 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMG-Gen: Single Image to Motion Graphics Generation with Layer Decomposition
Apr 03, 2025
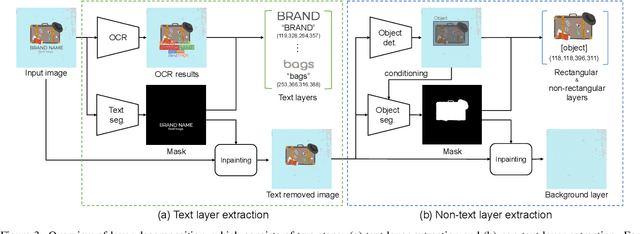


General image-to-video generation methods often produce suboptimal animations that do not meet the requirements of animated graphics, as they lack active text motion and exhibit object distortion. Also, code-based animation generation methods typically require layer-structured vector data which are often not readily available for motion graphic generation. To address these challenges, we propose a novel framework named MG-Gen that reconstructs data in vector format from a single raster image to extend the capabilities of code-based methods to enable motion graphics generation from a raster image in the framework of general image-to-video generation. MG-Gen first decomposes the input image into layer-wise elements, reconstructs them as HTML format data and then generates executable JavaScript code for the reconstructed HTML data. We experimentally confirm that \ours{} generates motion graphics while preserving text readability and input consistency. These successful results indicate that combining layer decomposition and animation code generation is an effective strategy for motion graphics generation.
TKG-DM: Training-free Chroma Key Content Generation Diffusion Model
Nov 23, 2024



Diffusion models have enabled the generation of high-quality images with a strong focus on realism and textual fidelity. Yet, large-scale text-to-image models, such as Stable Diffusion, struggle to generate images where foreground objects are placed over a chroma key background, limiting their ability to separate foreground and background elements without fine-tuning. To address this limitation, we present a novel Training-Free Chroma Key Content Generation Diffusion Model (TKG-DM), which optimizes the initial random noise to produce images with foreground objects on a specifiable color background. Our proposed method is the first to explore the manipulation of the color aspects in initial noise for controlled background generation, enabling precise separation of foreground and background without fine-tuning. Extensive experiments demonstrate that our training-free method outperforms existing methods in both qualitative and quantitative evaluations, matching or surpassing fine-tuned models. Finally, we successfully extend it to other tasks (e.g., consistency models and text-to-video), highlighting its transformative potential across various generative applications where independent control of foreground and background is crucial.
Test-Time Augmentation for Traveling Salesperson Problem
May 08, 2024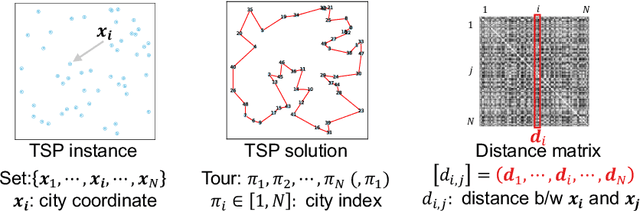
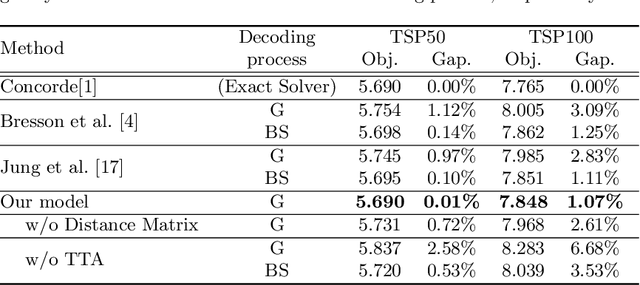
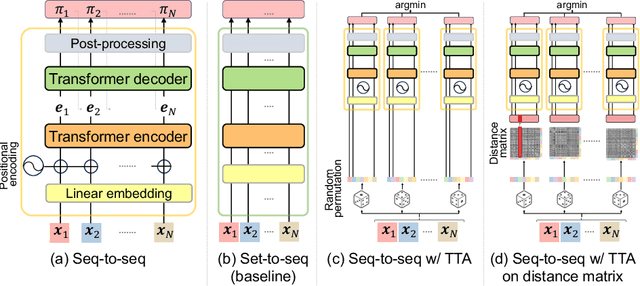
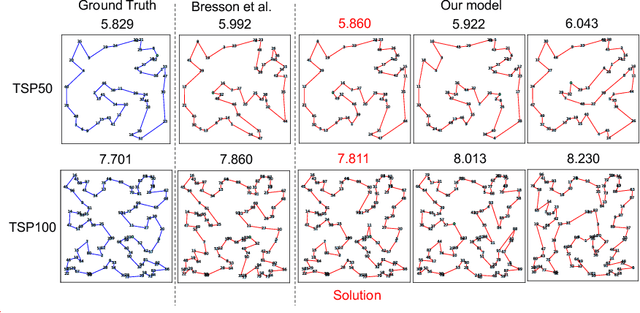
We propose Test-Time Augmentation (TTA) as an effective technique for addressing combinatorial optimization problems, including the Traveling Salesperson Problem. In general, deep learning models possessing the property of invariance, where the output is uniquely determined regardless of the node indices, have been proposed to learn graph structures efficiently. In contrast, we interpret the permutation of node indices, which exchanges the elements of the distance matrix, as a TTA scheme. The results demonstrate that our method is capable of obtaining shorter solutions than the latest models. Furthermore, we show that the probability of finding a solution closer to an exact solution increases depending on the augmentation size.
NoiseCollage: A Layout-Aware Text-to-Image Diffusion Model Based on Noise Cropping and Merging
Mar 06, 2024



Layout-aware text-to-image generation is a task to generate multi-object images that reflect layout conditions in addition to text conditions. The current layout-aware text-to-image diffusion models still have several issues, including mismatches between the text and layout conditions and quality degradation of generated images. This paper proposes a novel layout-aware text-to-image diffusion model called NoiseCollage to tackle these issues. During the denoising process, NoiseCollage independently estimates noises for individual objects and then crops and merges them into a single noise. This operation helps avoid condition mismatches; in other words, it can put the right objects in the right places. Qualitative and quantitative evaluations show that NoiseCollage outperforms several state-of-the-art models. These successful results indicate that the crop-and-merge operation of noises is a reasonable strategy to control image generation. We also show that NoiseCollage can be integrated with ControlNet to use edges, sketches, and pose skeletons as additional conditions. Experimental results show that this integration boosts the layout accuracy of ControlNet. The code is available at https://github.com/univ-esuty/noisecollage.
Ambigram Generation by A Diffusion Model
Jun 21, 2023



Ambigrams are graphical letter designs that can be read not only from the original direction but also from a rotated direction (especially with 180 degrees). Designing ambigrams is difficult even for human experts because keeping their dual readability from both directions is often difficult. This paper proposes an ambigram generation model. As its generation module, we use a diffusion model, which has recently been used to generate high-quality photographic images. By specifying a pair of letter classes, such as 'A' and 'B', the proposed model generates various ambigram images which can be read as 'A' from the original direction and 'B' from a direction rotated 180 degrees. Quantitative and qualitative analyses of experimental results show that the proposed model can generate high-quality and diverse ambigrams. In addition, we define ambigramability, an objective measure of how easy it is to generate ambigrams for each letter pair. For example, the pair of 'A' and 'V' shows a high ambigramability (that is, it is easy to generate their ambigrams), and the pair of 'D' and 'K' shows a lower ambigramability. The ambigramability gives various hints of the ambigram generation not only for computers but also for human experts. The code can be found at (https://github.com/univ-esuty/ambifusion).