 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Reverse Causal Framework to Mitigate Spurious Correlations for Debiasing Scene Graph Generation
May 29, 2025Existing two-stage Scene Graph Generation (SGG) frameworks typically incorporate a detector to extract relationship features and a classifier to categorize these relationships; therefore, the training paradigm follows a causal chain structure, where the detector's inputs determine the classifier's inputs, which in turn influence the final predictions. However, such a causal chain structure can yield spurious correlations between the detector's inputs and the final predictions, i.e., the prediction of a certain relationship may be influenced by other relationships. This influence can induce at least two observable biases: tail relationships are predicted as head ones, and foreground relationships are predicted as background ones; notably, the latter bias is seldom discussed in the literature. To address this issue, we propose reconstructing the causal chain structure into a reverse causal structure, wherein the classifier's inputs are treated as the confounder, and both the detector's inputs and the final predictions are viewed as causal variables. Specifically, we term the reconstructed causal paradigm as the Reverse causal Framework for SGG (RcSGG). RcSGG initially employs the proposed Active Reverse Estimation (ARE) to intervene on the confounder to estimate the reverse causality, \ie the causality from final predictions to the classifier's inputs. Then, the Maximum Information Sampling (MIS) is suggested to enhance the reverse causality estimation further by considering the relationship information. Theoretically, RcSGG can mitigate the spurious correlations inherent in the SGG framework, subsequently eliminating the induced biases. Comprehensive experiments on popular benchmarks and diverse SGG frameworks show the state-of-the-art mean recall rate.
A Conic Transformation Approach for Solving the Perspective-Three-Point Problem
Apr 02, 2025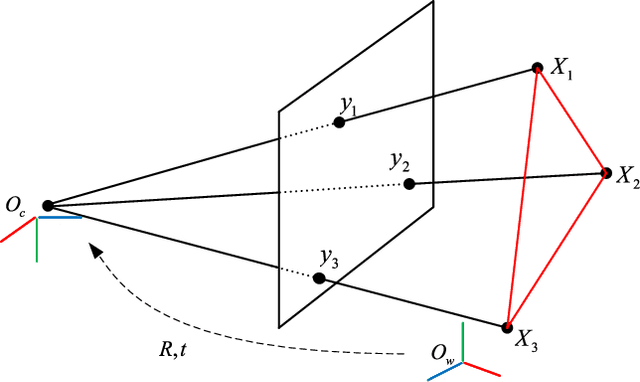
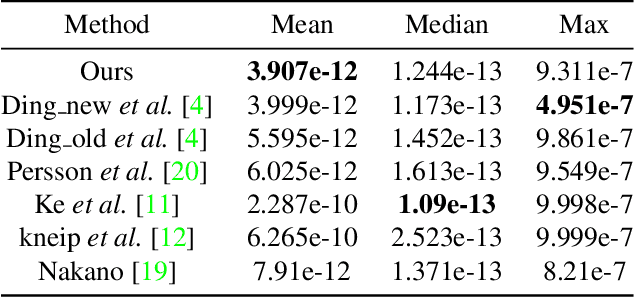
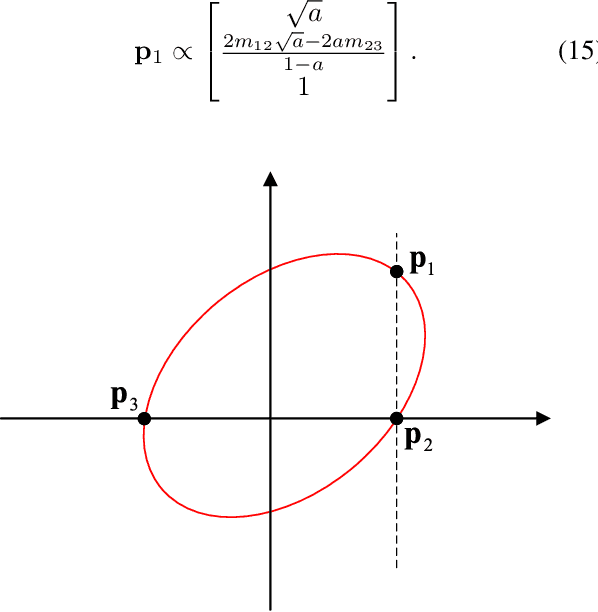
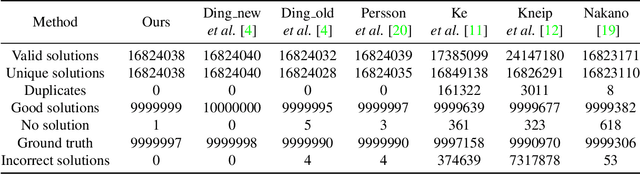
