 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeColor Recommendation for Vector Graphic Documents based on Multi-Palette Representation
Sep 22, 2022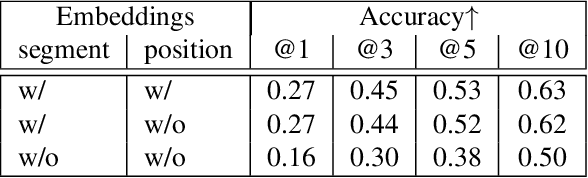
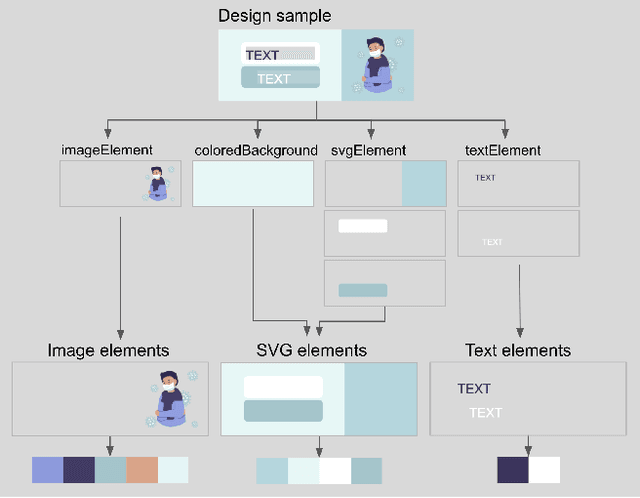
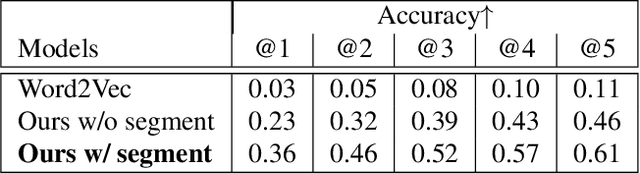
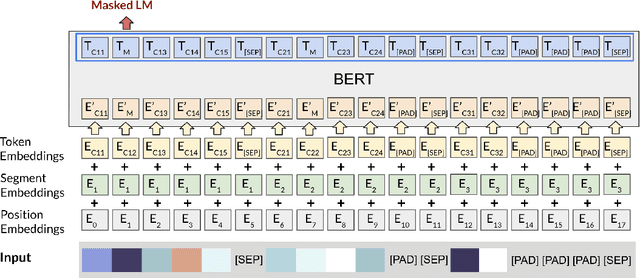
Vector graphic documents present multiple visual elements, such as images, shapes, and texts. Choosing appropriate colors for multiple visual elements is a difficult but crucial task for both amateurs and professional designers. Instead of creating a single color palette for all elements, we extract multiple color palettes from each visual element in a graphic document, and then combine them into a color sequence. We propose a masked color model for color sequence completion and recommend the specified colors based on color context in multi-palette with high probability. We train the model and build a color recommendation system on a large-scale dataset of vector graphic documents. The proposed color recommendation method outperformed other state-of-the-art methods by both quantitative and qualitative evaluations on color prediction and our color recommendation system received positive feedback from professional designers in an interview study.
DM$^2$S$^2$: Deep Multi-Modal Sequence Sets with Hierarchical Modality Attention
Sep 07, 2022
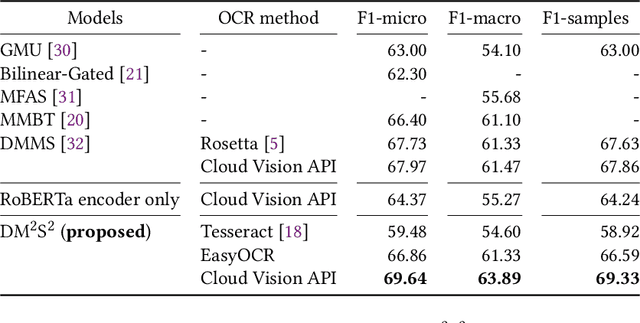
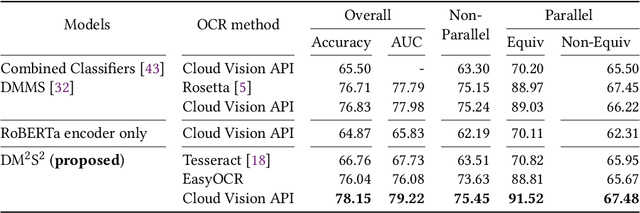

There is increasing interest in the use of multimodal data in various web applications, such as digital advertising and e-commerce. Typical methods for extracting important information from multimodal data rely on a mid-fusion architecture that combines the feature representations from multiple encoders. However, as the number of modalities increases, several potential problems with the mid-fusion model structure arise, such as an increase in the dimensionality of the concatenated multimodal features and missing modalities. To address these problems, we propose a new concept that considers multimodal inputs as a set of sequences, namely, deep multimodal sequence sets (DM$^2$S$^2$). Our set-aware concept consists of three components that capture the relationships among multiple modalities: (a) a BERT-based encoder to handle the inter- and intra-order of elements in the sequences, (b) intra-modality residual attention (IntraMRA) to capture the importance of the elements in a modality, and (c) inter-modality residual attention (InterMRA) to enhance the importance of elements with modality-level granularity further. Our concept exhibits performance that is comparable to or better than the previous set-aware models. Furthermore, we demonstrate that the visualization of the learned InterMRA and IntraMRA weights can provide an interpretation of the prediction results.