 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDepth2Pose: A Pose-Based Benchmark for Monocular Depth Estimation without Ground-Truth Depth
May 19, 2026Monocular depth estimation has improved significantly in recent years, driven by increasingly powerful models and large-scale training data. Predicted depth is increasingly used as an input signal for downstream tasks such as Structure-from-Motion (SfM), visual localization, and SLAM. However, monocular depth estimators (MDEs) are still primarily evaluated in terms of depth accuracy. Standard metrics aggregate errors globally and may not reflect the usefulness of depth for downstream geometric tasks. We therefore propose Depth2Pose, a framework for evaluating MDEs in the context of downstream tasks. By combining depth predictions with feature correspondences in depth-aware geometric solvers, we use relative camera pose estimation accuracy as a task-driven proxy for depth quality. Traditional benchmarks require dense ground truth in the form of per-pixel depth, which is expensive to obtain. In contrast, our formulation requires only camera poses, which can be estimated efficiently, e.g., using Structure-from-Motion pipelines. As a result, our framework can be applied to scenes where ground-truth depth is difficult to obtain, for example due to large scene scale or heavy occlusions (e.g., vegetated environments). Leveraging this, we introduce the D2P dataset, which contains challenging scenes outside the distribution of commonly used training data. We show that methods performing well under standard depth error metrics on existing benchmarks also perform well under our pose-based metric when evaluated on the same datasets, but do not necessarily generalize to our more challenging dataset. Finally, we provide a simple and extensible evaluation framework. The dataset and code are available at kocurvik.github.io/depth2pose.
Privacy-Preserving Structureless Visual Localization via Image Obfuscation
Apr 13, 2026Visual localization is the task of estimating the camera pose of an image relative to a scene representation. In practice, visual localization systems are often cloud-based. Naturally, this raises privacy concerns in terms of revealing private details through the images sent to the server or through the representations stored on the server. Privacy-preserving localization aims to avoid such leakage of private details. However, the resulting localization approaches are significantly more complex, slower, and less accurate than their non-privacy-preserving counterparts. In this paper, we consider structureless localization methods in the context of privacy preservation. Structureless methods represent the scene through a set of reference images with known camera poses and intrinsics. In contrast to existing methods proposing representations that are as privacy-preserving as possible, we study a simple image obfuscation approach based on common image operations, e.g., replacing RGB images with (semantic) segmentations. We show that existing structureless pipelines do not need any special adjustments, as modern feature matchers can match obfuscated images out of the box. The results are easy-to-implement pipelines that can ensure both the privacy of the query images and the scene representations. Detailed experiments on multiple datasets show that the resulting methods achieve state-of-the-art pose accuracy for privacy-preserving approaches.
Are Minimal Radial Distortion Solvers Really Necessary for Relative Pose Estimation?
May 01, 2025Estimating the relative pose between two cameras is a fundamental step in many applications such as Structure-from-Motion. The common approach to relative pose estimation is to apply a minimal solver inside a RANSAC loop. Highly efficient solvers exist for pinhole cameras. Yet, (nearly) all cameras exhibit radial distortion. Not modeling radial distortion leads to (significantly) worse results. However, minimal radial distortion solvers are significantly more complex than pinhole solvers, both in terms of run-time and implementation efforts. This paper compares radial distortion solvers with two simple-to-implement approaches that do not use minimal radial distortion solvers: The first approach combines an efficient pinhole solver with sampled radial undistortion parameters, where the sampled parameters are used for undistortion prior to applying the pinhole solver. The second approach uses a state-of-the-art neural network to estimate the distortion parameters rather than sampling them from a set of potential values. Extensive experiments on multiple datasets, and different camera setups, show that complex minimal radial distortion solvers are not necessary in practice. We discuss under which conditions a simple sampling of radial undistortion parameters is preferable over calibrating cameras using a learning-based prior approach. Code and newly created benchmark for relative pose estimation under radial distortion are available at https://github.com/kocurvik/rdnet.