We propose a conic transformation method to solve the Perspective-Three-Point (P3P) problem. In contrast to the current state-of-the-art solvers, which formulate the P3P problem by intersecting two conics and constructing a degenerate conic to find the intersection, our approach builds upon a new formulation based on a transformation that maps the two conics to a new coordinate system, where one of the conics becomes a standard parabola in a canonical form. This enables expressing one variable in terms of the other variable, and as a consequence, substantially simplifies the problem of finding the conic intersection. Moreover, the polynomial coefficients are fast to compute, and we only need to determine the real-valued intersection points, which avoids the requirement of using computationally expensive complex arithmetic. While the current state-of-the-art methods reduce the conic intersection problem to solving a univariate cubic equation, our approach, despite resulting in a quartic equation, is still faster thanks to this new simplified formulation. Extensive evaluations demonstrate that our method achieves higher speed while maintaining robustness and stability comparable to state-of-the-art methods.
An End-to-End Depth-Based Pipeline for Selfie Image Rectification
Dec 26, 2024



Portraits or selfie images taken from a close distance typically suffer from perspective distortion. In this paper, we propose an end-to-end deep learning-based rectification pipeline to mitigate the effects of perspective distortion. We learn to predict the facial depth by training a deep CNN. The estimated depth is utilized to adjust the camera-to-subject distance by moving the camera farther, increasing the camera focal length, and reprojecting the 3D image features to the new perspective. The reprojected features are then fed to an inpainting module to fill in the missing pixels. We leverage a differentiable renderer to enable end-to-end training of our depth estimation and feature extraction nets to improve the rectified outputs. To boost the results of the inpainting module, we incorporate an auxiliary module to predict the horizontal movement of the camera which decreases the area that requires hallucination of challenging face parts such as ears. Unlike previous works, we process the full-frame input image at once without cropping the subject's face and processing it separately from the rest of the body, eliminating the need for complex post-processing steps to attach the face back to the subject's body. To train our network, we utilize the popular game engine Unreal Engine to generate a large synthetic face dataset containing various subjects, head poses, expressions, eyewear, clothes, and lighting. Quantitative and qualitative results show that our rectification pipeline outperforms previous methods, and produces comparable results with a time-consuming 3D GAN-based method while being more than 260 times faster.
