 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Match Maximization and Fairness: Retention-Optimized Two-Sided Matching
Feb 17, 2026On two-sided matching platforms such as online dating and recruiting, recommendation algorithms often aim to maximize the total number of matches. However, this objective creates an imbalance, where some users receive far too many matches while many others receive very few and eventually abandon the platform. Retaining users is crucial for many platforms, such as those that depend heavily on subscriptions. Some may use fairness objectives to solve the problem of match maximization. However, fairness in itself is not the ultimate objective for many platforms, as users do not suddenly reward the platform simply because exposure is equalized. In practice, where user retention is often the ultimate goal, casually relying on fairness will leave the optimization of retention up to luck. In this work, instead of maximizing matches or axiomatically defining fairness, we formally define the new problem setting of maximizing user retention in two-sided matching platforms. To this end, we introduce a dynamic learning-to-rank (LTR) algorithm called Matching for Retention (MRet). Unlike conventional algorithms for two-sided matching, our approach models user retention by learning personalized retention curves from each user's profile and interaction history. Based on these curves, MRet dynamically adapts recommendations by jointly considering the retention gains of both the user receiving recommendations and those who are being recommended, so that limited matching opportunities can be allocated where they most improve overall retention. Naturally but importantly, empirical evaluations on synthetic and real-world datasets from a major online dating platform show that MRet achieves higher user retention, since conventional methods optimize matches or fairness rather than retention.
Instance-wise Supervision-level Optimization in Active Learning
Mar 09, 2025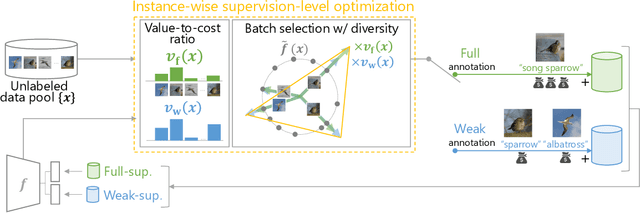

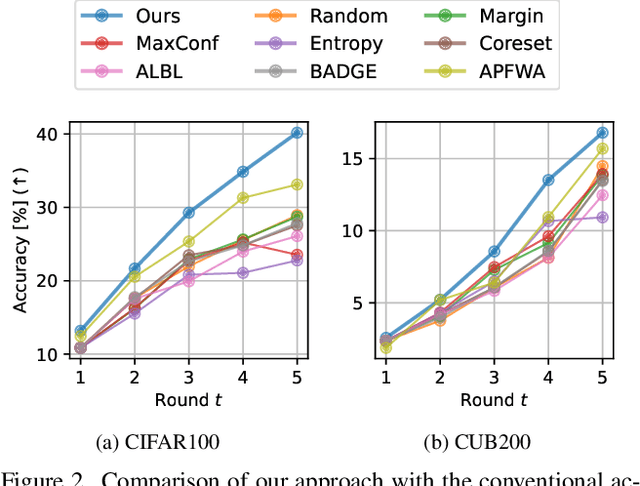
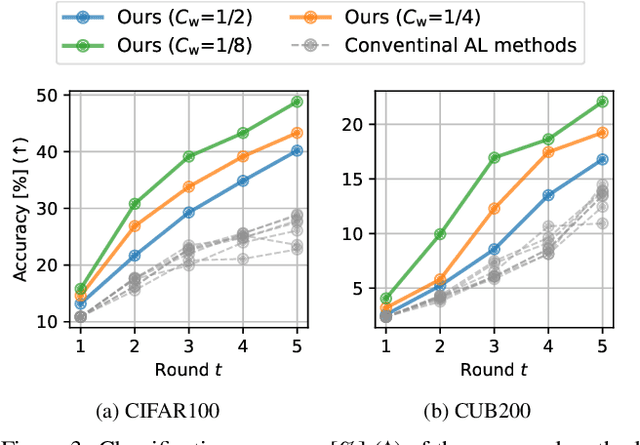
Active learning (AL) is a label-efficient machine learning paradigm that focuses on selectively annotating high-value instances to maximize learning efficiency. Its effectiveness can be further enhanced by incorporating weak supervision, which uses rough yet cost-effective annotations instead of exact (i.e., full) but expensive annotations. We introduce a novel AL framework, Instance-wise Supervision-Level Optimization (ISO), which not only selects the instances to annotate but also determines their optimal annotation level within a fixed annotation budget. Its optimization criterion leverages the value-to-cost ratio (VCR) of each instance while ensuring diversity among the selected instances. In classification experiments, ISO consistently outperforms traditional AL methods and surpasses a state-of-the-art AL approach that combines full and weak supervision, achieving higher accuracy at a lower overall cost. This code is available at https://github.com/matsuo-shinnosuke/ISOAL.
