 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluating Cross-Modal Reasoning Ability and Problem Characteristics with Multimodal Item Response Theory
Mar 03, 2026Multimodal Large Language Models (MLLMs) have recently emerged as general architectures capable of reasoning over diverse modalities. Benchmarks for MLLMs should measure their ability for cross-modal integration. However, current benchmarks are filled with shortcut questions, which can be solved using only a single modality, thereby yielding unreliable rankings. For example, in vision-language cases, we can find the correct answer without either the image or the text. These low-quality questions unnecessarily increase the size and computational requirements of benchmarks. We introduce a multi-modal and multidimensional item response theory framework (M3IRT) that extends classical IRT by decomposing both model ability and item difficulty into image-only, text-only, and cross-modal components. M3IRT estimates cross-modal ability of MLLMs and each question's cross-modal difficulty, enabling compact, high-quality subsets that better reflect multimodal reasoning. Across 24 VLMs on three benchmarks, M3IRT prioritizes genuinely cross-modal questions over shortcuts and preserves ranking fidelity even when 50% of items are artificially generated low-quality questions, thereby reducing evaluation cost while improving reliability. M3IRT thus offers a practical tool for assessing cross-modal reasoning and refining multimodal benchmarks.
Measure Twice, Cut Once: Grasping Video Structures and Event Semantics with LLMs for Video Temporal Localization
Mar 12, 2025



Localizing user-queried events through natural language is crucial for video understanding models. Recent methods predominantly adapt Video LLMs to generate event boundary timestamps to handle temporal localization tasks, which struggle to leverage LLMs' powerful semantic understanding. In this work, we introduce MeCo, a novel timestamp-free framework that enables video LLMs to fully harness their intrinsic semantic capabilities for temporal localization tasks. Rather than outputting boundary timestamps, MeCo partitions videos into holistic event and transition segments based on the proposed structural token generation and grounding pipeline, derived from video LLMs' temporal structure understanding capability. We further propose a query-focused captioning task that compels the LLM to extract fine-grained, event-specific details, bridging the gap between localization and higher-level semantics and enhancing localization performance. Extensive experiments on diverse temporal localization tasks show that MeCo consistently outperforms boundary-centric methods, underscoring the benefits of a semantic-driven approach for temporal localization with video LLMs.
Harnessing the Latent Diffusion Model for Training-Free Image Style Transfer
Oct 02, 2024



Diffusion models have recently shown the ability to generate high-quality images. However, controlling its generation process still poses challenges. The image style transfer task is one of those challenges that transfers the visual attributes of a style image to another content image. Typical obstacle of this task is the requirement of additional training of a pre-trained model. We propose a training-free style transfer algorithm, Style Tracking Reverse Diffusion Process (STRDP) for a pretrained Latent Diffusion Model (LDM). Our algorithm employs Adaptive Instance Normalization (AdaIN) function in a distinct manner during the reverse diffusion process of an LDM while tracking the encoding history of the style image. This algorithm enables style transfer in the latent space of LDM for reduced computational cost, and provides compatibility for various LDM models. Through a series of experiments and a user study, we show that our method can quickly transfer the style of an image without additional training. The speed, compatibility, and training-free aspect of our algorithm facilitates agile experiments with combinations of styles and LDMs for extensive application.
Multimodal Markup Document Models for Graphic Design Completion
Sep 27, 2024



This paper presents multimodal markup document models (MarkupDM) that can generate both markup language and images within interleaved multimodal documents. Unlike existing vision-and-language multimodal models, our MarkupDM tackles unique challenges critical to graphic design tasks: generating partial images that contribute to the overall appearance, often involving transparency and varying sizes, and understanding the syntax and semantics of markup languages, which play a fundamental role as a representational format of graphic designs. To address these challenges, we design an image quantizer to tokenize images of diverse sizes with transparency and modify a code language model to process markup languages and incorporate image modalities. We provide in-depth evaluations of our approach on three graphic design completion tasks: generating missing attribute values, images, and texts in graphic design templates. Results corroborate the effectiveness of our MarkupDM for graphic design tasks. We also discuss the strengths and weaknesses in detail, providing insights for future research on multimodal document generation.
LTSim: Layout Transportation-based Similarity Measure for Evaluating Layout Generation
Jul 17, 2024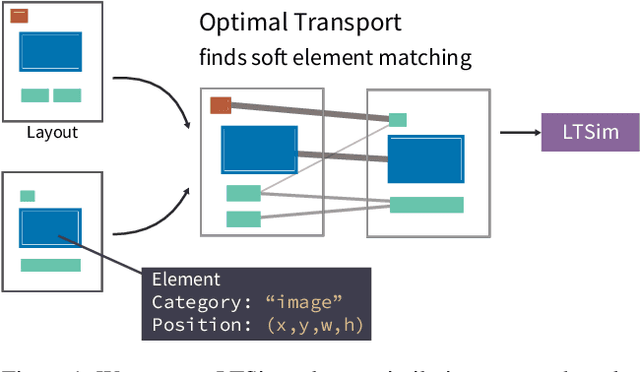