GS-Pose: Cascaded Framework for Generalizable Segmentation-based 6D Object Pose Estimation
Mar 15, 2024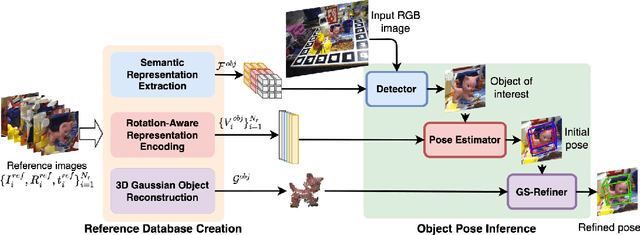
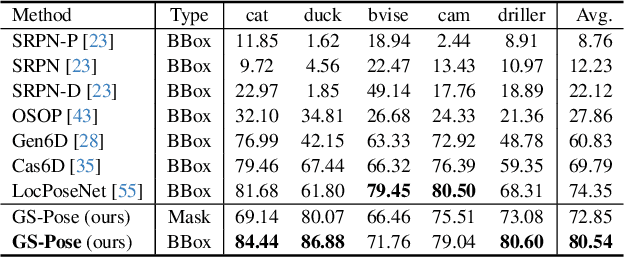
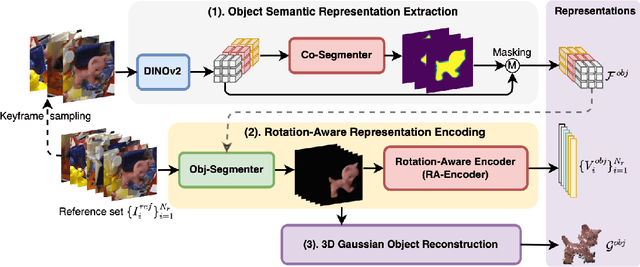
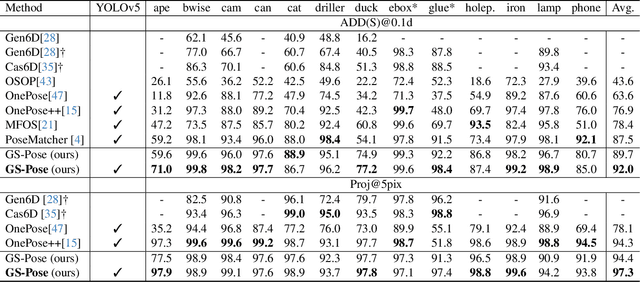
This paper introduces GS-Pose, an end-to-end framework for locating and estimating the 6D pose of objects. GS-Pose begins with a set of posed RGB images of a previously unseen object and builds three distinct representations stored in a database. At inference, GS-Pose operates sequentially by locating the object in the input image, estimating its initial 6D pose using a retrieval approach, and refining the pose with a render-and-compare method. The key insight is the application of the appropriate object representation at each stage of the process. In particular, for the refinement step, we utilize 3D Gaussian splatting, a novel differentiable rendering technique that offers high rendering speed and relatively low optimization time. Off-the-shelf toolchains and commodity hardware, such as mobile phones, can be used to capture new objects to be added to the database. Extensive evaluations on the LINEMOD and OnePose-LowTexture datasets demonstrate excellent performance, establishing the new state-of-the-art. Project page: https://dingdingcai.github.io/gs-pose.
Ray Launching-Based Computation of Exact Paths with Noisy Dense Point Clouds
Mar 11, 2024



Point clouds have been a recent interest for ray tracing-based radio channel characterization, as sensors such as RGB-D cameras and laser scanners can be utilized to generate an accurate virtual copy of a physical environment. In this paper, a novel ray launching algorithm is presented, which operates directly on noisy point clouds acquired from sensor data. It produces coarse paths that are further refined to exact paths consisting of reflections and diffractions. A commercial ray tracing tool is utilized as the baseline for validating the simulated paths. A significant majority of the baseline paths is found. The robustness to noise is examined by artificially applying noise along the normal vector of each point. It is observed that the proposed method is capable of adapting to noise and finds similar paths compared to the baseline path trajectories with noisy point clouds. This is prevalent especially if the normal vectors of the points are estimated accurately. Lastly, a simulation is performed with a reconstructed point cloud and compared against channel measurements and the baseline paths. The resulting paths demonstrate similarity with the baseline path trajectories and exhibit an analogous pattern to the aggregated impulse response extracted from the measurements. Code available at https://github.com/nvaara/NimbusRT
A Ray Launching Approach for Computing Exact Paths with Point Clouds
Feb 21, 2024



Ray tracing is a deterministic method that produces propagation paths between a transmitter and a receiver. The simulation accuracy is significantly influenced by the environment details. One way to capture the environment with great precision is the utilization of depth sensors and cameras. Such reconstructed environment is in the form of a point cloud. However, utilizing such data directly in ray tracing, a key aspect on vision-aided wireless communications, often involves a significant trade-off between accuracy and execution time. In this paper, we propose an open source novel and fast point cloud-based ray launching algorithm that produces exact paths, which provide a good basis for accurate modeling of radio channel characteristics. In experiments, preliminary validation of the ray tracer output is obtained with the aid of a commercial ray tracer.
