 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpherical Dense Text-to-Image Synthesis
Feb 19, 2025Recent advancements in text-to-image (T2I) have improved synthesis results, but challenges remain in layout control and generating omnidirectional panoramic images. Dense T2I (DT2I) and spherical T2I (ST2I) models address these issues, but so far no unified approach exists. Trivial approaches, like prompting a DT2I model to generate panoramas can not generate proper spherical distortions and seamless transitions at the borders. Our work shows that spherical dense text-to-image (SDT2I) can be achieved by integrating training-free DT2I approaches into finetuned panorama models. Specifically, we propose MultiStitchDiffusion (MSTD) and MultiPanFusion (MPF) by integrating MultiDiffusion into StitchDiffusion and PanFusion, respectively. Since no benchmark for SDT2I exists, we further construct Dense-Synthetic-View (DSynView), a new synthetic dataset containing spherical layouts to evaluate our models. Our results show that MSTD outperforms MPF across image quality as well as prompt- and layout adherence. MultiPanFusion generates more diverse images but struggles to synthesize flawless foreground objects. We propose bootstrap-coupling and turning off equirectangular perspective-projection attention in the foreground as an improvement of MPF.
TKG-DM: Training-free Chroma Key Content Generation Diffusion Model
Nov 23, 2024



Diffusion models have enabled the generation of high-quality images with a strong focus on realism and textual fidelity. Yet, large-scale text-to-image models, such as Stable Diffusion, struggle to generate images where foreground objects are placed over a chroma key background, limiting their ability to separate foreground and background elements without fine-tuning. To address this limitation, we present a novel Training-Free Chroma Key Content Generation Diffusion Model (TKG-DM), which optimizes the initial random noise to produce images with foreground objects on a specifiable color background. Our proposed method is the first to explore the manipulation of the color aspects in initial noise for controlled background generation, enabling precise separation of foreground and background without fine-tuning. Extensive experiments demonstrate that our training-free method outperforms existing methods in both qualitative and quantitative evaluations, matching or surpassing fine-tuned models. Finally, we successfully extend it to other tasks (e.g., consistency models and text-to-video), highlighting its transformative potential across various generative applications where independent control of foreground and background is crucial.
A Low-Resolution Image is Worth 1x1 Words: Enabling Fine Image Super-Resolution with Transformers and TaylorShift
Nov 15, 2024


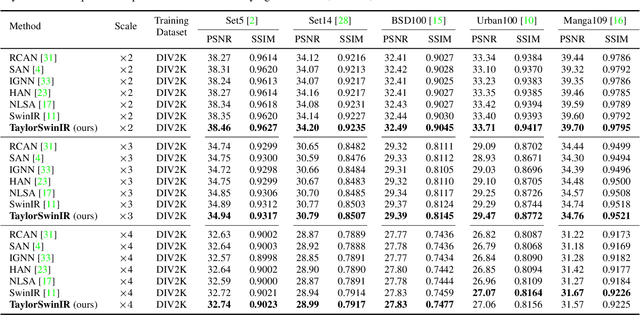
Transformer-based Super-Resolution (SR) models have recently advanced image reconstruction quality, yet challenges remain due to computational complexity and an over-reliance on large patch sizes, which constrain fine-grained detail enhancement. In this work, we propose TaylorIR to address these limitations by utilizing a patch size of 1x1, enabling pixel-level processing in any transformer-based SR model. To address the significant computational demands under the traditional self-attention mechanism, we employ the TaylorShift attention mechanism, a memory-efficient alternative based on Taylor series expansion, achieving full token-to-token interactions with linear complexity. Experimental results demonstrate that our approach achieves new state-of-the-art SR performance while reducing memory consumption by up to 60% compared to traditional self-attention-based transformers.