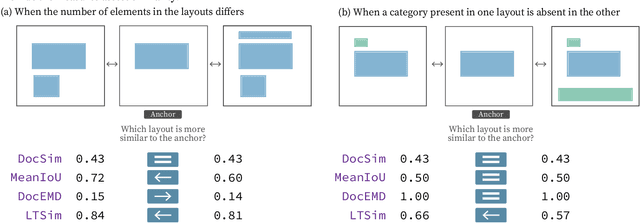
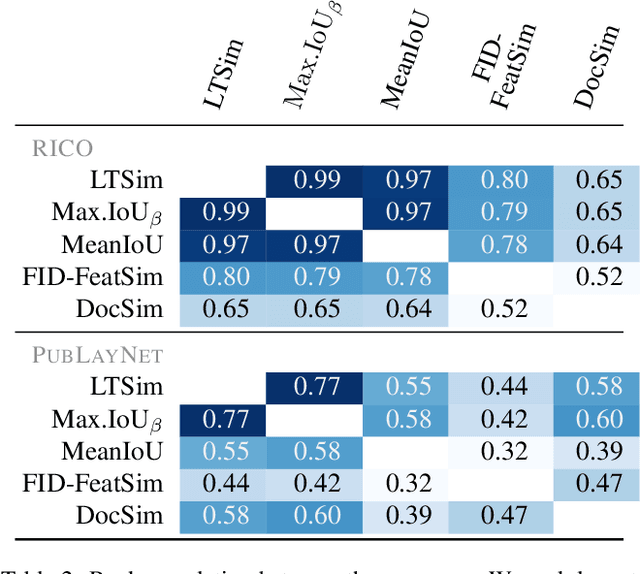
We introduce a layout similarity measure designed to evaluate the results of layout generation. While several similarity measures have been proposed in prior research, there has been a lack of comprehensive discussion about their behaviors. Our research uncovers that the majority of these measures are unable to handle various layout differences, primarily due to their dependencies on strict element matching, that is one-by-one matching of elements within the same category. To overcome this limitation, we propose a new similarity measure based on optimal transport, which facilitates a more flexible matching of elements. This approach allows us to quantify the similarity between any two layouts even those sharing no element categories, making our measure highly applicable to a wide range of layout generation tasks. For tasks such as unconditional layout generation, where FID is commonly used, we also extend our measure to deal with collection-level similarities between groups of layouts. The empirical result suggests that our collection-level measure offers more reliable comparisons than existing ones like FID and Max.IoU.
Would Deep Generative Models Amplify Bias in Future Models?
Apr 04, 2024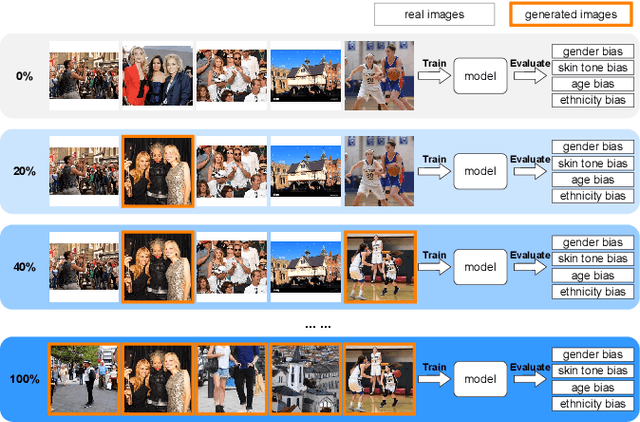
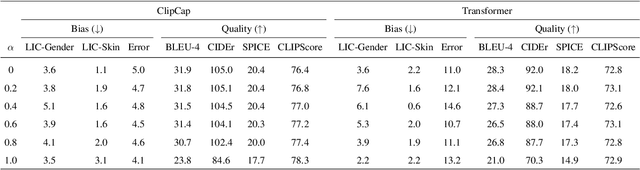
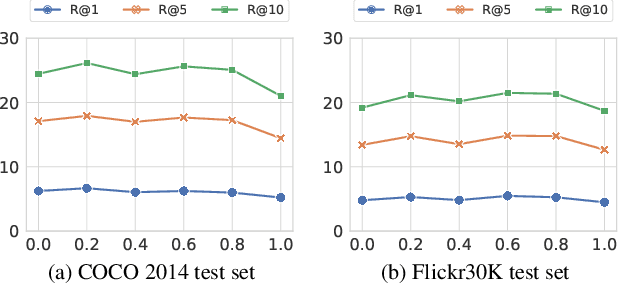
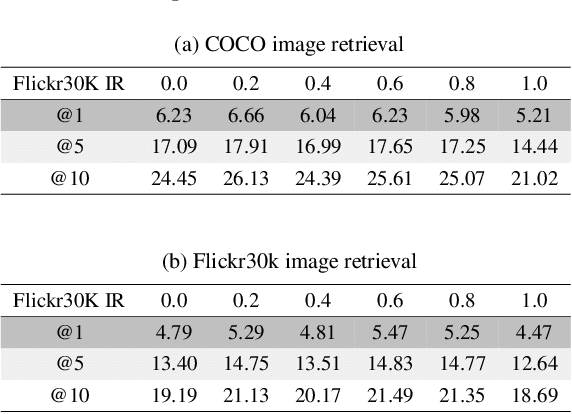
We investigate the impact of deep generative models on potential social biases in upcoming computer vision models. As the internet witnesses an increasing influx of AI-generated images, concerns arise regarding inherent biases that may accompany them, potentially leading to the dissemination of harmful content. This paper explores whether a detrimental feedback loop, resulting in bias amplification, would occur if generated images were used as the training data for future models. We conduct simulations by progressively substituting original images in COCO and CC3M datasets with images generated through Stable Diffusion. The modified datasets are used to train OpenCLIP and image captioning models, which we evaluate in terms of quality and bias. Contrary to expectations, our findings indicate that introducing generated images during training does not uniformly amplify bias. Instead, instances of bias mitigation across specific tasks are observed. We further explore the factors that may influence these phenomena, such as artifacts in image generation (e.g., blurry faces) or pre-existing biases in the original datasets.
LayoutFlow: Flow Matching for Layout Generation
Mar 27, 2024Finding a suitable layout represents a crucial task for diverse applications in graphic design. Motivated by simpler and smoother sampling trajectories, we explore the use of Flow Matching as an alternative to current diffusion-based layout generation models. Specifically, we propose LayoutFlow, an efficient flow-based model capable of generating high-quality layouts. Instead of progressively denoising the elements of a noisy layout, our method learns to gradually move, or flow, the elements of an initial sample until it reaches its final prediction. In addition, we employ a conditioning scheme that allows us to handle various generation tasks with varying degrees of conditioning with a single model. Empirically, LayoutFlow performs on par with state-of-the-art models while being significantly faster.
Multimodal Color Recommendation in Vector Graphic Documents
Aug 08, 2023



