 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluating Cross-Modal Reasoning Ability and Problem Characteristics with Multimodal Item Response Theory
Mar 03, 2026Multimodal Large Language Models (MLLMs) have recently emerged as general architectures capable of reasoning over diverse modalities. Benchmarks for MLLMs should measure their ability for cross-modal integration. However, current benchmarks are filled with shortcut questions, which can be solved using only a single modality, thereby yielding unreliable rankings. For example, in vision-language cases, we can find the correct answer without either the image or the text. These low-quality questions unnecessarily increase the size and computational requirements of benchmarks. We introduce a multi-modal and multidimensional item response theory framework (M3IRT) that extends classical IRT by decomposing both model ability and item difficulty into image-only, text-only, and cross-modal components. M3IRT estimates cross-modal ability of MLLMs and each question's cross-modal difficulty, enabling compact, high-quality subsets that better reflect multimodal reasoning. Across 24 VLMs on three benchmarks, M3IRT prioritizes genuinely cross-modal questions over shortcuts and preserves ranking fidelity even when 50% of items are artificially generated low-quality questions, thereby reducing evaluation cost while improving reliability. M3IRT thus offers a practical tool for assessing cross-modal reasoning and refining multimodal benchmarks.
Training-free Conditional Image Embedding Framework Leveraging Large Vision Language Models
Dec 26, 2025Conditional image embeddings are feature representations that focus on specific aspects of an image indicated by a given textual condition (e.g., color, genre), which has been a challenging problem. Although recent vision foundation models, such as CLIP, offer rich representations of images, they are not designed to focus on a specified condition. In this paper, we propose DIOR, a method that leverages a large vision-language model (LVLM) to generate conditional image embeddings. DIOR is a training-free approach that prompts the LVLM to describe an image with a single word related to a given condition. The hidden state vector of the LVLM's last token is then extracted as the conditional image embedding. DIOR provides a versatile solution that can be applied to any image and condition without additional training or task-specific priors. Comprehensive experimental results on conditional image similarity tasks demonstrate that DIOR outperforms existing training-free baselines, including CLIP. Furthermore, DIOR achieves superior performance compared to methods that require additional training across multiple settings.
ColorGPT: Leveraging Large Language Models for Multimodal Color Recommendation
Aug 12, 2025Colors play a crucial role in the design of vector graphic documents by enhancing visual appeal, facilitating communication, improving usability, and ensuring accessibility. In this context, color recommendation involves suggesting appropriate colors to complete or refine a design when one or more colors are missing or require alteration. Traditional methods often struggled with these challenges due to the complex nature of color design and the limited data availability. In this study, we explored the use of pretrained Large Language Models (LLMs) and their commonsense reasoning capabilities for color recommendation, raising the question: Can pretrained LLMs serve as superior designers for color recommendation tasks? To investigate this, we developed a robust, rigorously validated pipeline, ColorGPT, that was built by systematically testing multiple color representations and applying effective prompt engineering techniques. Our approach primarily targeted color palette completion by recommending colors based on a set of given colors and accompanying context. Moreover, our method can be extended to full palette generation, producing an entire color palette corresponding to a provided textual description. Experimental results demonstrated that our LLM-based pipeline outperformed existing methods in terms of color suggestion accuracy and the distribution of colors in the color palette completion task. For the full palette generation task, our approach also yielded improvements in color diversity and similarity compared to current techniques.
Type-R: Automatically Retouching Typos for Text-to-Image Generation
Nov 27, 2024While recent text-to-image models can generate photorealistic images from text prompts that reflect detailed instructions, they still face significant challenges in accurately rendering words in the image. In this paper, we propose to retouch erroneous text renderings in the post-processing pipeline. Our approach, called Type-R, identifies typographical errors in the generated image, erases the erroneous text, regenerates text boxes for missing words, and finally corrects typos in the rendered words. Through extensive experiments, we show that Type-R, in combination with the latest text-to-image models such as Stable Diffusion or Flux, achieves the highest text rendering accuracy while maintaining image quality and also outperforms text-focused generation baselines in terms of balancing text accuracy and image quality.
Can GPTs Evaluate Graphic Design Based on Design Principles?
