 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeForAug: Recombining Foregrounds and Backgrounds to Improve Vision Transformer Training with Bias Mitigation
Mar 12, 2025Transformers, particularly Vision Transformers (ViTs), have achieved state-of-the-art performance in large-scale image classification. However, they often require large amounts of data and can exhibit biases that limit their robustness and generalizability. This paper introduces ForAug, a novel data augmentation scheme that addresses these challenges and explicitly includes inductive biases, which commonly are part of the neural network architecture, into the training data. ForAug is constructed by using pretrained foundation models to separate and recombine foreground objects with different backgrounds, enabling fine-grained control over image composition during training. It thus increases the data diversity and effective number of training samples. We demonstrate that training on ForNet, the application of ForAug to ImageNet, significantly improves the accuracy of ViTs and other architectures by up to 4.5 percentage points (p.p.) on ImageNet and 7.3 p.p. on downstream tasks. Importantly, ForAug enables novel ways of analyzing model behavior and quantifying biases. Namely, we introduce metrics for background robustness, foreground focus, center bias, and size bias and show that training on ForNet substantially reduces these biases compared to training on ImageNet. In summary, ForAug provides a valuable tool for analyzing and mitigating biases, enabling the development of more robust and reliable computer vision models. Our code and dataset are publicly available at https://github.com/tobna/ForAug.
A Low-Resolution Image is Worth 1x1 Words: Enabling Fine Image Super-Resolution with Transformers and TaylorShift
Nov 15, 2024


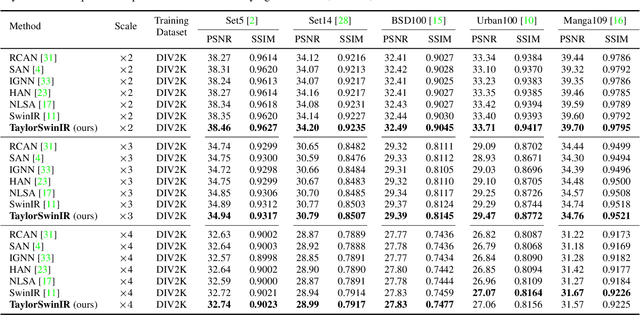
Transformer-based Super-Resolution (SR) models have recently advanced image reconstruction quality, yet challenges remain due to computational complexity and an over-reliance on large patch sizes, which constrain fine-grained detail enhancement. In this work, we propose TaylorIR to address these limitations by utilizing a patch size of 1x1, enabling pixel-level processing in any transformer-based SR model. To address the significant computational demands under the traditional self-attention mechanism, we employ the TaylorShift attention mechanism, a memory-efficient alternative based on Taylor series expansion, achieving full token-to-token interactions with linear complexity. Experimental results demonstrate that our approach achieves new state-of-the-art SR performance while reducing memory consumption by up to 60% compared to traditional self-attention-based transformers.
TaylorShift: Shifting the Complexity of Self-Attention from Squared to Linear (and Back) using Taylor-Softmax
Mar 05, 2024The quadratic complexity of the attention mechanism represents one of the biggest hurdles for processing long sequences using Transformers. Current methods, relying on sparse representations or stateful recurrence, sacrifice token-to-token interactions, which ultimately leads to compromises in performance. This paper introduces TaylorShift, a novel reformulation of the Taylor softmax that enables computing full token-to-token interactions in linear time and space. We analytically determine the crossover points where employing TaylorShift becomes more efficient than traditional attention, aligning closely with empirical measurements. Specifically, our findings demonstrate that TaylorShift enhances memory efficiency for sequences as short as 800 tokens and accelerates inference for inputs of approximately 1700 tokens and beyond. For shorter sequences, TaylorShift scales comparably with the vanilla attention. Furthermore, a classification benchmark across five tasks involving long sequences reveals no degradation in accuracy when employing Transformers equipped with TaylorShift. For reproducibility, we provide access to our code under https://github.com/tobna/TaylorShift.
Which Transformer to Favor: A Comparative Analysis of Efficiency in Vision Transformers
Aug 18, 2023



The growing popularity of Vision Transformers as the go-to models for image classification has led to an explosion of architectural modifications claiming to be more efficient than the original ViT. However, a wide diversity of experimental conditions prevents a fair comparison between all of them, based solely on their reported results. To address this gap in comparability, we conduct a comprehensive analysis of more than 30 models to evaluate the efficiency of vision transformers and related architectures, considering various performance metrics. Our benchmark provides a comparable baseline across the landscape of efficiency-oriented transformers, unveiling a plethora of surprising insights. For example, we discover that ViT is still Pareto optimal across multiple efficiency metrics, despite the existence of several alternative approaches claiming to be more efficient. Results also indicate that hybrid attention-CNN models fare particularly well when it comes to low inference memory and number of parameters, and also that it is better to scale the model size, than the image size. Furthermore, we uncover a strong positive correlation between the number of FLOPS and the training memory, which enables the estimation of required VRAM from theoretical measurements alone. Thanks to our holistic evaluation, this study offers valuable insights for practitioners and researchers, facilitating informed decisions when selecting models for specific applications. We publicly release our code and data at https://github.com/tobna/WhatTransformerToFavor