 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOP2GS: Object-Aware 3D Gaussian Splatting with Dual-Opacity Primitives
May 19, 20263D Gaussian Splatting (3DGS) provides an explicit and efficient scene representation, but its primitives lack inherent object-level identity, hindering downstream tasks such as open-vocabulary scene understanding. Existing methods typically address this by either distilling high-dimensional feature embeddings into Gaussians or by lifting 2D mask labels into 3D via heuristic refinement. However, feature-based approaches incur heavy storage and decoding overhead, while lifting-based pipelines remain vulnerable to label contamination: Gaussians necessary for appearance reconstruction often receive incorrect object labels during 2D-to-3D projection. We propose OP2GS, an object-aware Gaussian representation that augments each primitive with an explicit instance identity and a dedicated instance opacity $σ^{*}$ for object-mask rendering. The original opacity $σ$ remains responsible for visual reconstruction, while $σ^{*}$ models whether a Gaussian should contribute to a particular object mask. This dual-opacity formulation decouples visual existence from instance occupancy: mislabeled Gaussians can remain available for image rendering while becoming transparent in the object-mask branch. To learn this representation, we introduce a random object loss that optimizes the 1D instance occupancy field using the standard transmittance-based visibility of 3DGS. Semantic descriptors are then attached at the object level through multi-view aggregation, eliminating per-Gaussian feature storage. Compared with feature-training approaches, OP2GS achieves competitive open-vocabulary performance while significantly reducing computational overhead. Compared with training-free pipelines, it leverages physically consistent occupancy learning to resolve visibility ambiguities.
An End-to-End Depth-Based Pipeline for Selfie Image Rectification
Dec 26, 2024



Portraits or selfie images taken from a close distance typically suffer from perspective distortion. In this paper, we propose an end-to-end deep learning-based rectification pipeline to mitigate the effects of perspective distortion. We learn to predict the facial depth by training a deep CNN. The estimated depth is utilized to adjust the camera-to-subject distance by moving the camera farther, increasing the camera focal length, and reprojecting the 3D image features to the new perspective. The reprojected features are then fed to an inpainting module to fill in the missing pixels. We leverage a differentiable renderer to enable end-to-end training of our depth estimation and feature extraction nets to improve the rectified outputs. To boost the results of the inpainting module, we incorporate an auxiliary module to predict the horizontal movement of the camera which decreases the area that requires hallucination of challenging face parts such as ears. Unlike previous works, we process the full-frame input image at once without cropping the subject's face and processing it separately from the rest of the body, eliminating the need for complex post-processing steps to attach the face back to the subject's body. To train our network, we utilize the popular game engine Unreal Engine to generate a large synthetic face dataset containing various subjects, head poses, expressions, eyewear, clothes, and lighting. Quantitative and qualitative results show that our rectification pipeline outperforms previous methods, and produces comparable results with a time-consuming 3D GAN-based method while being more than 260 times faster.
BS3D: Building-scale 3D Reconstruction from RGB-D Images
Jan 03, 2023



Various datasets have been proposed for simultaneous localization and mapping (SLAM) and related problems. Existing datasets often include small environments, have incomplete ground truth, or lack important sensor data, such as depth and infrared images. We propose an easy-to-use framework for acquiring building-scale 3D reconstruction using a consumer depth camera. Unlike complex and expensive acquisition setups, our system enables crowd-sourcing, which can greatly benefit data-hungry algorithms. Compared to similar systems, we utilize raw depth maps for odometry computation and loop closure refinement which results in better reconstructions. We acquire a building-scale 3D dataset (BS3D) and demonstrate its value by training an improved monocular depth estimation model. As a unique experiment, we benchmark visual-inertial odometry methods using both color and active infrared images.
LSD$_2$ - Joint Denoising and Deblurring of Short and Long Exposure Images with Convolutional Neural Networks
Nov 23, 2018
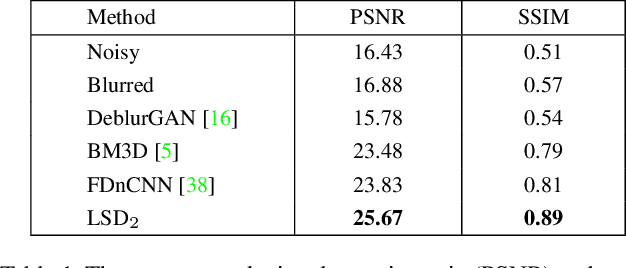