Oct 11, 2024Recent advancements in foundation models show promising capability in graphic design generation. Several studies have started employing Large Multimodal Models (LMMs) to evaluate graphic designs, assuming that LMMs can properly assess their quality, but it is unclear if the evaluation is reliable. One way to evaluate the quality of graphic design is to assess whether the design adheres to fundamental graphic design principles, which are the designer's common practice. In this paper, we compare the behavior of GPT-based evaluation and heuristic evaluation based on design principles using human annotations collected from 60 subjects. Our experiments reveal that, while GPTs cannot distinguish small details, they have a reasonably good correlation with human annotation and exhibit a similar tendency to heuristic metrics based on design principles, suggesting that they are indeed capable of assessing the quality of graphic design. Our dataset is available at https://cyberagentailab.github.io/Graphic-design-evaluation .
Multimodal Markup Document Models for Graphic Design Completion
Sep 27, 2024



This paper presents multimodal markup document models (MarkupDM) that can generate both markup language and images within interleaved multimodal documents. Unlike existing vision-and-language multimodal models, our MarkupDM tackles unique challenges critical to graphic design tasks: generating partial images that contribute to the overall appearance, often involving transparency and varying sizes, and understanding the syntax and semantics of markup languages, which play a fundamental role as a representational format of graphic designs. To address these challenges, we design an image quantizer to tokenize images of diverse sizes with transparency and modify a code language model to process markup languages and incorporate image modalities. We provide in-depth evaluations of our approach on three graphic design completion tasks: generating missing attribute values, images, and texts in graphic design templates. Results corroborate the effectiveness of our MarkupDM for graphic design tasks. We also discuss the strengths and weaknesses in detail, providing insights for future research on multimodal document generation.
LTSim: Layout Transportation-based Similarity Measure for Evaluating Layout Generation
Jul 17, 2024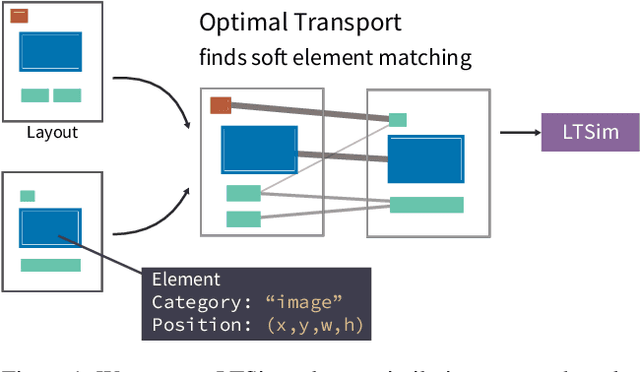

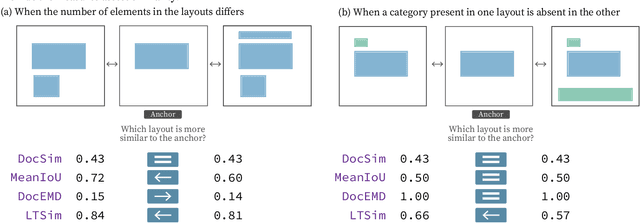
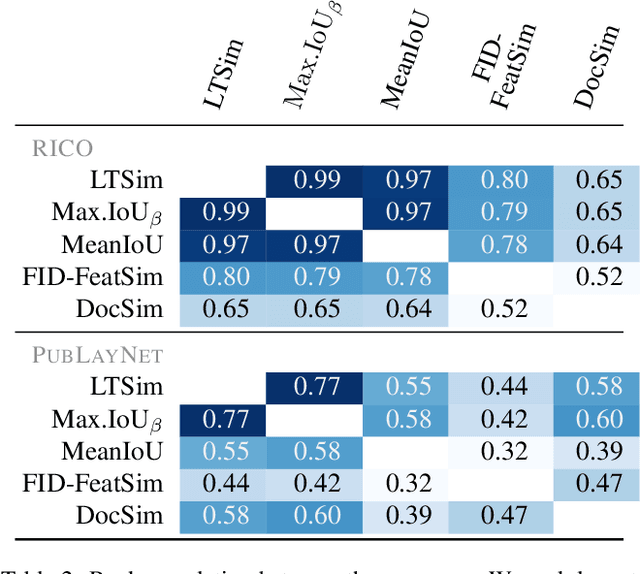
We introduce a layout similarity measure designed to evaluate the results of layout generation. While several similarity measures have been proposed in prior research, there has been a lack of comprehensive discussion about their behaviors. Our research uncovers that the majority of these measures are unable to handle various layout differences, primarily due to their dependencies on strict element matching, that is one-by-one matching of elements within the same category. To overcome this limitation, we propose a new similarity measure based on optimal transport, which facilitates a more flexible matching of elements. This approach allows us to quantify the similarity between any two layouts even those sharing no element categories, making our measure highly applicable to a wide range of layout generation tasks. For tasks such as unconditional layout generation, where FID is commonly used, we also extend our measure to deal with collection-level similarities between groups of layouts. The empirical result suggests that our collection-level measure offers more reliable comparisons than existing ones like FID and Max.IoU.