Color selection plays a critical role in graphic document design and requires sufficient consideration of various contexts. However, recommending appropriate colors which harmonize with the other colors and textual contexts in documents is a challenging task, even for experienced designers. In this study, we propose a multimodal masked color model that integrates both color and textual contexts to provide text-aware color recommendation for graphic documents. Our proposed model comprises self-attention networks to capture the relationships between colors in multiple palettes, and cross-attention networks that incorporate both color and CLIP-based text representations. Our proposed method primarily focuses on color palette completion, which recommends colors based on the given colors and text. Additionally, it is applicable for another color recommendation task, full palette generation, which generates a complete color palette corresponding to the given text. Experimental results demonstrate that our proposed approach surpasses previous color palette completion methods on accuracy, color distribution, and user experience, as well as full palette generation methods concerning color diversity and similarity to the ground truth palettes.
Toward Verifiable and Reproducible Human Evaluation for Text-to-Image Generation
Apr 04, 2023



Human evaluation is critical for validating the performance of text-to-image generative models, as this highly cognitive process requires deep comprehension of text and images. However, our survey of 37 recent papers reveals that many works rely solely on automatic measures (e.g., FID) or perform poorly described human evaluations that are not reliable or repeatable. This paper proposes a standardized and well-defined human evaluation protocol to facilitate verifiable and reproducible human evaluation in future works. In our pilot data collection, we experimentally show that the current automatic measures are incompatible with human perception in evaluating the performance of the text-to-image generation results. Furthermore, we provide insights for designing human evaluation experiments reliably and conclusively. Finally, we make several resources publicly available to the community to facilitate easy and fast implementations.
Towards Flexible Multi-modal Document Models
Mar 31, 2023Creative workflows for generating graphical documents involve complex inter-related tasks, such as aligning elements, choosing appropriate fonts, or employing aesthetically harmonious colors. In this work, we attempt at building a holistic model that can jointly solve many different design tasks. Our model, which we denote by FlexDM, treats vector graphic documents as a set of multi-modal elements, and learns to predict masked fields such as element type, position, styling attributes, image, or text, using a unified architecture. Through the use of explicit multi-task learning and in-domain pre-training, our model can better capture the multi-modal relationships among the different document fields. Experimental results corroborate that our single FlexDM is able to successfully solve a multitude of different design tasks, while achieving performance that is competitive with task-specific and costly baselines.