 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFin-Fed-OD: Federated Outlier Detection on Financial Tabular Data
Apr 23, 2024



Anomaly detection in real-world scenarios poses challenges due to dynamic and often unknown anomaly distributions, requiring robust methods that operate under an open-world assumption. This challenge is exacerbated in practical settings, where models are employed by private organizations, precluding data sharing due to privacy and competitive concerns. Despite potential benefits, the sharing of anomaly information across organizations is restricted. This paper addresses the question of enhancing outlier detection within individual organizations without compromising data confidentiality. We propose a novel method leveraging representation learning and federated learning techniques to improve the detection of unknown anomalies. Specifically, our approach utilizes latent representations obtained from client-owned autoencoders to refine the decision boundary of inliers. Notably, only model parameters are shared between organizations, preserving data privacy. The efficacy of our proposed method is evaluated on two standard financial tabular datasets and an image dataset for anomaly detection in a distributed setting. The results demonstrate a strong improvement in the classification of unknown outliers during the inference phase for each organization's model.
ObjBlur: A Curriculum Learning Approach With Progressive Object-Level Blurring for Improved Layout-to-Image Generation
Apr 11, 2024



We present ObjBlur, a novel curriculum learning approach to improve layout-to-image generation models, where the task is to produce realistic images from layouts composed of boxes and labels. Our method is based on progressive object-level blurring, which effectively stabilizes training and enhances the quality of generated images. This curriculum learning strategy systematically applies varying degrees of blurring to individual objects or the background during training, starting from strong blurring to progressively cleaner images. Our findings reveal that this approach yields significant performance improvements, stabilized training, smoother convergence, and reduced variance between multiple runs. Moreover, our technique demonstrates its versatility by being compatible with generative adversarial networks and diffusion models, underlining its applicability across various generative modeling paradigms. With ObjBlur, we reach new state-of-the-art results on the complex COCO and Visual Genome datasets.
Latent Dataset Distillation with Diffusion Models
Mar 06, 2024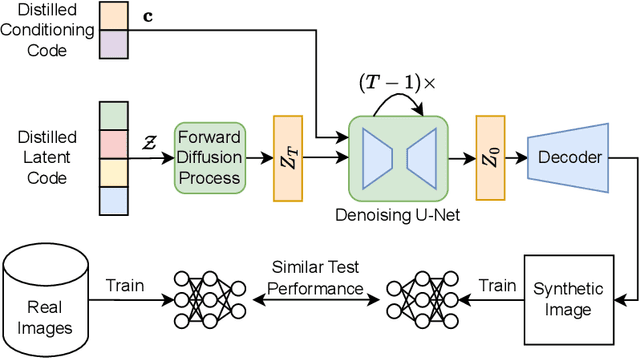



The efficacy of machine learning has traditionally relied on the availability of increasingly larger datasets. However, large datasets pose storage challenges and contain non-influential samples, which could be ignored during training without impacting the final accuracy of the model. In response to these limitations, the concept of distilling the information on a dataset into a condensed set of (synthetic) samples, namely a distilled dataset, emerged. One crucial aspect is the selected architecture (usually ConvNet) for linking the original and synthetic datasets. However, the final accuracy is lower if the employed model architecture differs from the model used during distillation. Another challenge is the generation of high-resolution images, e.g., 128x128 and higher. In this paper, we propose Latent Dataset Distillation with Diffusion Models (LD3M) that combine diffusion in latent space with dataset distillation to tackle both challenges. LD3M incorporates a novel diffusion process tailored for dataset distillation, which improves the gradient norms for learning synthetic images. By adjusting the number of diffusion steps, LD3M also offers a straightforward way of controlling the trade-off between speed and accuracy. We evaluate our approach in several ImageNet subsets and for high-resolution images (128x128 and 256x256). As a result, LD3M consistently outperforms state-of-the-art distillation techniques by up to 4.8 p.p. and 4.2 p.p. for 1 and 10 images per class, respectively.