A Guide to Structureless Visual Localization
Apr 24, 2025Visual localization algorithms, i.e., methods that estimate the camera pose of a query image in a known scene, are core components of many applications, including self-driving cars and augmented / mixed reality systems. State-of-the-art visual localization algorithms are structure-based, i.e., they store a 3D model of the scene and use 2D-3D correspondences between the query image and 3D points in the model for camera pose estimation. While such approaches are highly accurate, they are also rather inflexible when it comes to adjusting the underlying 3D model after changes in the scene. Structureless localization approaches represent the scene as a database of images with known poses and thus offer a much more flexible representation that can be easily updated by adding or removing images. Although there is a large amount of literature on structure-based approaches, there is significantly less work on structureless methods. Hence, this paper is dedicated to providing the, to the best of our knowledge, first comprehensive discussion and comparison of structureless methods. Extensive experiments show that approaches that use a higher degree of classical geometric reasoning generally achieve higher pose accuracy. In particular, approaches based on classical absolute or semi-generalized relative pose estimation outperform very recent methods based on pose regression by a wide margin. Compared with state-of-the-art structure-based approaches, the flexibility of structureless methods comes at the cost of (slightly) lower pose accuracy, indicating an interesting direction for future work.
Three-view Focal Length Recovery From Homographies
Jan 13, 2025



In this paper, we propose a novel approach for recovering focal lengths from three-view homographies. By examining the consistency of normal vectors between two homographies, we derive new explicit constraints between the focal lengths and homographies using an elimination technique. We demonstrate that three-view homographies provide two additional constraints, enabling the recovery of one or two focal lengths. We discuss four possible cases, including three cameras having an unknown equal focal length, three cameras having two different unknown focal lengths, three cameras where one focal length is known, and the other two cameras have equal or different unknown focal lengths. All the problems can be converted into solving polynomials in one or two unknowns, which can be efficiently solved using Sturm sequence or hidden variable technique. Evaluation using both synthetic and real data shows that the proposed solvers are both faster and more accurate than methods relying on existing two-view solvers. The code and data are available on https://github.com/kocurvik/hf
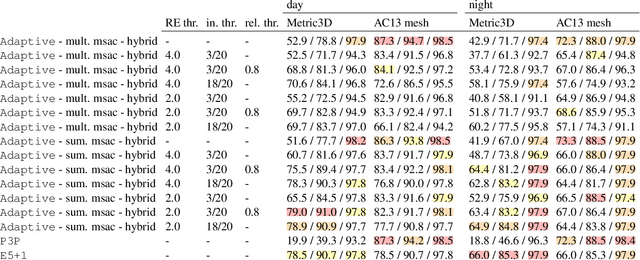
Fixing the Scale and Shift in Monocular Depth For Camera Pose Estimation
Jan 13, 2025



Recent advances in monocular depth prediction have led to significantly improved depth prediction accuracy. In turn, this enables various applications to use such depth predictions. In this paper, we propose a novel framework for estimating the relative pose between two cameras from point correspondences with associated monocular depths. Since depth predictions are typically defined up to an unknown scale and shift parameter, our solvers jointly estimate both scale and shift parameters together with the camera pose. We derive efficient solvers for three cases: (1) two calibrated cameras, (2) two uncalibrated cameras with an unknown but shared focal length, and (3) two uncalibrated cameras with unknown and different focal lengths. Experiments on synthetic and real data, including experiments with depth maps estimated by 11 different depth predictors, show the practical viability of our solvers. Compared to prior work, our solvers achieve state-of-the-art results on two large-scale, real-world datasets. The source code is available at https://github.com/yaqding/pose_monodepth
Are Minimal Radial Distortion Solvers Necessary for Relative Pose Estimation?
