 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFedAD-Bench: A Unified Benchmark for Federated Unsupervised Anomaly Detection in Tabular Data
Aug 08, 2024The emergence of federated learning (FL) presents a promising approach to leverage decentralized data while preserving privacy. Furthermore, the combination of FL and anomaly detection is particularly compelling because it allows for detecting rare and critical anomalies (usually also rare in locally gathered data) in sensitive data from multiple sources, such as cybersecurity and healthcare. However, benchmarking the performance of anomaly detection methods in FL environments remains an underexplored area. This paper introduces FedAD-Bench, a unified benchmark for evaluating unsupervised anomaly detection algorithms within the context of FL. We systematically analyze and compare the performance of recent deep learning anomaly detection models under federated settings, which were typically assessed solely in centralized settings. FedAD-Bench encompasses diverse datasets and metrics to provide a holistic evaluation. Through extensive experiments, we identify key challenges such as model aggregation inefficiencies and metric unreliability. We present insights into FL's regularization effects, revealing scenarios in which it outperforms centralized approaches due to its inherent ability to mitigate overfitting. Our work aims to establish a standardized benchmark to guide future research and development in federated anomaly detection, promoting reproducibility and fair comparison across studies.
Federated Learning for Blind Image Super-Resolution
Apr 26, 2024
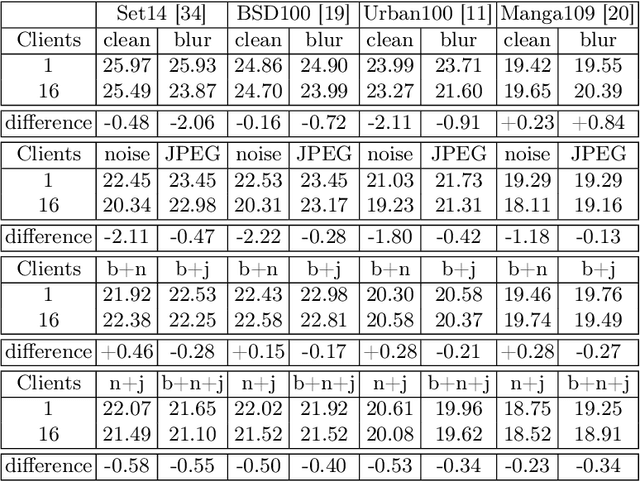
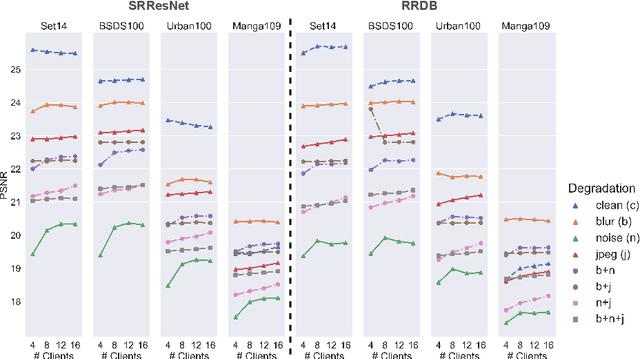
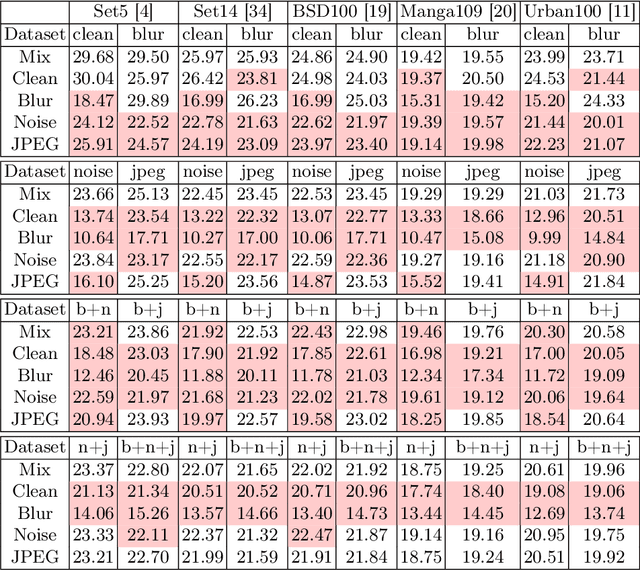
Traditional blind image SR methods need to model real-world degradations precisely. Consequently, current research struggles with this dilemma by assuming idealized degradations, which leads to limited applicability to actual user data. Moreover, the ideal scenario - training models on data from the targeted user base - presents significant privacy concerns. To address both challenges, we propose to fuse image SR with federated learning, allowing real-world degradations to be directly learned from users without invading their privacy. Furthermore, it enables optimization across many devices without data centralization. As this fusion is underexplored, we introduce new benchmarks specifically designed to evaluate new SR methods in this federated setting. By doing so, we employ known degradation modeling techniques from SR research. However, rather than aiming to mirror real degradations, our benchmarks use these degradation models to simulate the variety of degradations found across clients within a distributed user base. This distinction is crucial as it circumvents the need to precisely model real-world degradations, which limits contemporary blind image SR research. Our proposed benchmarks investigate blind image SR under new aspects, namely differently distributed degradation types among users and varying user numbers. We believe new methods tested within these benchmarks will perform more similarly in an application, as the simulated scenario addresses the variety while federated learning enables the training on actual degradations.
Fin-Fed-OD: Federated Outlier Detection on Financial Tabular Data
Apr 23, 2024



Anomaly detection in real-world scenarios poses challenges due to dynamic and often unknown anomaly distributions, requiring robust methods that operate under an open-world assumption. This challenge is exacerbated in practical settings, where models are employed by private organizations, precluding data sharing due to privacy and competitive concerns. Despite potential benefits, the sharing of anomaly information across organizations is restricted. This paper addresses the question of enhancing outlier detection within individual organizations without compromising data confidentiality. We propose a novel method leveraging representation learning and federated learning techniques to improve the detection of unknown anomalies. Specifically, our approach utilizes latent representations obtained from client-owned autoencoders to refine the decision boundary of inliers. Notably, only model parameters are shared between organizations, preserving data privacy. The efficacy of our proposed method is evaluated on two standard financial tabular datasets and an image dataset for anomaly detection in a distributed setting. The results demonstrate a strong improvement in the classification of unknown outliers during the inference phase for each organization's model.