 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeShape vs. Context: Examining Human--AI Gaps in Ambiguous Japanese Character Recognition
Feb 27, 2026High text recognition performance does not guarantee that Vision-Language Models (VLMs) share human-like decision patterns when resolving ambiguity. We investigate this behavioral gap by directly comparing humans and VLMs using continuously interpolated Japanese character shapes generated via a $β$-VAE. We estimate decision boundaries in a single-character recognition (shape-only task) and evaluate whether VLM responses align with human judgments under shape in context (i.e., embedding an ambiguous character near the human decision boundary in word-level context). We find that human and VLM decision boundaries differ in the shape-only task, and that shape in context can improve human alignment in some conditions. These results highlight qualitative behavioral differences, offering foundational insights toward human--VLM alignment benchmarking.
MG-Gen: Single Image to Motion Graphics Generation with Layer Decomposition
Apr 03, 2025
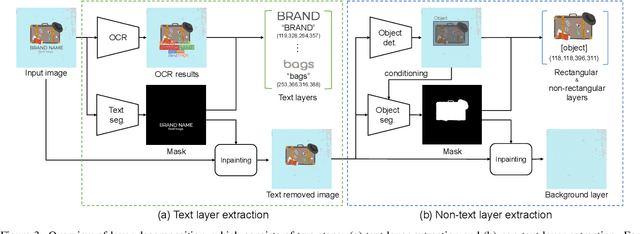


General image-to-video generation methods often produce suboptimal animations that do not meet the requirements of animated graphics, as they lack active text motion and exhibit object distortion. Also, code-based animation generation methods typically require layer-structured vector data which are often not readily available for motion graphic generation. To address these challenges, we propose a novel framework named MG-Gen that reconstructs data in vector format from a single raster image to extend the capabilities of code-based methods to enable motion graphics generation from a raster image in the framework of general image-to-video generation. MG-Gen first decomposes the input image into layer-wise elements, reconstructs them as HTML format data and then generates executable JavaScript code for the reconstructed HTML data. We experimentally confirm that \ours{} generates motion graphics while preserving text readability and input consistency. These successful results indicate that combining layer decomposition and animation code generation is an effective strategy for motion graphics generation.
Type-R: Automatically Retouching Typos for Text-to-Image Generation
Nov 27, 2024While recent text-to-image models can generate photorealistic images from text prompts that reflect detailed instructions, they still face significant challenges in accurately rendering words in the image. In this paper, we propose to retouch erroneous text renderings in the post-processing pipeline. Our approach, called Type-R, identifies typographical errors in the generated image, erases the erroneous text, regenerates text boxes for missing words, and finally corrects typos in the rendered words. Through extensive experiments, we show that Type-R, in combination with the latest text-to-image models such as Stable Diffusion or Flux, achieves the highest text rendering accuracy while maintaining image quality and also outperforms text-focused generation baselines in terms of balancing text accuracy and image quality.
Can GPTs Evaluate Graphic Design Based on Design Principles?
Oct 11, 2024Recent advancements in foundation models show promising capability in graphic design generation. Several studies have started employing Large Multimodal Models (LMMs) to evaluate graphic designs, assuming that LMMs can properly assess their quality, but it is unclear if the evaluation is reliable. One way to evaluate the quality of graphic design is to assess whether the design adheres to fundamental graphic design principles, which are the designer's common practice. In this paper, we compare the behavior of GPT-based evaluation and heuristic evaluation based on design principles using human annotations collected from 60 subjects. Our experiments reveal that, while GPTs cannot distinguish small details, they have a reasonably good correlation with human annotation and exhibit a similar tendency to heuristic metrics based on design principles, suggesting that they are indeed capable of assessing the quality of graphic design. Our dataset is available at https://cyberagentailab.github.io/Graphic-design-evaluation .
Total Disentanglement of Font Images into Style and Character Class Features
Mar 19, 2024In this paper, we demonstrate a total disentanglement of font images. Total disentanglement is a neural network-based method for decomposing each font image nonlinearly and completely into its style and content (i.e., character class) features. It uses a simple but careful training procedure to extract the common style feature from all `A'-`Z' images in the same font and the common content feature from all `A' (or another class) images in different fonts. These disentangled features guarantee the reconstruction of the original font image. Various experiments have been conducted to understand the performance of total disentanglement. First, it is demonstrated that total disentanglement is achievable with very high accuracy; this is experimental proof of the long-standing open question, ``Does `A'-ness exist?'' Hofstadter (1985). Second, it is demonstrated that the disentangled features produced by total disentanglement apply to a variety of tasks, including font recognition, character recognition, and one-shot font image generation.
Cross-Domain Image Conversion by CycleDM
Mar 05, 2024



