 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRegion-Wise Correspondence Prediction between Manga Line Art Images
Sep 11, 2025



Understanding region-wise correspondence between manga line art images is a fundamental task in manga processing, enabling downstream applications such as automatic line art colorization and in-between frame generation. However, this task remains largely unexplored, especially in realistic scenarios without pre-existing segmentation or annotations. In this paper, we introduce a novel and practical task: predicting region-wise correspondence between raw manga line art images without any pre-existing labels or masks. To tackle this problem, we divide each line art image into a set of patches and propose a Transformer-based framework that learns patch-level similarities within and across images. We then apply edge-aware clustering and a region matching algorithm to convert patch-level predictions into coherent region-level correspondences. To support training and evaluation, we develop an automatic annotation pipeline and manually refine a subset of the data to construct benchmark datasets. Experiments on multiple datasets demonstrate that our method achieves high patch-level accuracy (e.g., 96.34%) and generates consistent region-level correspondences, highlighting its potential for real-world manga applications.
ColorGPT: Leveraging Large Language Models for Multimodal Color Recommendation
Aug 12, 2025Colors play a crucial role in the design of vector graphic documents by enhancing visual appeal, facilitating communication, improving usability, and ensuring accessibility. In this context, color recommendation involves suggesting appropriate colors to complete or refine a design when one or more colors are missing or require alteration. Traditional methods often struggled with these challenges due to the complex nature of color design and the limited data availability. In this study, we explored the use of pretrained Large Language Models (LLMs) and their commonsense reasoning capabilities for color recommendation, raising the question: Can pretrained LLMs serve as superior designers for color recommendation tasks? To investigate this, we developed a robust, rigorously validated pipeline, ColorGPT, that was built by systematically testing multiple color representations and applying effective prompt engineering techniques. Our approach primarily targeted color palette completion by recommending colors based on a set of given colors and accompanying context. Moreover, our method can be extended to full palette generation, producing an entire color palette corresponding to a provided textual description. Experimental results demonstrated that our LLM-based pipeline outperformed existing methods in terms of color suggestion accuracy and the distribution of colors in the color palette completion task. For the full palette generation task, our approach also yielded improvements in color diversity and similarity compared to current techniques.
Exploring Palette based Color Guidance in Diffusion Models
Aug 12, 2025With the advent of diffusion models, Text-to-Image (T2I) generation has seen substantial advancements. Current T2I models allow users to specify object colors using linguistic color names, and some methods aim to personalize color-object association through prompt learning. However, existing models struggle to provide comprehensive control over the color schemes of an entire image, especially for background elements and less prominent objects not explicitly mentioned in prompts. This paper proposes a novel approach to enhance color scheme control by integrating color palettes as a separate guidance mechanism alongside prompt instructions. We investigate the effectiveness of palette guidance by exploring various palette representation methods within a diffusion-based image colorization framework. To facilitate this exploration, we construct specialized palette-text-image datasets and conduct extensive quantitative and qualitative analyses. Our results demonstrate that incorporating palette guidance significantly improves the model's ability to generate images with desired color schemes, enabling a more controlled and refined colorization process.
Multimodal Color Recommendation in Vector Graphic Documents
Aug 08, 2023



Color selection plays a critical role in graphic document design and requires sufficient consideration of various contexts. However, recommending appropriate colors which harmonize with the other colors and textual contexts in documents is a challenging task, even for experienced designers. In this study, we propose a multimodal masked color model that integrates both color and textual contexts to provide text-aware color recommendation for graphic documents. Our proposed model comprises self-attention networks to capture the relationships between colors in multiple palettes, and cross-attention networks that incorporate both color and CLIP-based text representations. Our proposed method primarily focuses on color palette completion, which recommends colors based on the given colors and text. Additionally, it is applicable for another color recommendation task, full palette generation, which generates a complete color palette corresponding to the given text. Experimental results demonstrate that our proposed approach surpasses previous color palette completion methods on accuracy, color distribution, and user experience, as well as full palette generation methods concerning color diversity and similarity to the ground truth palettes.
Color Recommendation for Vector Graphic Documents based on Multi-Palette Representation
Sep 22, 2022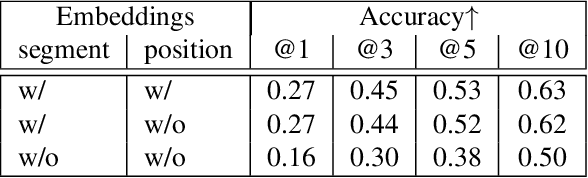
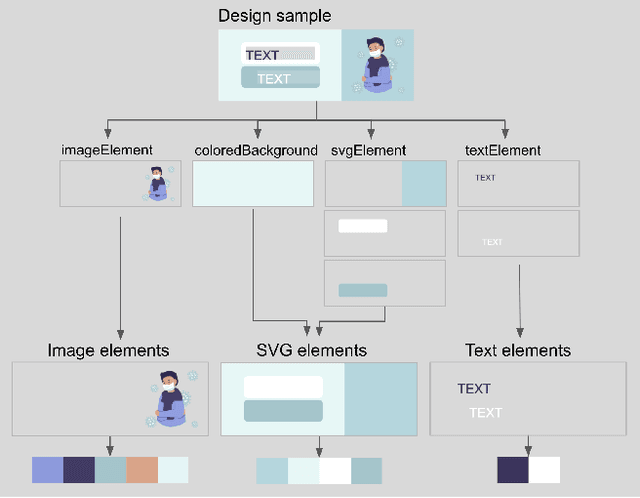
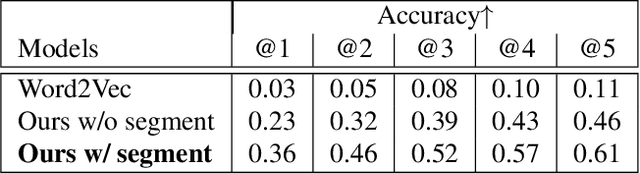
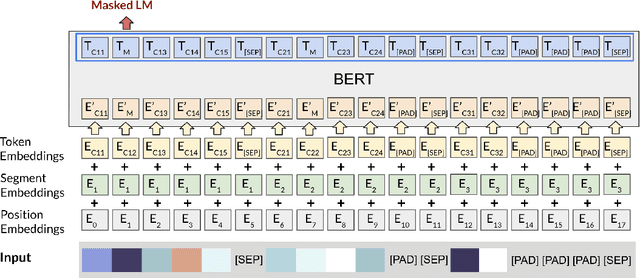
Vector graphic documents present multiple visual elements, such as images, shapes, and texts. Choosing appropriate colors for multiple visual elements is a difficult but crucial task for both amateurs and professional designers. Instead of creating a single color palette for all elements, we extract multiple color palettes from each visual element in a graphic document, and then combine them into a color sequence. We propose a masked color model for color sequence completion and recommend the specified colors based on color context in multi-palette with high probability. We train the model and build a color recommendation system on a large-scale dataset of vector graphic documents. The proposed color recommendation method outperformed other state-of-the-art methods by both quantitative and qualitative evaluations on color prediction and our color recommendation system received positive feedback from professional designers in an interview study.