OpenCOLE: Towards Reproducible Automatic Graphic Design Generation
Jun 12, 2024



Automatic generation of graphic designs has recently received considerable attention. However, the state-of-the-art approaches are complex and rely on proprietary datasets, which creates reproducibility barriers. In this paper, we propose an open framework for automatic graphic design called OpenCOLE, where we build a modified version of the pioneering COLE and train our model exclusively on publicly available datasets. Based on GPT4V evaluations, our model shows promising performance comparable to the original COLE. We release the pipeline and training results to encourage open development.
LayoutFlow: Flow Matching for Layout Generation
Mar 27, 2024Finding a suitable layout represents a crucial task for diverse applications in graphic design. Motivated by simpler and smoother sampling trajectories, we explore the use of Flow Matching as an alternative to current diffusion-based layout generation models. Specifically, we propose LayoutFlow, an efficient flow-based model capable of generating high-quality layouts. Instead of progressively denoising the elements of a noisy layout, our method learns to gradually move, or flow, the elements of an initial sample until it reaches its final prediction. In addition, we employ a conditioning scheme that allows us to handle various generation tasks with varying degrees of conditioning with a single model. Empirically, LayoutFlow performs on par with state-of-the-art models while being significantly faster.
Retrieval-Augmented Layout Transformer for Content-Aware Layout Generation
Nov 22, 2023
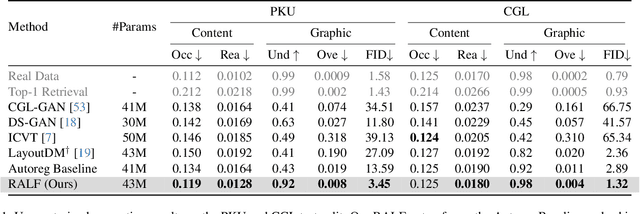

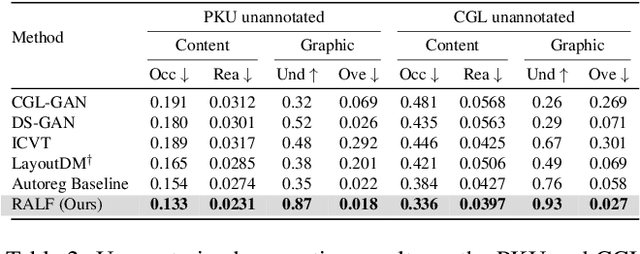
Content-aware graphic layout generation aims to automatically arrange visual elements along with a given content, such as an e-commerce product image. In this paper, we argue that the current layout generation approaches suffer from the limited training data for the high-dimensional layout structure. We show that a simple retrieval augmentation can significantly improve the generation quality. Our model, which is named Retrieval-Augmented Layout Transformer (RALF), retrieves nearest neighbor layout examples based on an input image and feeds these results into an autoregressive generator. Our model can apply retrieval augmentation to various controllable generation tasks and yield high-quality layouts within a unified architecture. Our extensive experiments show that RALF successfully generates content-aware layouts in both constrained and unconstrained settings and significantly outperforms the baselines.