LTSim: Layout Transportation-based Similarity Measure for Evaluating Layout Generation
Jul 17, 2024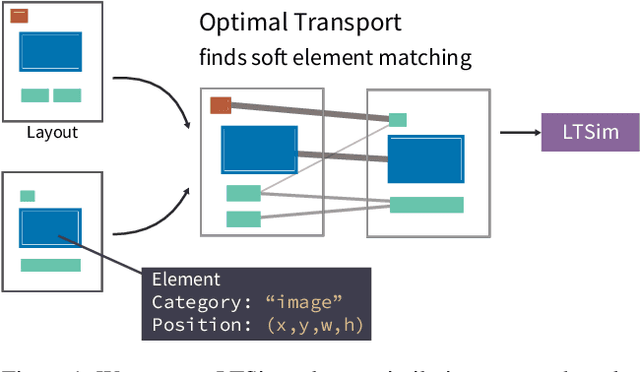

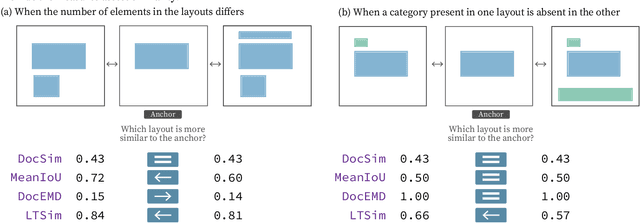
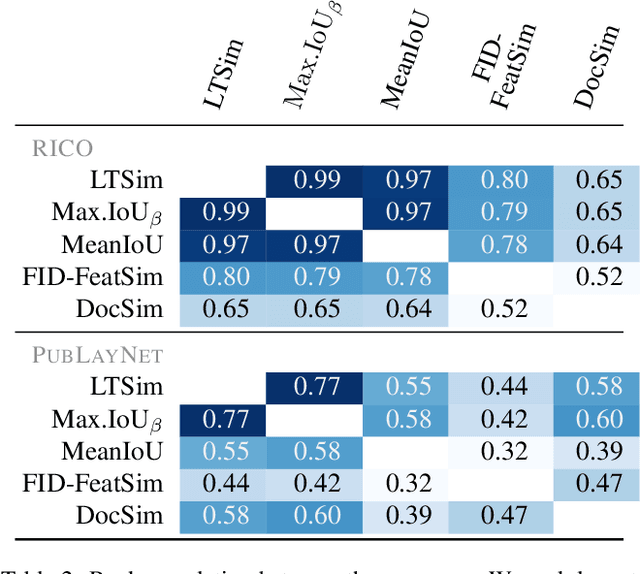
We introduce a layout similarity measure designed to evaluate the results of layout generation. While several similarity measures have been proposed in prior research, there has been a lack of comprehensive discussion about their behaviors. Our research uncovers that the majority of these measures are unable to handle various layout differences, primarily due to their dependencies on strict element matching, that is one-by-one matching of elements within the same category. To overcome this limitation, we propose a new similarity measure based on optimal transport, which facilitates a more flexible matching of elements. This approach allows us to quantify the similarity between any two layouts even those sharing no element categories, making our measure highly applicable to a wide range of layout generation tasks. For tasks such as unconditional layout generation, where FID is commonly used, we also extend our measure to deal with collection-level similarities between groups of layouts. The empirical result suggests that our collection-level measure offers more reliable comparisons than existing ones like FID and Max.IoU.