The purpose of this paper is to enable the conversion between machine-printed character images (i.e., font images) and handwritten character images through machine learning. For this purpose, we propose a novel unpaired image-to-image domain conversion method, CycleDM, which incorporates the concept of CycleGAN into the diffusion model. Specifically, CycleDM has two internal conversion models that bridge the denoising processes of two image domains. These conversion models are efficiently trained without explicit correspondence between the domains. By applying machine-printed and handwritten character images to the two modalities, CycleDM realizes the conversion between them. Our experiments for evaluating the converted images quantitatively and qualitatively found that ours performs better than other comparable approaches.
Impression-CLIP: Contrastive Shape-Impression Embedding for Fonts
Feb 26, 2024



Fonts convey different impressions to readers. These impressions often come from the font shapes. However, the correlation between fonts and their impression is weak and unstable because impressions are subjective. To capture such weak and unstable cross-modal correlation between font shapes and their impressions, we propose Impression-CLIP, which is a novel machine-learning model based on CLIP (Contrastive Language-Image Pre-training). By using the CLIP-based model, font image features and their impression features are pulled closer, and font image features and unrelated impression features are pushed apart. This procedure realizes co-embedding between font image and their impressions. In our experiment, we perform cross-modal retrieval between fonts and impressions through co-embedding. The results indicate that Impression-CLIP achieves better retrieval accuracy than the state-of-the-art method. Additionally, our model shows the robustness to noise and missing tags.
What Text Design Characterizes Book Genres?
Feb 26, 2024



This study analyzes the relationship between non-verbal information (e.g., genres) and text design (e.g., font style, character color, etc.) through the classification of book genres using text design on book covers. Text images have both semantic information about the word itself and other information (non-semantic information or visual design), such as font style, character color, etc. When we read a word printed on some materials, we receive impressions or other information from both the word itself and the visual design. Basically, we can understand verbal information only from semantic information, i.e., the words themselves; however, we can consider that text design is helpful for understanding other additional information (i.e., non-verbal information), such as impressions, genre, etc. To investigate the effect of text design, we analyze text design using words printed on book covers and their genres in two scenarios. First, we attempted to understand the importance of visual design for determining the genre (i.e., non-verbal information) of books by analyzing the differences in the relationship between semantic information/visual design and genres. In the experiment, we found that semantic information is sufficient to determine the genre; however, text design is helpful in adding more discriminative features for book genres. Second, we investigated the effect of each text design on book genres. As a result, we found that each text design characterizes some book genres. For example, font style is useful to add more discriminative features for genres of ``Mystery, Thriller \& Suspense'' and ``Christian books \& Bibles.''
Font Impression Estimation in the Wild
Feb 23, 2024



This paper addresses the challenging task of estimating font impressions from real font images. We use a font dataset with annotation about font impressions and a convolutional neural network (CNN) framework for this task. However, impressions attached to individual fonts are often missing and noisy because of the subjective characteristic of font impression annotation. To realize stable impression estimation even with such a dataset, we propose an exemplar-based impression estimation approach, which relies on a strategy of ensembling impressions of exemplar fonts that are similar to the input image. In addition, we train CNN with synthetic font images that mimic scanned word images so that CNN estimates impressions of font images in the wild. We evaluate the basic performance of the proposed estimation method quantitatively and qualitatively. Then, we conduct a correlation analysis between book genres and font impressions on real book cover images; it is important to note that this analysis is only possible with our impression estimation method. The analysis reveals various trends in the correlation between them - this fact supports a hypothesis that book cover designers carefully choose a font for a book cover considering the impression given by the font.
Typographic Text Generation with Off-the-Shelf Diffusion Model
Feb 22, 2024Recent diffusion-based generative models show promise in their ability to generate text images, but limitations in specifying the styles of the generated texts render them insufficient in the realm of typographic design. This paper proposes a typographic text generation system to add and modify text on typographic designs while specifying font styles, colors, and text effects. The proposed system is a novel combination of two off-the-shelf methods for diffusion models, ControlNet and Blended Latent Diffusion. The former functions to generate text images under the guidance of edge conditions specifying stroke contours. The latter blends latent noise in Latent Diffusion Models (LDM) to add typographic text naturally onto an existing background. We first show that given appropriate text edges, ControlNet can generate texts in specified fonts while incorporating effects described by prompts. We further introduce text edge manipulation as an intuitive and customizable way to produce texts with complex effects such as ``shadows'' and ``reflections''. Finally, with the proposed system, we successfully add and modify texts on a predefined background while preserving its overall coherence.