TaylorShift: Shifting the Complexity of Self-Attention from Squared to Linear (and Back) using Taylor-Softmax
Mar 05, 2024The quadratic complexity of the attention mechanism represents one of the biggest hurdles for processing long sequences using Transformers. Current methods, relying on sparse representations or stateful recurrence, sacrifice token-to-token interactions, which ultimately leads to compromises in performance. This paper introduces TaylorShift, a novel reformulation of the Taylor softmax that enables computing full token-to-token interactions in linear time and space. We analytically determine the crossover points where employing TaylorShift becomes more efficient than traditional attention, aligning closely with empirical measurements. Specifically, our findings demonstrate that TaylorShift enhances memory efficiency for sequences as short as 800 tokens and accelerates inference for inputs of approximately 1700 tokens and beyond. For shorter sequences, TaylorShift scales comparably with the vanilla attention. Furthermore, a classification benchmark across five tasks involving long sequences reveals no degradation in accuracy when employing Transformers equipped with TaylorShift. For reproducibility, we provide access to our code under https://github.com/tobna/TaylorShift.
Diffusion Models, Image Super-Resolution And Everything: A Survey
Jan 01, 2024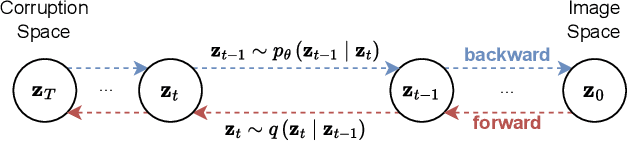


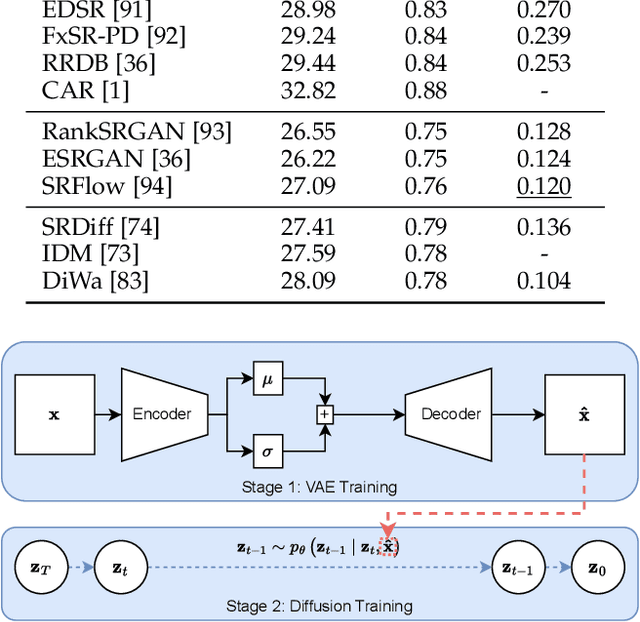
Diffusion Models (DMs) represent a significant advancement in image Super-Resolution (SR), aligning technical image quality more closely with human preferences and expanding SR applications. DMs address critical limitations of previous methods, enhancing overall realism and details in SR images. However, DMs suffer from color-shifting issues, and their high computational costs call for efficient sampling alternatives, underscoring the challenge of balancing computational efficiency and image quality. This survey gives an overview of DMs applied to image SR and offers a detailed analysis that underscores the unique characteristics and methodologies within this domain, distinct from broader existing reviews in the field. It presents a unified view of DM fundamentals and explores research directions, including alternative input domains, conditioning strategies, guidance, corruption spaces, and zero-shot methods. This survey provides insights into the evolution of image SR with DMs, addressing current trends, challenges, and future directions in this rapidly evolving field.