Unbiased Scene Graph Generation via Two-stage Causal Modeling
Jul 11, 2023Despite the impressive performance of recent unbiased Scene Graph Generation (SGG) methods, the current debiasing literature mainly focuses on the long-tailed distribution problem, whereas it overlooks another source of bias, i.e., semantic confusion, which makes the SGG model prone to yield false predictions for similar relationships. In this paper, we explore a debiasing procedure for the SGG task leveraging causal inference. Our central insight is that the Sparse Mechanism Shift (SMS) in causality allows independent intervention on multiple biases, thereby potentially preserving head category performance while pursuing the prediction of high-informative tail relationships. However, the noisy datasets lead to unobserved confounders for the SGG task, and thus the constructed causal models are always causal-insufficient to benefit from SMS. To remedy this, we propose Two-stage Causal Modeling (TsCM) for the SGG task, which takes the long-tailed distribution and semantic confusion as confounders to the Structural Causal Model (SCM) and then decouples the causal intervention into two stages. The first stage is causal representation learning, where we use a novel Population Loss (P-Loss) to intervene in the semantic confusion confounder. The second stage introduces the Adaptive Logit Adjustment (AL-Adjustment) to eliminate the long-tailed distribution confounder to complete causal calibration learning. These two stages are model agnostic and thus can be used in any SGG model that seeks unbiased predictions. Comprehensive experiments conducted on the popular SGG backbones and benchmarks show that our TsCM can achieve state-of-the-art performance in terms of mean recall rate. Furthermore, TsCM can maintain a higher recall rate than other debiasing methods, which indicates that our method can achieve a better tradeoff between head and tail relationships.
Toward Verifiable and Reproducible Human Evaluation for Text-to-Image Generation
Apr 04, 2023



Human evaluation is critical for validating the performance of text-to-image generative models, as this highly cognitive process requires deep comprehension of text and images. However, our survey of 37 recent papers reveals that many works rely solely on automatic measures (e.g., FID) or perform poorly described human evaluations that are not reliable or repeatable. This paper proposes a standardized and well-defined human evaluation protocol to facilitate verifiable and reproducible human evaluation in future works. In our pilot data collection, we experimentally show that the current automatic measures are incompatible with human perception in evaluating the performance of the text-to-image generation results. Furthermore, we provide insights for designing human evaluation experiments reliably and conclusively. Finally, we make several resources publicly available to the community to facilitate easy and fast implementations.
MSDA: Monocular Self-supervised Domain Adaptation for 6D Object Pose Estimation
Feb 14, 2023
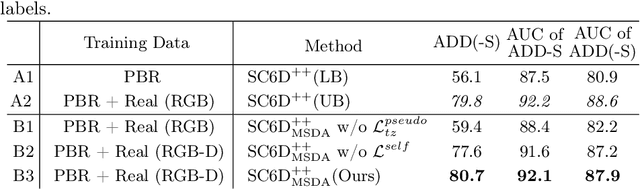

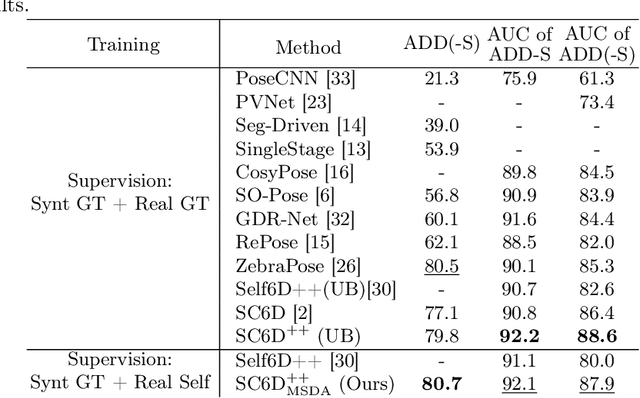
Acquiring labeled 6D poses from real images is an expensive and time-consuming task. Though massive amounts of synthetic RGB images are easy to obtain, the models trained on them suffer from noticeable performance degradation due to the synthetic-to-real domain gap. To mitigate this degradation, we propose a practical self-supervised domain adaptation approach that takes advantage of real RGB(-D) data without needing real pose labels. We first pre-train the model with synthetic RGB images and then utilize real RGB(-D) images to fine-tune the pre-trained model. The fine-tuning process is self-supervised by the RGB-based pose-aware consistency and the depth-guided object distance pseudo-label, which does not require the time-consuming online differentiable rendering. We build our domain adaptation method based on the recent pose estimator SC6D and evaluate it on the YCB-Video dataset. We experimentally demonstrate that our method achieves comparable performance against its fully-supervised counterpart while outperforming existing state-of-the-art approaches.