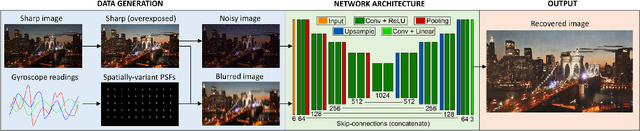
This paper addresses the challenging problem of acquiring high-quality photographs with handheld smartphone cameras in low-light imaging conditions. We propose an approach based on capturing pairs of short and long exposure images in rapid succession and fusing them into a single high-quality photograph using a convolutional neural network. The network input consists of a pair of images, where the short exposure image is typically noisy and has poor colors due to low lighting and the long exposure image is susceptible to motion blur when the camera or scene objects are moving. The network is trained using a combination of real and simulated data and we propose a novel approach for generating realistic synthetic short-long exposure image pairs. Our approach is the first one to address the joint denoising and deblurring problem using deep networks. It outperforms the existing denoising and deblurring methods in this task and allows to produce good images in extremely challenging conditions. Our source code, pretrained models and data will be made publicly available to facilitate future research.
Inertial-aided Motion Deblurring with Deep Networks
Oct 01, 2018
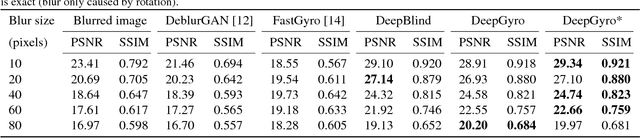


We propose an inertial-aided deblurring method that incorporates gyroscope measurements into a convolutional neural network (CNN). With the help of inertial measurements, it can handle extremely strong and spatially-variant motion blur. At the same time, the image data is used to overcome the limitations of gyro-based blur estimation. To train our network, we also introduce a novel way of generating realistic training data using the gyroscope. The evaluation shows a clear improvement in visual quality over the state-of-the-art while achieving real-time performance. Furthermore, the method is shown to improve the performance of existing feature detectors and descriptors against the motion blur.
Fast Motion Deblurring for Feature Detection and Matching Using Inertial Measurements
May 22, 2018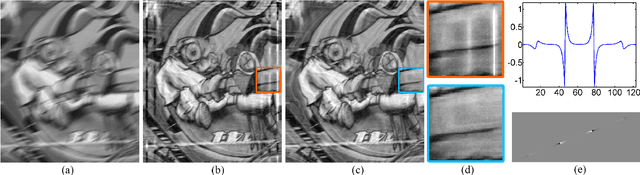
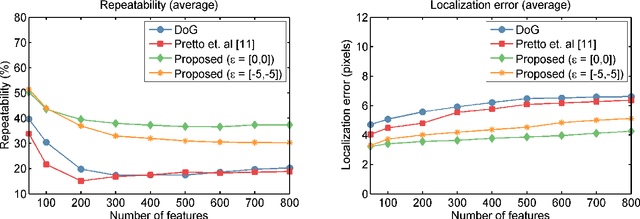