Which Transformer to Favor: A Comparative Analysis of Efficiency in Vision Transformers
Aug 18, 2023



The growing popularity of Vision Transformers as the go-to models for image classification has led to an explosion of architectural modifications claiming to be more efficient than the original ViT. However, a wide diversity of experimental conditions prevents a fair comparison between all of them, based solely on their reported results. To address this gap in comparability, we conduct a comprehensive analysis of more than 30 models to evaluate the efficiency of vision transformers and related architectures, considering various performance metrics. Our benchmark provides a comparable baseline across the landscape of efficiency-oriented transformers, unveiling a plethora of surprising insights. For example, we discover that ViT is still Pareto optimal across multiple efficiency metrics, despite the existence of several alternative approaches claiming to be more efficient. Results also indicate that hybrid attention-CNN models fare particularly well when it comes to low inference memory and number of parameters, and also that it is better to scale the model size, than the image size. Furthermore, we uncover a strong positive correlation between the number of FLOPS and the training memory, which enables the estimation of required VRAM from theoretical measurements alone. Thanks to our holistic evaluation, this study offers valuable insights for practitioners and researchers, facilitating informed decisions when selecting models for specific applications. We publicly release our code and data at https://github.com/tobna/WhatTransformerToFavor
YODA: You Only Diffuse Areas. An Area-Masked Diffusion Approach For Image Super-Resolution
Aug 15, 2023
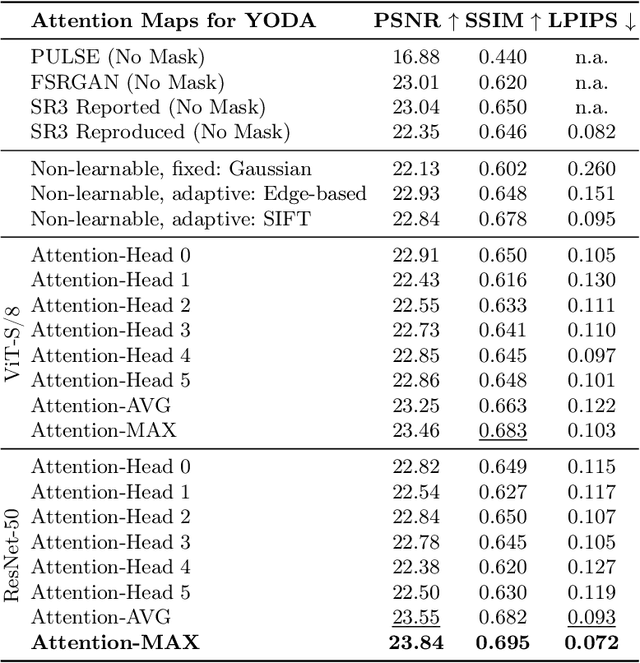
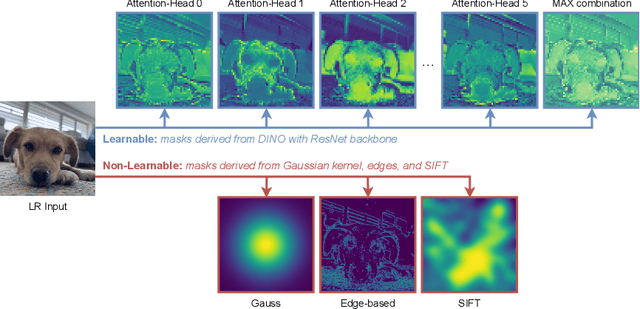

This work introduces "You Only Diffuse Areas" (YODA), a novel method for partial diffusion in Single-Image Super-Resolution (SISR). The core idea is to utilize diffusion selectively on spatial regions based on attention maps derived from the low-resolution image and the current time step in the diffusion process. This time-dependent targeting enables a more effective conversion to high-resolution outputs by focusing on areas that benefit the most from the iterative refinement process, i.e., detail-rich objects. We empirically validate YODA by extending leading diffusion-based SISR methods SR3 and SRDiff. Our experiments demonstrate new state-of-the-art performance gains in face and general SR across PSNR, SSIM, and LPIPS metrics. A notable finding is YODA's stabilization effect on training by reducing color shifts, especially when induced by small batch sizes, potentially contributing to resource-constrained scenarios. The proposed spatial and temporal adaptive diffusion mechanism opens promising research directions, including developing enhanced attention map extraction techniques and optimizing inference latency based on sparser diffusion.
