 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEyeBrain: Left and Right Brain Lateralization Activity Classification Through Pupil Diameter and Fixation Duration
Apr 26, 2026The relationship between brain lateralization and cognitive functions is well-documented. The left hemisphere primarily handles tasks such as language and arithmetic, while the right hemisphere is involved in creative activities like drawing and music perception. Eye-tracking technology has shown the potential to reveal cognitive states by measuring ocular metrics such as pupil diameter and fixation duration. However, the ability to distinguish lateralized brain activity using these ocular metrics remains underexplored. Here, we demonstrate that pupil diameter and fixation duration can effectively classify left and right brain hemisphere activities. We obtained a considerably high classification performance, with an F1 score of 0.894. The results suggest that ocular metrics are robust indicators of lateralized brain activity and can be applied in cognitive monitoring and neurorehabilitation. Our future work expands on this by integrating these methods into real-time applications EyeBrain, potentially broadening their use across various cognitive and neurological domains.
LGTM: Training-Free Light-Guided Text-to-Image Diffusion Model via Initial Noise Manipulation
Mar 25, 2026Diffusion models have demonstrated high-quality performance in conditional text-to-image generation, particularly with structural cues such as edges, layouts, and depth. However, lighting conditions have received limited attention and remain difficult to control within the generative process. Existing methods handle lighting through a two-stage pipeline that relights images after generation, which is inefficient. Moreover, they rely on fine-tuning with large datasets and heavy computation, limiting their adaptability to new models and tasks. To address this, we propose a novel Training-Free Light-Guided Text-to-Image Diffusion Model via Initial Noise Manipulation (LGTM), which manipulates the initial latent noise of the diffusion process to guide image generation with text prompts and user-specified light directions. Through a channel-wise analysis of the latent space, we find that selectively manipulating latent channels enables fine-grained lighting control without fine-tuning or modifying the pre-trained model. Extensive experiments show that our method surpasses prompt-based baselines in lighting consistency, while preserving image quality and text alignment. This approach introduces new possibilities for dynamic, user-guided light control. Furthermore, it integrates seamlessly with models like ControlNet, demonstrating adaptability across diverse scenarios.
SensHRPS: Sensing Comfortable Human-Robot Proxemics and Personal Space With Eye-Tracking
Dec 10, 2025Social robots must adjust to human proxemic norms to ensure user comfort and engagement. While prior research demonstrates that eye-tracking features reliably estimate comfort in human-human interactions, their applicability to interactions with humanoid robots remains unexplored. In this study, we investigate user comfort with the robot "Ameca" across four experimentally controlled distances (0.5 m to 2.0 m) using mobile eye-tracking and subjective reporting (N=19). We evaluate multiple machine learning and deep learning models to estimate comfort based on gaze features. Contrary to previous human-human studies where Transformer models excelled, a Decision Tree classifier achieved the highest performance (F1-score = 0.73), with minimum pupil diameter identified as the most critical predictor. These findings suggest that physiological comfort thresholds in human-robot interaction differ from human-human dynamics and can be effectively modeled using interpretable logic.
Unifying VXAI: A Systematic Review and Framework for the Evaluation of Explainable AI
Jun 18, 2025Modern AI systems frequently rely on opaque black-box models, most notably Deep Neural Networks, whose performance stems from complex architectures with millions of learned parameters. While powerful, their complexity poses a major challenge to trustworthiness, particularly due to a lack of transparency. Explainable AI (XAI) addresses this issue by providing human-understandable explanations of model behavior. However, to ensure their usefulness and trustworthiness, such explanations must be rigorously evaluated. Despite the growing number of XAI methods, the field lacks standardized evaluation protocols and consensus on appropriate metrics. To address this gap, we conduct a systematic literature review following the Preferred Reporting Items for Systematic Reviews and Meta-Analyses (PRISMA) guidelines and introduce a unified framework for the eValuation of XAI (VXAI). We identify 362 relevant publications and aggregate their contributions into 41 functionally similar metric groups. In addition, we propose a three-dimensional categorization scheme spanning explanation type, evaluation contextuality, and explanation quality desiderata. Our framework provides the most comprehensive and structured overview of VXAI to date. It supports systematic metric selection, promotes comparability across methods, and offers a flexible foundation for future extensions.