Sparse resultant based minimal solvers in computer vision and their connection with the action matrix
Jan 16, 2023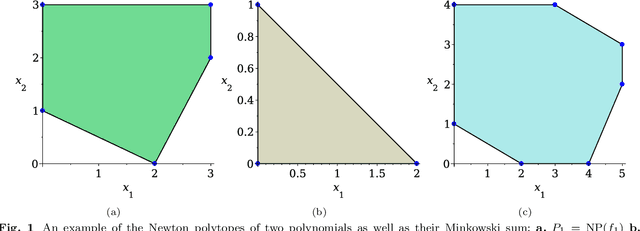
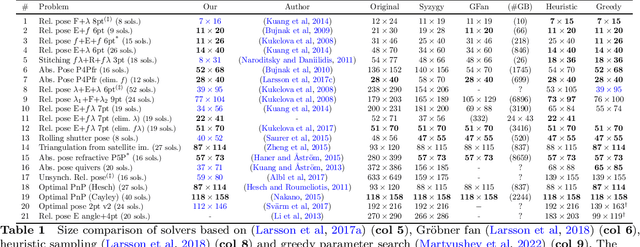
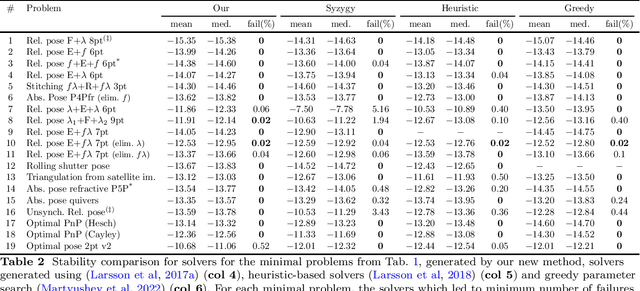
Many computer vision applications require robust and efficient estimation of camera geometry from a minimal number of input data measurements, ie, solving minimal problems in a RANSAC framework. Minimal problems are usually formulated as complex systems of polynomial equations. Many state-of-the-art efficient polynomial solvers are based on the action matrix method that has been automated and highly optimised in recent years. In this paper we explore the theory of sparse resultants for generating minimal solvers and propose a novel approach based on a using an extra polynomial with a special form. We show that for some camera geometry problems our extra polynomial-based method leads to smaller and more stable solvers than the state-of-the-art Gr\"obner basis-based solvers. The proposed method can be fully automated and incorporated into existing tools for automatic generation of efficient polynomial solvers. It provides a competitive alternative to popular Gr\"obner basis-based methods for minimal problems in computer vision. Additionally, we study the conditions under which the minimal solvers generated by the state-of-the-art action matrix-based methods and the proposed extra polynomial resultant-based method, are equivalent. Specifically we consider a step-by-step comparison between the approaches based on the action matrix and the sparse resultant, followed by a set of substitutions, which would lead to equivalent minimal solvers.