DWA: Differential Wavelet Amplifier for Image Super-Resolution
Jul 10, 2023This work introduces Differential Wavelet Amplifier (DWA), a drop-in module for wavelet-based image Super-Resolution (SR). DWA invigorates an approach recently receiving less attention, namely Discrete Wavelet Transformation (DWT). DWT enables an efficient image representation for SR and reduces the spatial area of its input by a factor of 4, the overall model size, and computation cost, framing it as an attractive approach for sustainable ML. Our proposed DWA model improves wavelet-based SR models by leveraging the difference between two convolutional filters to refine relevant feature extraction in the wavelet domain, emphasizing local contrasts and suppressing common noise in the input signals. We show its effectiveness by integrating it into existing SR models, e.g., DWSR and MWCNN, and demonstrate a clear improvement in classical SR tasks. Moreover, DWA enables a direct application of DWSR and MWCNN to input image space, reducing the DWT representation channel-wise since it omits traditional DWT.
Waving Goodbye to Low-Res: A Diffusion-Wavelet Approach for Image Super-Resolution
Apr 05, 2023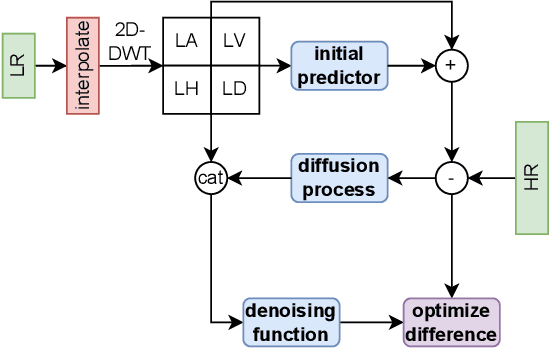
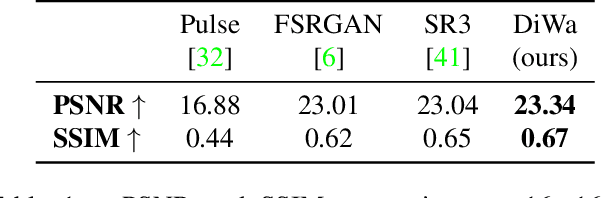
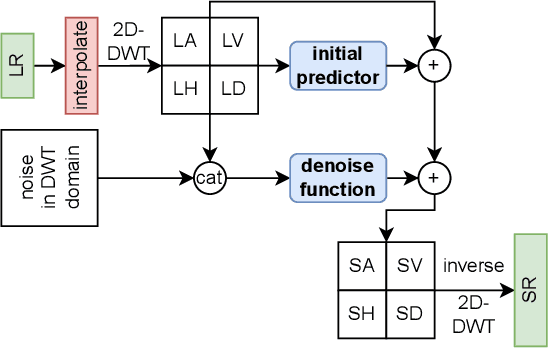
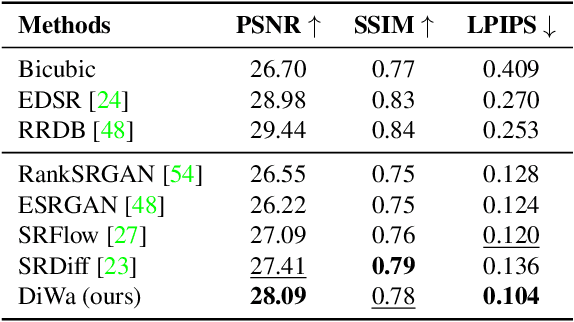
This paper presents a novel Diffusion-Wavelet (DiWa) approach for Single-Image Super-Resolution (SISR). It leverages the strengths of Denoising Diffusion Probabilistic Models (DDPMs) and Discrete Wavelet Transformation (DWT). By enabling DDPMs to operate in the DWT domain, our DDPM models effectively hallucinate high-frequency information for super-resolved images on the wavelet spectrum, resulting in high-quality and detailed reconstructions in image space. Quantitatively, we outperform state-of-the-art diffusion-based SISR methods, namely SR3 and SRDiff, regarding PSNR, SSIM, and LPIPS on both face (8x scaling) and general (4x scaling) SR benchmarks. Meanwhile, using DWT enabled us to use fewer parameters than the compared models: 92M parameters instead of 550M compared to SR3 and 9.3M instead of 12M compared to SRDiff. Additionally, our method outperforms other state-of-the-art generative methods on classical general SR datasets while saving inference time. Finally, our work highlights its potential for various applications.