Oct 08, 2024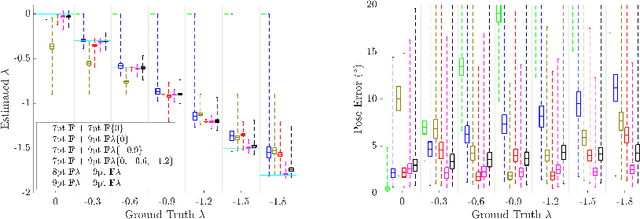
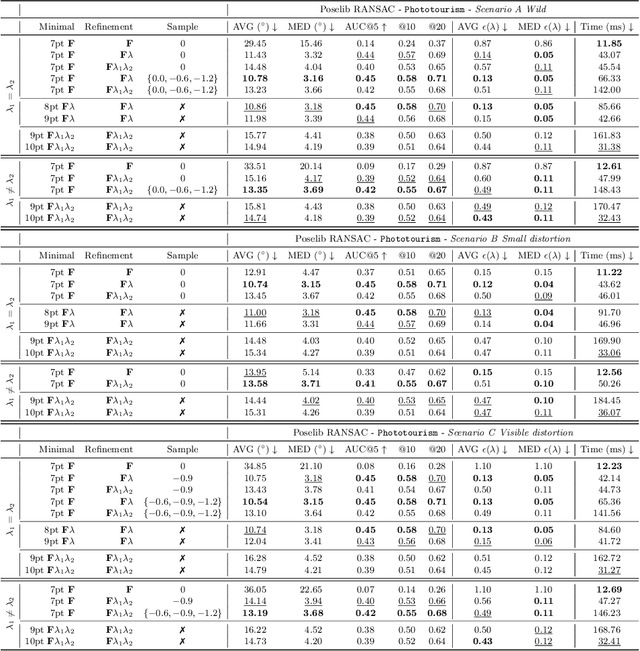
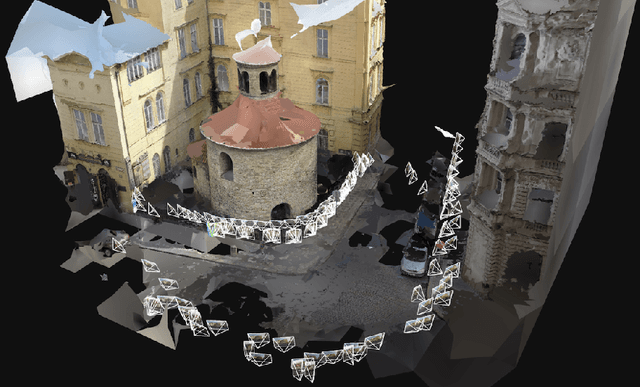
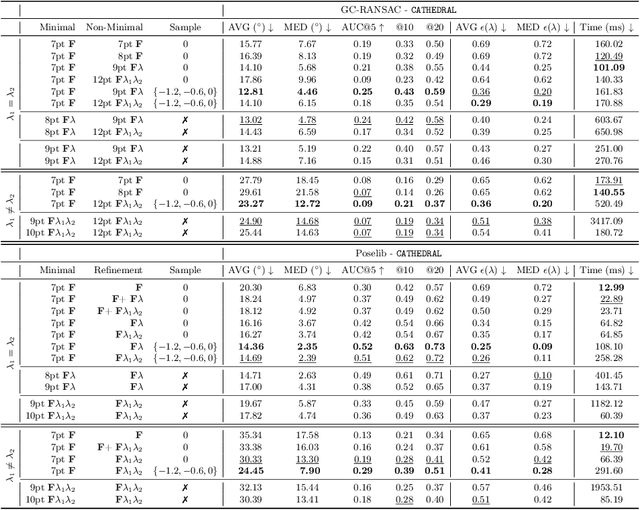
Estimating the relative pose between two cameras is a fundamental step in many applications such as Structure-from-Motion. The common approach to relative pose estimation is to apply a minimal solver inside a RANSAC loop. Highly efficient solvers exist for pinhole cameras. Yet, (nearly) all cameras exhibit radial distortion. Not modeling radial distortion leads to (significantly) worse results. However, minimal radial distortion solvers are significantly more complex than pinhole solvers, both in terms of run-time and implementation efforts. This paper compares radial distortion solvers with a simple-to-implement approach that combines an efficient pinhole solver with sampled radial distortion parameters. Extensive experiments on multiple datasets and RANSAC variants show that this simple approach performs similarly or better than the most accurate minimal distortion solvers at faster run-times while being significantly more accurate than faster non-minimal solvers. We clearly show that complex radial distortion solvers are not necessary in practice. Code and benchmark are available at https://github.com/kocurvik/rd.
Combining Absolute and Semi-Generalized Relative Poses for Visual Localization
Sep 21, 2024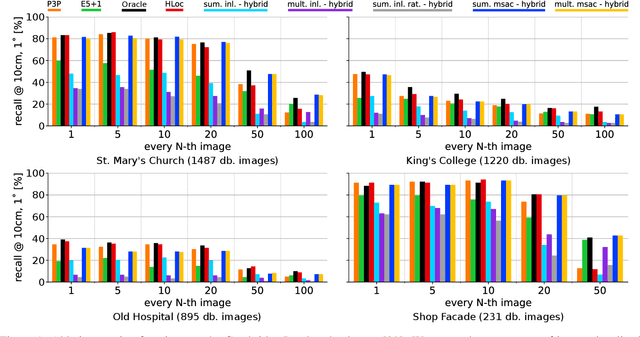

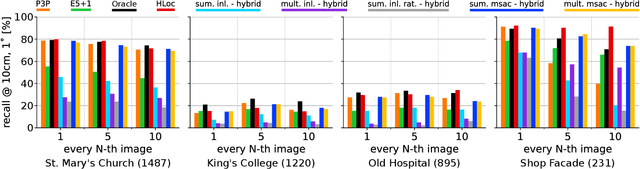
Visual localization is the problem of estimating the camera pose of a given query image within a known scene. Most state-of-the-art localization approaches follow the structure-based paradigm and use 2D-3D matches between pixels in a query image and 3D points in the scene for pose estimation. These approaches assume an accurate 3D model of the scene, which might not always be available, especially if only a few images are available to compute the scene representation. In contrast, structure-less methods rely on 2D-2D matches and do not require any 3D scene model. However, they are also less accurate than structure-based methods. Although one prior work proposed to combine structure-based and structure-less pose estimation strategies, its practical relevance has not been shown. We analyze combining structure-based and structure-less strategies while exploring how to select between poses obtained from 2D-2D and 2D-3D matches, respectively. We show that combining both strategies improves localization performance in multiple practically relevant scenarios.