Human-in-the-Loop Annotation for Image-Based Engagement Estimation: Assessing the Impact of Model Reliability on Annotation Accuracy
Feb 11, 2025Human-in-the-loop (HITL) frameworks are increasingly recognized for their potential to improve annotation accuracy in emotion estimation systems by combining machine predictions with human expertise. This study focuses on integrating a high-performing image-based emotion model into a HITL annotation framework to evaluate the collaborative potential of human-machine interaction and identify the psychological and practical factors critical to successful collaboration. Specifically, we investigate how varying model reliability and cognitive framing influence human trust, cognitive load, and annotation behavior in HITL systems. We demonstrate that model reliability and psychological framing significantly impact annotators' trust, engagement, and consistency, offering insights into optimizing HITL frameworks. Through three experimental scenarios with 29 participants--baseline model reliability (S1), fabricated errors (S2), and cognitive bias introduced by negative framing (S3)--we analyzed behavioral and qualitative data. Reliable predictions in S1 yielded high trust and annotation consistency, while unreliable outputs in S2 led to increased critical evaluations but also heightened frustration and response variability. Negative framing in S3 revealed how cognitive bias influenced participants to perceive the model as more relatable and accurate, despite misinformation regarding its reliability. These findings highlight the importance of both reliable machine outputs and psychological factors in shaping effective human-machine collaboration. By leveraging the strengths of both human oversight and automated systems, this study establishes a scalable HITL framework for emotion annotation and lays the foundation for broader applications in adaptive learning and human-computer interaction.
SensPS: Sensing Personal Space Comfortable Distance between Human-Human Using Multimodal Sensors
Feb 11, 2025Personal space, also known as peripersonal space, is crucial in human social interaction, influencing comfort, communication, and social stress. Estimating and respecting personal space is essential for enhancing human-computer interaction (HCI) and smart environments. Personal space preferences vary due to individual traits, cultural background, and contextual factors. Advanced multimodal sensing technologies, including eye-tracking and wristband sensors, offer opportunities to develop adaptive systems that dynamically adjust to user comfort levels. Integrating physiological and behavioral data enables a deeper understanding of spatial interactions. This study develops a sensor-based model to estimate comfortable personal space and identifies key features influencing spatial preferences. Our findings show that multimodal sensors, particularly eye-tracking and physiological wristband data, can effectively predict personal space preferences, with eye-tracking data playing a more significant role. An experimental study involving controlled human interactions demonstrates that a Transformer-based model achieves the highest predictive accuracy (F1 score: 0.87) for estimating personal space. Eye-tracking features, such as gaze point and pupil diameter, emerge as the most significant predictors, while physiological signals from wristband sensors contribute marginally. These results highlight the potential for AI-driven personalization of social space in adaptive environments, suggesting that multimodal sensing can be leveraged to develop intelligent systems that optimize spatial arrangements in workplaces, educational institutions, and public settings. Future work should explore larger datasets, real-world applications, and additional physiological markers to enhance model robustness.
TKG-DM: Training-free Chroma Key Content Generation Diffusion Model
Nov 23, 2024



Diffusion models have enabled the generation of high-quality images with a strong focus on realism and textual fidelity. Yet, large-scale text-to-image models, such as Stable Diffusion, struggle to generate images where foreground objects are placed over a chroma key background, limiting their ability to separate foreground and background elements without fine-tuning. To address this limitation, we present a novel Training-Free Chroma Key Content Generation Diffusion Model (TKG-DM), which optimizes the initial random noise to produce images with foreground objects on a specifiable color background. Our proposed method is the first to explore the manipulation of the color aspects in initial noise for controlled background generation, enabling precise separation of foreground and background without fine-tuning. Extensive experiments demonstrate that our training-free method outperforms existing methods in both qualitative and quantitative evaluations, matching or surpassing fine-tuned models. Finally, we successfully extend it to other tasks (e.g., consistency models and text-to-video), highlighting its transformative potential across various generative applications where independent control of foreground and background is crucial.