Scalable and Provably Fair Exposure Control for Large-Scale Recommender Systems
Feb 22, 2024



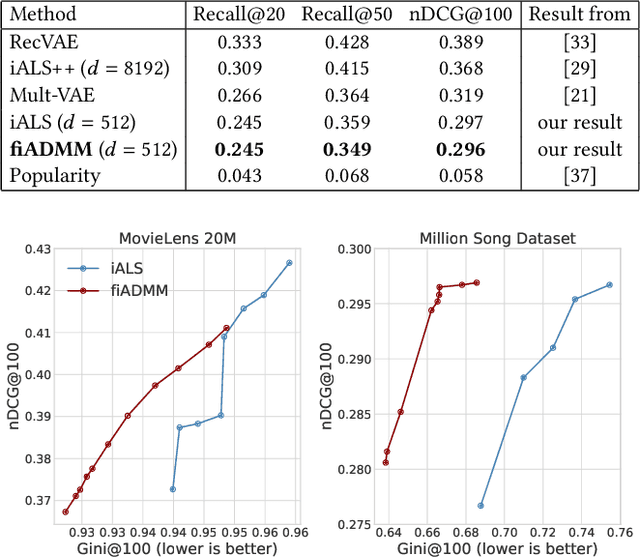
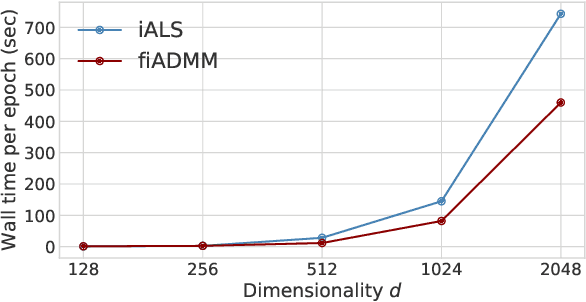
Typical recommendation and ranking methods aim to optimize the satisfaction of users, but they are often oblivious to their impact on the items (e.g., products, jobs, news, video) and their providers. However, there has been a growing understanding that the latter is crucial to consider for a wide range of applications, since it determines the utility of those being recommended. Prior approaches to fairness-aware recommendation optimize a regularized objective to balance user satisfaction and item fairness based on some notion such as exposure fairness. These existing methods have been shown to be effective in controlling fairness, however, most of them are computationally inefficient, limiting their applications to only unrealistically small-scale situations. This indeed implies that the literature does not yet provide a solution to enable a flexible control of exposure in the industry-scale recommender systems where millions of users and items exist. To enable a computationally efficient exposure control even for such large-scale systems, this work develops a scalable, fast, and fair method called \emph{\textbf{ex}posure-aware \textbf{ADMM} (\textbf{exADMM})}. exADMM is based on implicit alternating least squares (iALS), a conventional scalable algorithm for collaborative filtering, but optimizes a regularized objective to achieve a flexible control of accuracy-fairness tradeoff. A particular technical challenge in developing exADMM is the fact that the fairness regularizer destroys the separability of optimization subproblems for users and items, which is an essential property to ensure the scalability of iALS. Therefore, we develop a set of optimization tools to enable yet scalable fairness control with provable convergence guarantees as a basis of our algorithm.
Fast and Examination-agnostic Reciprocal Recommendation in Matching Markets
Jun 15, 2023In matching markets such as job posting and online dating platforms, the recommender system plays a critical role in the success of the platform. Unlike standard recommender systems that suggest items to users, reciprocal recommender systems (RRSs) that suggest other users must take into account the mutual interests of users. In addition, ensuring that recommendation opportunities do not disproportionately favor popular users is essential for the total number of matches and for fairness among users. Existing recommendation methods in matching markets, however, face computational challenges on large-scale platforms and depend on specific examination functions in the position-based model (PBM). In this paper, we introduce the reciprocal recommendation method based on the matching with transferable utility (TU matching) model in the context of ranking recommendations in matching markets and propose a fast and examination-model-free algorithm. Furthermore, we evaluate our approach on experiments with synthetic data and real-world data from an online dating platform in Japan. Our method performs better than or as well as existing methods in terms of the total number of matches and works well even in a large-scale dataset for which one existing method does not work.
Safe Collaborative Filtering
Jun 08, 2023Excellent tail performance is crucial for modern machine learning tasks, such as algorithmic fairness, class imbalance, and risk-sensitive decision making, as it ensures the effective handling of challenging samples within a dataset. Tail performance is also a vital determinant of success for personalised recommender systems to reduce the risk of losing users with low satisfaction. This study introduces a "safe" collaborative filtering method that prioritises recommendation quality for less-satisfied users rather than focusing on the average performance. Our approach minimises the conditional value at risk (CVaR), which represents the average risk over the tails of users' loss. To overcome computational challenges for web-scale recommender systems, we develop a robust yet practical algorithm that extends the most scalable method, implicit alternating least squares (iALS). Empirical evaluation on real-world datasets demonstrates the excellent tail performance of our approach while maintaining competitive computational efficiency.
