributes to multiple domains of understanding human activity and supporting healthcare. Our dataset is available at https://vijulshah.github.io/eyedentify/.