Feature Estimation of Global Language Processing in EEG Using Attention Maps
Sep 27, 2024



Understanding the correlation between EEG features and cognitive tasks is crucial for elucidating brain function. Brain activity synchronizes during speaking and listening tasks. However, it is challenging to estimate task-dependent brain activity characteristics with methods with low spatial resolution but high temporal resolution, such as EEG, rather than methods with high spatial resolution, like fMRI. This study introduces a novel approach to EEG feature estimation that utilizes the weights of deep learning models to explore this association. We demonstrate that attention maps generated from Vision Transformers and EEGNet effectively identify features that align with findings from prior studies. EEGNet emerged as the most accurate model regarding subject independence and the classification of Listening and Speaking tasks. The application of Mel-Spectrogram with ViTs enhances the resolution of temporal and frequency-related EEG characteristics. Our findings reveal that the characteristics discerned through attention maps vary significantly based on the input data, allowing for tailored feature extraction from EEG signals. By estimating features, our study reinforces known attributes and predicts new ones, potentially offering fresh perspectives in utilizing EEG for medical purposes, such as early disease detection. These techniques will make substantial contributions to cognitive neuroscience.
Edge-based Denoising Image Compression
Sep 17, 2024



In recent years, deep learning-based image compression, particularly through generative models, has emerged as a pivotal area of research. Despite significant advancements, challenges such as diminished sharpness and quality in reconstructed images, learning inefficiencies due to mode collapse, and data loss during transmission persist. To address these issues, we propose a novel compression model that incorporates a denoising step with diffusion models, significantly enhancing image reconstruction fidelity by sub-information(e.g., edge and depth) from leveraging latent space. Empirical experiments demonstrate that our model achieves superior or comparable results in terms of image quality and compression efficiency when measured against the existing models. Notably, our model excels in scenarios of partial image loss or excessive noise by introducing an edge estimation network to preserve the integrity of reconstructed images, offering a robust solution to the current limitations of image compression.
Webcam-based Pupil Diameter Prediction Benefits from Upscaling
Aug 19, 2024
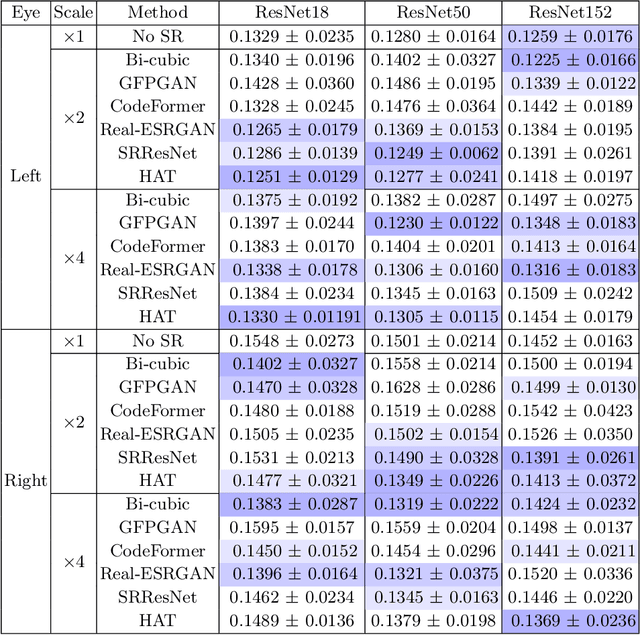


Capturing pupil diameter is essential for assessing psychological and physiological states such as stress levels and cognitive load. However, the low resolution of images in eye datasets often hampers precise measurement. This study evaluates the impact of various upscaling methods, ranging from bicubic interpolation to advanced super-resolution, on pupil diameter predictions. We compare several pre-trained methods, including CodeFormer, GFPGAN, Real-ESRGAN, HAT, and SRResNet. Our findings suggest that pupil diameter prediction models trained on upscaled datasets are highly sensitive to the selected upscaling method and scale. Our results demonstrate that upscaling methods consistently enhance the accuracy of pupil diameter prediction models, highlighting the importance of upscaling in pupilometry. Overall, our work provides valuable insights for selecting upscaling techniques, paving the way for more accurate assessments in psychological and physiological research.