Curse of "Low" Dimensionality in Recommender Systems
May 23, 2023Beyond accuracy, there are a variety of aspects to the quality of recommender systems, such as diversity, fairness, and robustness. We argue that many of the prevalent problems in recommender systems are partly due to low-dimensionality of user and item embeddings, particularly when dot-product models, such as matrix factorization, are used. In this study, we showcase empirical evidence suggesting the necessity of sufficient dimensionality for user/item embeddings to achieve diverse, fair, and robust recommendation. We then present theoretical analyses of the expressive power of dot-product models. Our theoretical results demonstrate that the number of possible rankings expressible under dot-product models is exponentially bounded by the dimension of item factors. We empirically found that the low-dimensionality contributes to a popularity bias, widening the gap between the rank positions of popular and long-tail items; we also give a theoretical justification for this phenomenon.
A Critical Reexamination of Intra-List Distance and Dispersion
May 23, 2023Diversification of recommendation results is a promising approach for coping with the uncertainty associated with users' information needs. Of particular importance in diversified recommendation is to define and optimize an appropriate diversity objective. In this study, we revisit the most popular diversity objective called intra-list distance (ILD), defined as the average pairwise distance between selected items, and a similar but lesser known objective called dispersion, which is the minimum pairwise distance. Owing to their simplicity and flexibility, ILD and dispersion have been used in a plethora of diversified recommendation research. Nevertheless, we do not actually know what kind of items are preferred by them. We present a critical reexamination of ILD and dispersion from theoretical and experimental perspectives. Our theoretical results reveal that these objectives have potential drawbacks: ILD may select duplicate items that are very close to each other, whereas dispersion may overlook distant item pairs. As a competitor to ILD and dispersion, we design a diversity objective called Gaussian ILD, which can interpolate between ILD and dispersion by tuning the bandwidth parameter. We verify our theoretical results by experimental results using real-world data and confirm the extreme behavior of ILD and dispersion in practice.
Toward Verifiable and Reproducible Human Evaluation for Text-to-Image Generation
Apr 04, 2023



Human evaluation is critical for validating the performance of text-to-image generative models, as this highly cognitive process requires deep comprehension of text and images. However, our survey of 37 recent papers reveals that many works rely solely on automatic measures (e.g., FID) or perform poorly described human evaluations that are not reliable or repeatable. This paper proposes a standardized and well-defined human evaluation protocol to facilitate verifiable and reproducible human evaluation in future works. In our pilot data collection, we experimentally show that the current automatic measures are incompatible with human perception in evaluating the performance of the text-to-image generation results. Furthermore, we provide insights for designing human evaluation experiments reliably and conclusively. Finally, we make several resources publicly available to the community to facilitate easy and fast implementations.
Fair Matrix Factorisation for Large-Scale Recommender Systems
Sep 09, 2022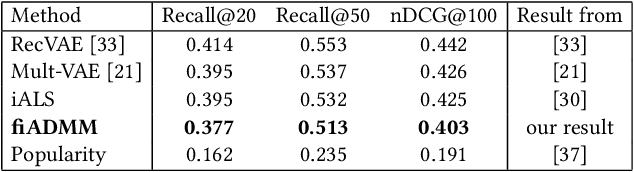

Modern recommender systems are hedged with various requirements, such as ranking quality, optimisation efficiency, and item fairness. It is challenging to reconcile these requirements at a practical level. In this study, we argue that item fairness is particularly hard to optimise in a large-scale setting. The notion of item fairness requires controlling the opportunity of items (e.g. exposure) by considering the entire ranked lists for users. It hence breaks the independence of optimisation subproblems for users and items, which is the essential property for conventional scalable algorithms, such as implicit alternating least squares (iALS). This paper explores a collaborative filtering method for fairness-aware item recommendation, achieving computational efficiency comparable to iALS, the most efficient method for item recommendation.