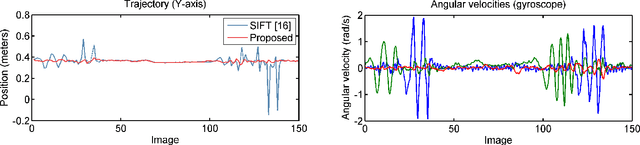
Many computer vision and image processing applications rely on local features. It is well-known that motion blur decreases the performance of traditional feature detectors and descriptors. We propose an inertial-based deblurring method for improving the robustness of existing feature detectors and descriptors against the motion blur. Unlike most deblurring algorithms, the method can handle spatially-variant blur and rolling shutter distortion. Furthermore, it is capable of running in real-time contrary to state-of-the-art algorithms. The limitations of inertial-based blur estimation are taken into account by validating the blur estimates using image data. The evaluation shows that when the method is used with traditional feature detector and descriptor, it increases the number of detected keypoints, provides higher repeatability and improves the localization accuracy. We also demonstrate that such features will lead to more accurate and complete reconstructions when used in the application of 3D visual reconstruction.
Inertial-Based Scale Estimation for Structure from Motion on Mobile Devices
Aug 11, 2017
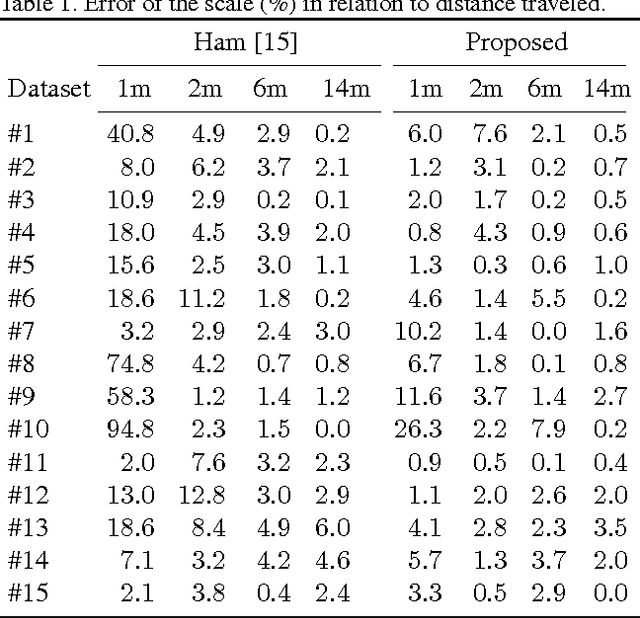

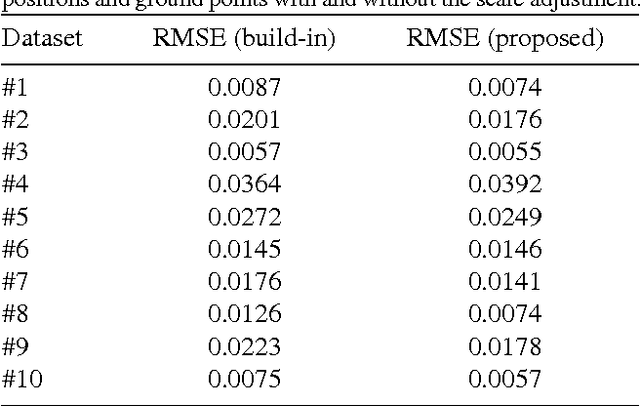
Structure from motion algorithms have an inherent limitation that the reconstruction can only be determined up to the unknown scale factor. Modern mobile devices are equipped with an inertial measurement unit (IMU), which can be used for estimating the scale of the reconstruction. We propose a method that recovers the metric scale given inertial measurements and camera poses. In the process, we also perform a temporal and spatial alignment of the camera and the IMU. Therefore, our solution can be easily combined with any existing visual reconstruction software. The method can cope with noisy camera pose estimates, typically caused by motion blur or rolling shutter artifacts, via utilizing a Rauch-Tung-Striebel (RTS) smoother. Furthermore, the scale estimation is performed in the frequency domain, which provides more robustness to inaccurate sensor time stamps and noisy IMU samples than the previously used time domain representation. In contrast to previous methods, our approach has no parameters that need to be tuned for achieving a good performance. In the experiments, we show that the algorithm outperforms the state-of-the-art in both accuracy and convergence speed of the scale estimate. The accuracy of the scale is around $1\%$ from the ground truth depending on the recording. We also demonstrate that our method can improve the scale accuracy of the Project Tango's build-in motion tracking.