Hitchhiker's Guide to Super-Resolution: Introduction and Recent Advances
Sep 27, 2022
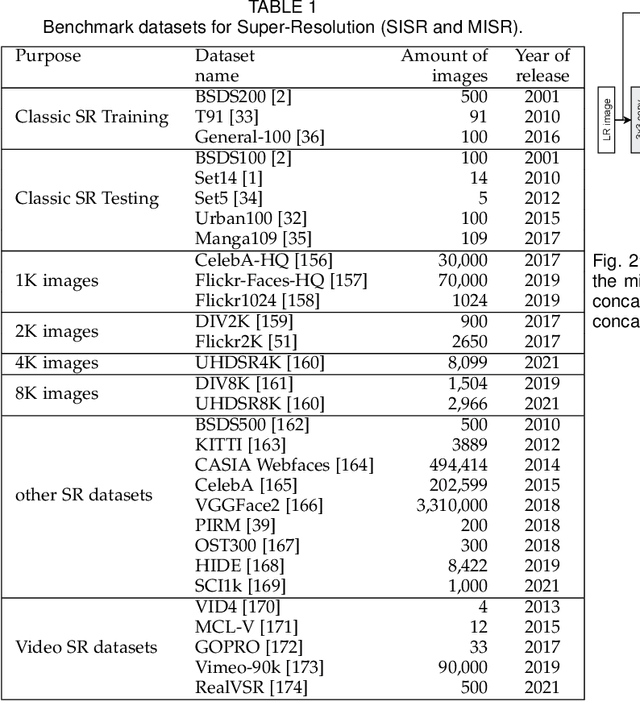
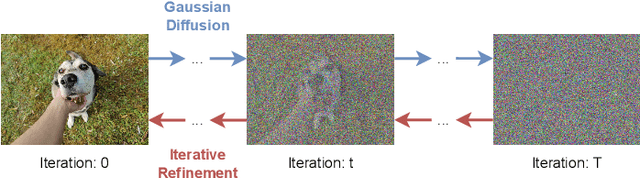
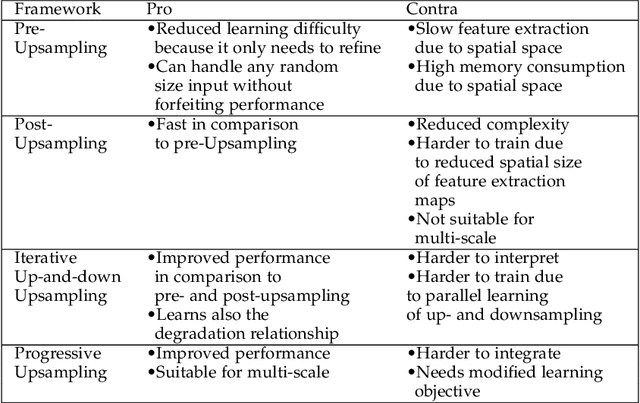
With the advent of Deep Learning (DL), Super-Resolution (SR) has also become a thriving research area. However, despite promising results, the field still faces challenges that require further research e.g., allowing flexible upsampling, more effective loss functions, and better evaluation metrics. We review the domain of SR in light of recent advances, and examine state-of-the-art models such as diffusion (DDPM) and transformer-based SR models. We present a critical discussion on contemporary strategies used in SR, and identify promising yet unexplored research directions. We complement previous surveys by incorporating the latest developments in the field such as uncertainty-driven losses, wavelet networks, neural architecture search, novel normalization methods, and the latests evaluation techniques. We also include several visualizations for the models and methods throughout each chapter in order to facilitate a global understanding of the trends in the field. This review is ultimately aimed at helping researchers to push the boundaries of DL applied to SR.