Obfuscation Based Privacy Preserving Representations are Recoverable Using Neighborhood Information
Sep 17, 2024



Rapid growth in the popularity of AR/VR/MR applications and cloud-based visual localization systems has given rise to an increased focus on the privacy of user content in the localization process. This privacy concern has been further escalated by the ability of deep neural networks to recover detailed images of a scene from a sparse set of 3D or 2D points and their descriptors - the so-called inversion attacks. Research on privacy-preserving localization has therefore focused on preventing these inversion attacks on both the query image keypoints and the 3D points of the scene map. To this end, several geometry obfuscation techniques that lift points to higher-dimensional spaces, i.e., lines or planes, or that swap coordinates between points % have been proposed. In this paper, we point to a common weakness of these obfuscations that allows to recover approximations of the original point positions under the assumption of known neighborhoods. We further show that these neighborhoods can be computed by learning to identify descriptors that co-occur in neighborhoods. Extensive experiments show that our approach for point recovery is practically applicable to all existing geometric obfuscation schemes. Our results show that these schemes should not be considered privacy-preserving, even though they are claimed to be privacy-preserving. Code will be available at \url{https://github.com/kunalchelani/RecoverPointsNeighborhood}.
WildGaussians: 3D Gaussian Splatting in the Wild
Jul 11, 2024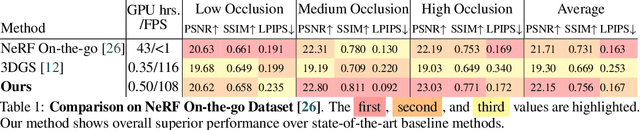
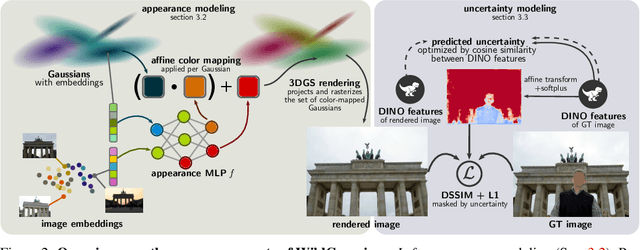
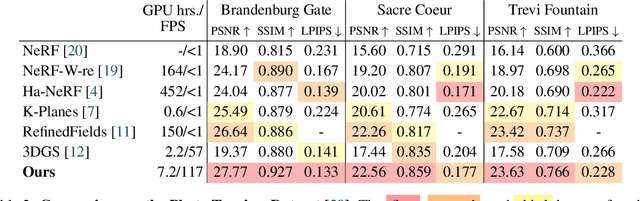

While the field of 3D scene reconstruction is dominated by NeRFs due to their photorealistic quality, 3D Gaussian Splatting (3DGS) has recently emerged, offering similar quality with real-time rendering speeds. However, both methods primarily excel with well-controlled 3D scenes, while in-the-wild data - characterized by occlusions, dynamic objects, and varying illumination - remains challenging. NeRFs can adapt to such conditions easily through per-image embedding vectors, but 3DGS struggles due to its explicit representation and lack of shared parameters. To address this, we introduce WildGaussians, a novel approach to handle occlusions and appearance changes with 3DGS. By leveraging robust DINO features and integrating an appearance modeling module within 3DGS, our method achieves state-of-the-art results. We demonstrate that WildGaussians matches the real-time rendering speed of 3DGS while surpassing both 3DGS and NeRF baselines in handling in-the-wild data, all within a simple architectural framework.